TweetNLP: Twitter Natural Language Processing
A short overview of Natural Language Processing tools and utilities developed by Prof. Noah Smith, CMU and his team to analyze Twitter data.
Twitter data has recently been one of the most favorite dataset for Natural Language Processing (NLP) researchers. Besides its magnanimous size, Twitter data has other unique qualities as well – it comprises of real-life conversations, uniform length (140 characters), rich variety, and real-time data stream. Advanced analytics on Twitter data needs one to go beyond the words and parse sentences into syntactic representations to develop a better contextual understanding of the tweet content. This can now be done conveniently through the tools developed by Prof. Noah Smith and his team at Carnegie Mellon University.
 Prof. Noah Smith’s informal research group (commonly known as “Noah’s ARK”) at the Language Technologies Institute, School of Computer Science, CMU has developed the following NLP tools/utilities to analyze Twitter data:
Prof. Noah Smith’s informal research group (commonly known as “Noah’s ARK”) at the Language Technologies Institute, School of Computer Science, CMU has developed the following NLP tools/utilities to analyze Twitter data:
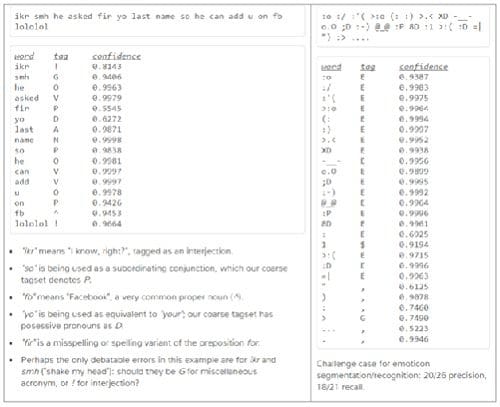
Part-of-Speech Tagging: A fast and robust Java-based tokenizer and part-of-speech tagger for tweets that breaks down the tweet into a sequence of tokens (which roughly corresponds to “words”) and identifies the part-of-speech (such as interjection, proper noun, preposition, subordinate conjunction, etc.) that the token belongs to. Importantly, the tool also identifies misspellings and corrects them before deciding which part-of-speech the token would belong to.
Source Code is available here on Github. TweeboParser: A dependency parser for English tweets, TweeboParser is trained on a subset of Tweebank dataset. Given a tweet, TweeboParser predicts its syntactic structure, represented by unlabeled dependencies. Since a tweet often contains more than one utterance, the output of TweeboParser will often be a multi-rooted graph over the tweet.
Sample output of TweeoParser:
TweeboParser: A dependency parser for English tweets, TweeboParser is trained on a subset of Tweebank dataset. Given a tweet, TweeboParser predicts its syntactic structure, represented by unlabeled dependencies. Since a tweet often contains more than one utterance, the output of TweeboParser will often be a multi-rooted graph over the tweet.
Sample output of TweeoParser:
 Parser (along with pre-trained models and annotated data) is available here on SourceForge.
Parser (along with pre-trained models and annotated data) is available here on SourceForge.
Twitter Word Clusters: From over 56 million English tweets (837 million tokens), 1000 hierarchical clusters over 217 thousand words. The source data comprises of sample of 100k tweet/day from 9/10/2008 to 8/14/2012.
Sample clusters: If interested, you can check out the HTML version of all the clusters.
If interested, you can check out the HTML version of all the clusters.
For more details, refer to the following recent publications:
Improved Part-of-Speech Tagging for Online Conversational Text with Word Clusters
Olutobi Owoputi, Brendan O’Connor, Chris Dyer, Kevin Gimpel, Nathan Schneider and Noah A. Smith. In Proceedings of NAACL 2013.
A Dependency Parser for Tweets Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith. In Proceedings of EMNLP 2014.
Related:
 Prof. Noah Smith’s informal research group (commonly known as “Noah’s ARK”) at the Language Technologies Institute, School of Computer Science, CMU has developed the following NLP tools/utilities to analyze Twitter data:
Prof. Noah Smith’s informal research group (commonly known as “Noah’s ARK”) at the Language Technologies Institute, School of Computer Science, CMU has developed the following NLP tools/utilities to analyze Twitter data:
Part-of-Speech Tagging: A fast and robust Java-based tokenizer and part-of-speech tagger for tweets that breaks down the tweet into a sequence of tokens (which roughly corresponds to “words”) and identifies the part-of-speech (such as interjection, proper noun, preposition, subordinate conjunction, etc.) that the token belongs to. Importantly, the tool also identifies misspellings and corrects them before deciding which part-of-speech the token would belong to.
Source Code is available here on Github.
 TweeboParser: A dependency parser for English tweets, TweeboParser is trained on a subset of Tweebank dataset. Given a tweet, TweeboParser predicts its syntactic structure, represented by unlabeled dependencies. Since a tweet often contains more than one utterance, the output of TweeboParser will often be a multi-rooted graph over the tweet.
Sample output of TweeoParser:
TweeboParser: A dependency parser for English tweets, TweeboParser is trained on a subset of Tweebank dataset. Given a tweet, TweeboParser predicts its syntactic structure, represented by unlabeled dependencies. Since a tweet often contains more than one utterance, the output of TweeboParser will often be a multi-rooted graph over the tweet.
Sample output of TweeoParser:
 Parser (along with pre-trained models and annotated data) is available here on SourceForge.
Parser (along with pre-trained models and annotated data) is available here on SourceForge.
Twitter Word Clusters: From over 56 million English tweets (837 million tokens), 1000 hierarchical clusters over 217 thousand words. The source data comprises of sample of 100k tweet/day from 9/10/2008 to 8/14/2012.
Sample clusters:
 If interested, you can check out the HTML version of all the clusters.
If interested, you can check out the HTML version of all the clusters.
For more details, refer to the following recent publications:
Improved Part-of-Speech Tagging for Online Conversational Text with Word Clusters
Olutobi Owoputi, Brendan O’Connor, Chris Dyer, Kevin Gimpel, Nathan Schneider and Noah A. Smith. In Proceedings of NAACL 2013.
A Dependency Parser for Tweets Lingpeng Kong, Nathan Schneider, Swabha Swayamdipta, Archna Bhatia, Chris Dyer, and Noah A. Smith. In Proceedings of EMNLP 2014.
Related: