Interview: Joseph Babcock, Netflix on Genie, Lipstick, and Other In-house Developed Tools
We discuss role of analytics in content acquisition, data architecture at Netflix, organizational structure, and open-source tools from Netflix.
Twitter Handle: @hey_anmol
 Joseph Babcock is currently a Senior Data Scientist working on Discovery & Personalization algorithms and data processing at Netflix.
Joseph Babcock is currently a Senior Data Scientist working on Discovery & Personalization algorithms and data processing at Netflix.
Before Netflix, he studied computational biology at The Johns Hopkins University School of Medicine, where his PhD research in the Department of Neuroscience employed machine learning models to predict adverse side-effects of drugs.
He also previously worked at Chicago-based Accretive Health as a Data Scientist, focusing on data related to patient billing and referrals.
First part of interview
Here is second part of my interview with him:
Anmol Rajpurohit: Q5. How does Data Science help Netflix in identifying inventory gaps? Does Discovery & Personalization team provide any inputs to Content Acquisition team?
Joseph Babcock: In a sense content acquisition is both a science and an art. While it is difficult to exactly pin down what makes a show a hit, we make extensive use of analytics in examining what our users are watching, and thus where we might want to prioritize our licensing in the future. Examples include building predictive models for popularity of upcoming titles, using expert tagging to assign metadata labels to content, and qualitative interview sessions conducted by our Consumer Sciences branch to link these empirical findings with feedback from our customers.
We also extensively track the on-site performance of our Original programming in conjunction with our marketing efforts to constantly refine our delivery of Netflix-produced content.
AR: Q6. What are the most common tools and technologies used at Netflix to manage Big Data?
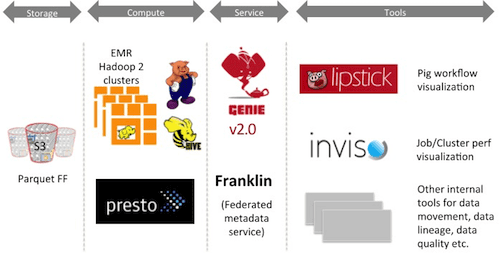
 JB: Our Big Data infrastructure is primarily built on top of Amazon Web Services (AWS), specifically the Simple Storage Service (S3) file system that backs our Hadoop cluster. Production ETL jobs are largely written in Pig, with Hive used for adhoc analyses and Presto for interactive analytics. We also maintain a Teradata cloud instance, which is the backend for many of our reporting tools such as Microstrategy and Tableau.
JB: Our Big Data infrastructure is primarily built on top of Amazon Web Services (AWS), specifically the Simple Storage Service (S3) file system that backs our Hadoop cluster. Production ETL jobs are largely written in Pig, with Hive used for adhoc analyses and Presto for interactive analytics. We also maintain a Teradata cloud instance, which is the backend for many of our reporting tools such as Microstrategy and Tableau.
Hadoop job submission is managed through a service developed in-house called Genie, which abstracts the details of cluster configuration when users submit jobs (it resembles submission of a POST command to a web server). Along with Genie, you can find many of our other Big Data tools on Github, such as Inviso (a central dashboard to visualize cluster load and debug job performance), S3mper (an S3 consistency monitor), Lipstick (a visual interface for Pig which we utilize extensively for sharing and analyzing data about these jobs), PigPen (a Clojure wrapper for Pig), and Surus (a collection of User Defined Functions (UDFs) developed for data science tasks such as model scoring and anomaly detection).
AR: Q7. At Netflix, data scientists are vertically aligned to different aspects of business, as opposed to a centralized model (such as Analytics Center of Excellence). What pros and cons do you see for such an organizational structure?
 JB: I think the pros of this approach are the ability to develop deep expertise in particular data types, whether it be external marketing feeds, server side impression data, search clicks, or playback logs. Each has its own nuances, and understanding these often becomes important in developing signals in our algorithms.
JB: I think the pros of this approach are the ability to develop deep expertise in particular data types, whether it be external marketing feeds, server side impression data, search clicks, or playback logs. Each has its own nuances, and understanding these often becomes important in developing signals in our algorithms.
As with any sort of specialization, the potential downside is lack of exposure to alternative areas that might provide unexpected inspiration, but I think our regular in-company seminars, all-hands meetings, and cross-team initiatives are effective means of socializing such learning across verticals.
AR: Q8. Netflix has a lot of in-house developed software that are now open-source. Can you describe the motivations behind the development of Genie, Lipstick and Quinto?
JB: The motivation is one of scale and self-enablement through automation. In the case of Genie, abstracting the details of job submission from a particular cluster configuration allows us to flexibly scale the resources brokering job submissions behind the scenes as demand for computational resources changes, and also helps tie together the increasingly heterogeneous tasks we are running (Hive, Pig, Spark, Presto, etc.) with a common architecture.

In the case of Lipstick and Quinto, these tools make auditing and debugging ETL jobs much more ‘self-service’, whereas in the past we might have to dig through Pig log files or write adhoc data quality checks. Automated and user-friendly interfaces like these tools increase our productivity to tackle ever-harder problems in processing and understanding our data.
Third part of the interview will be published soon.
Related:
 Joseph Babcock is currently a Senior Data Scientist working on Discovery & Personalization algorithms and data processing at Netflix.
Joseph Babcock is currently a Senior Data Scientist working on Discovery & Personalization algorithms and data processing at Netflix. Before Netflix, he studied computational biology at The Johns Hopkins University School of Medicine, where his PhD research in the Department of Neuroscience employed machine learning models to predict adverse side-effects of drugs.
He also previously worked at Chicago-based Accretive Health as a Data Scientist, focusing on data related to patient billing and referrals.
First part of interview
Here is second part of my interview with him:
Anmol Rajpurohit: Q5. How does Data Science help Netflix in identifying inventory gaps? Does Discovery & Personalization team provide any inputs to Content Acquisition team?
Joseph Babcock: In a sense content acquisition is both a science and an art. While it is difficult to exactly pin down what makes a show a hit, we make extensive use of analytics in examining what our users are watching, and thus where we might want to prioritize our licensing in the future. Examples include building predictive models for popularity of upcoming titles, using expert tagging to assign metadata labels to content, and qualitative interview sessions conducted by our Consumer Sciences branch to link these empirical findings with feedback from our customers.
We also extensively track the on-site performance of our Original programming in conjunction with our marketing efforts to constantly refine our delivery of Netflix-produced content.
AR: Q6. What are the most common tools and technologies used at Netflix to manage Big Data?
 JB: Our Big Data infrastructure is primarily built on top of Amazon Web Services (AWS), specifically the Simple Storage Service (S3) file system that backs our Hadoop cluster. Production ETL jobs are largely written in Pig, with Hive used for adhoc analyses and Presto for interactive analytics. We also maintain a Teradata cloud instance, which is the backend for many of our reporting tools such as Microstrategy and Tableau.
JB: Our Big Data infrastructure is primarily built on top of Amazon Web Services (AWS), specifically the Simple Storage Service (S3) file system that backs our Hadoop cluster. Production ETL jobs are largely written in Pig, with Hive used for adhoc analyses and Presto for interactive analytics. We also maintain a Teradata cloud instance, which is the backend for many of our reporting tools such as Microstrategy and Tableau.
Hadoop job submission is managed through a service developed in-house called Genie, which abstracts the details of cluster configuration when users submit jobs (it resembles submission of a POST command to a web server). Along with Genie, you can find many of our other Big Data tools on Github, such as Inviso (a central dashboard to visualize cluster load and debug job performance), S3mper (an S3 consistency monitor), Lipstick (a visual interface for Pig which we utilize extensively for sharing and analyzing data about these jobs), PigPen (a Clojure wrapper for Pig), and Surus (a collection of User Defined Functions (UDFs) developed for data science tasks such as model scoring and anomaly detection).
AR: Q7. At Netflix, data scientists are vertically aligned to different aspects of business, as opposed to a centralized model (such as Analytics Center of Excellence). What pros and cons do you see for such an organizational structure?
 JB: I think the pros of this approach are the ability to develop deep expertise in particular data types, whether it be external marketing feeds, server side impression data, search clicks, or playback logs. Each has its own nuances, and understanding these often becomes important in developing signals in our algorithms.
JB: I think the pros of this approach are the ability to develop deep expertise in particular data types, whether it be external marketing feeds, server side impression data, search clicks, or playback logs. Each has its own nuances, and understanding these often becomes important in developing signals in our algorithms.
As with any sort of specialization, the potential downside is lack of exposure to alternative areas that might provide unexpected inspiration, but I think our regular in-company seminars, all-hands meetings, and cross-team initiatives are effective means of socializing such learning across verticals.
AR: Q8. Netflix has a lot of in-house developed software that are now open-source. Can you describe the motivations behind the development of Genie, Lipstick and Quinto?
JB: The motivation is one of scale and self-enablement through automation. In the case of Genie, abstracting the details of job submission from a particular cluster configuration allows us to flexibly scale the resources brokering job submissions behind the scenes as demand for computational resources changes, and also helps tie together the increasingly heterogeneous tasks we are running (Hive, Pig, Spark, Presto, etc.) with a common architecture.
In the case of Lipstick and Quinto, these tools make auditing and debugging ETL jobs much more ‘self-service’, whereas in the past we might have to dig through Pig log files or write adhoc data quality checks. Automated and user-friendly interfaces like these tools increase our productivity to tackle ever-harder problems in processing and understanding our data.
Third part of the interview will be published soon.
Related: