A Statistical View of Deep Learning
A statistical overview of deep learning, with a focus on testing wide-held beliefs, highlighting statistical connections, and the unseen implications of deep learning. The post links to 6 articles covering a number of related topics.
By Shakir Mohamed, Google DeepMind.
Over the past 6 months, I've taken to writing a series of posts (one each month) on a statistical view of deep learning with two principal motivations in mind. The first was as a personal exercise to make concrete and to test the limits of the way that I think about, and use deep learning in my every day work. The second, was to highlight important statistical connections and implications of deep learning that I do not see being made in the popular courses, reviews and books on deep learning, but which are extremely important to keep in mind.
Post Links and Summary
Links to each post with a short summary and as a single PDF are collected here.
Recursive GLMs. We constructed a view of deep feedforward networks as a natural extension of generalised linear regression formed by recursive application of the the generalised linear form. Maximum likelihood was shown to be the underlying method for parameter learning.
Auto-encoders and Free energy. Denoising auto-encoders were shown to be a way of implemented an amortised inference in models with latent variables. Adding noise to the observations and denoising turns out not to be what we are interested in. Instead, we can add noise to the hidden variables, turning auto-encoders into deep generative models and providing one way of implementing variational inference.
Memory and Kernels. Where deep networks are archetypical parametric models, kernel machines are archetypical non-parametric models. We showed that these seemingly different approaches are very closely connected, being duals of each other. Their differences have interesting implications for our machine learning practice, and over time we will see these methods being used more closely together.
Recurrent Networks and Dynamical Systems. Whereas models with shared parameters that are recursively applied are called recurrent networks in deep learning, in statistics, models of this type are called state-space models or dynamical systems. Recurrent networks assume that the hidden states are deterministic, whereas state-space models have stochastic hidden states. They can easily be connected by maximum likelihood reasoning, and there are great deal of innovative models that can be exchanged between the two areas.

Equivalent models: recurrent networks and state-space models.
Generalisation and Regularisation. Maximum likelihood is not sufficient for the scalable and accurate deep learning we require and we can ameliorate this situation by using various forms of statistical regularisation. And thus, most deep learning now uses some form of MAP estimation. Using statistical reasoning, we can then reason about the limitations of MAP estimation, which will lead us to think about invariant MAP estimators wherefrom the connections to the natural gradient, minimum message length methods, and Bayesian inference emerges.
Contours showing the shrinkage effects of different priors.
What is Deep? As a closing post, it seemed appropriate to interrogate the key word that has been used throughout this series. Many people new to deep learning often ask what is deep, and this post characterises deep models as probabilistic hierarchical models where the hierarchical dependency is through the means of the random variables within the hierarchy. When using maximum likelihood or MAP we can recover familiar solutions. But other types of hierarchies can be considered as well, and have an important role to play and will emerge as we continue research.
Deep and Hierarchical models are abound in machine learning.
Combined PDF: I've created a combined PDF of the posts in case they are of interest. Find it here [SVDL.pdf]
Discussion
Each post is necessarily short since my aim was to test how concrete I could frame my thinking within around 1200 words (posts are on average 1500 words though). Thus there are many more discussions, references and connections that could have been added, and is the limitation of these posts. I do not explicitly discuss convolutional networks anywhere. Since convolution is a special linear operation we will not need any special reasoning to form a statistical view. What does require more reasoning is the statistical connections to pooling operations and something I'll hopefully cement in the future. The invariant MAP estimators discussed in part 5 show that you could get an update rule that will involve the inverse Fisher which is different from that obtained using the natural gradient, and is a connection that I was unable to establish directly. I did not provide many examples of the ways that popular deep and statistical methods can be combined. Kernel methods (in part 3) and deep learning can easily be combined by parameterising the kernel with a neural network, giving the best of both worlds. I have chosen to view dropout (in part 5) as a prior assumption that does not require inference, and connected this to spike-and-slab priors. But there are many other views that are complementary and valid for this, making a longer discussion of just this topic something for the future.
I have enjoyed this series, and it has been a wonderful exploration and fun to write. Thanks to the many people who have read, shared and sent me feedback. I do have a new series of posts to come: next time on neuroscience-inspired machine learning :)
Bio: Shakir Mohamed is a researcher in statistical machine learning and artificial intelligence, and currently a senior research scientist at Google DeepMind in London. Before that he was a CIFAR scholar with Nando de Freitas at the UBC. He has a PhD from University of Cambridge.
Original.
Related:
Over the past 6 months, I've taken to writing a series of posts (one each month) on a statistical view of deep learning with two principal motivations in mind. The first was as a personal exercise to make concrete and to test the limits of the way that I think about, and use deep learning in my every day work. The second, was to highlight important statistical connections and implications of deep learning that I do not see being made in the popular courses, reviews and books on deep learning, but which are extremely important to keep in mind.
Post Links and Summary
Links to each post with a short summary and as a single PDF are collected here.
Recursive GLMs. We constructed a view of deep feedforward networks as a natural extension of generalised linear regression formed by recursive application of the the generalised linear form. Maximum likelihood was shown to be the underlying method for parameter learning.
Auto-encoders and Free energy. Denoising auto-encoders were shown to be a way of implemented an amortised inference in models with latent variables. Adding noise to the observations and denoising turns out not to be what we are interested in. Instead, we can add noise to the hidden variables, turning auto-encoders into deep generative models and providing one way of implementing variational inference.
Memory and Kernels. Where deep networks are archetypical parametric models, kernel machines are archetypical non-parametric models. We showed that these seemingly different approaches are very closely connected, being duals of each other. Their differences have interesting implications for our machine learning practice, and over time we will see these methods being used more closely together.
Recurrent Networks and Dynamical Systems. Whereas models with shared parameters that are recursively applied are called recurrent networks in deep learning, in statistics, models of this type are called state-space models or dynamical systems. Recurrent networks assume that the hidden states are deterministic, whereas state-space models have stochastic hidden states. They can easily be connected by maximum likelihood reasoning, and there are great deal of innovative models that can be exchanged between the two areas.

Equivalent models: recurrent networks and state-space models.
Generalisation and Regularisation. Maximum likelihood is not sufficient for the scalable and accurate deep learning we require and we can ameliorate this situation by using various forms of statistical regularisation. And thus, most deep learning now uses some form of MAP estimation. Using statistical reasoning, we can then reason about the limitations of MAP estimation, which will lead us to think about invariant MAP estimators wherefrom the connections to the natural gradient, minimum message length methods, and Bayesian inference emerges.
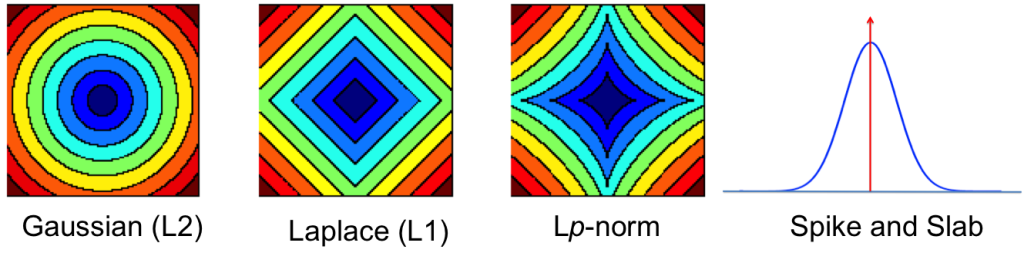
Contours showing the shrinkage effects of different priors.
What is Deep? As a closing post, it seemed appropriate to interrogate the key word that has been used throughout this series. Many people new to deep learning often ask what is deep, and this post characterises deep models as probabilistic hierarchical models where the hierarchical dependency is through the means of the random variables within the hierarchy. When using maximum likelihood or MAP we can recover familiar solutions. But other types of hierarchies can be considered as well, and have an important role to play and will emerge as we continue research.
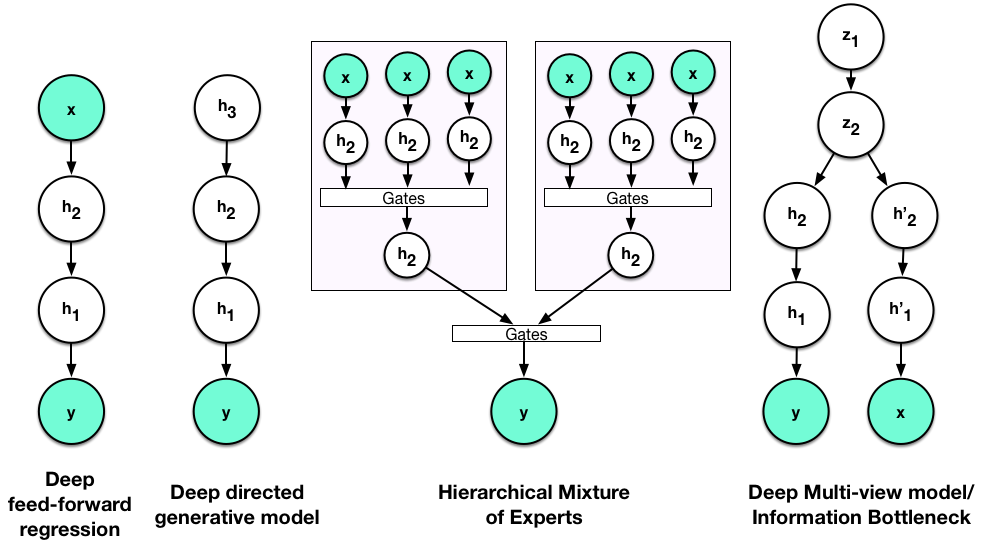
Deep and Hierarchical models are abound in machine learning.
Combined PDF: I've created a combined PDF of the posts in case they are of interest. Find it here [SVDL.pdf]
Discussion
Each post is necessarily short since my aim was to test how concrete I could frame my thinking within around 1200 words (posts are on average 1500 words though). Thus there are many more discussions, references and connections that could have been added, and is the limitation of these posts. I do not explicitly discuss convolutional networks anywhere. Since convolution is a special linear operation we will not need any special reasoning to form a statistical view. What does require more reasoning is the statistical connections to pooling operations and something I'll hopefully cement in the future. The invariant MAP estimators discussed in part 5 show that you could get an update rule that will involve the inverse Fisher which is different from that obtained using the natural gradient, and is a connection that I was unable to establish directly. I did not provide many examples of the ways that popular deep and statistical methods can be combined. Kernel methods (in part 3) and deep learning can easily be combined by parameterising the kernel with a neural network, giving the best of both worlds. I have chosen to view dropout (in part 5) as a prior assumption that does not require inference, and connected this to spike-and-slab priors. But there are many other views that are complementary and valid for this, making a longer discussion of just this topic something for the future.
I have enjoyed this series, and it has been a wonderful exploration and fun to write. Thanks to the many people who have read, shared and sent me feedback. I do have a new series of posts to come: next time on neuroscience-inspired machine learning :)
Bio: Shakir Mohamed is a researcher in statistical machine learning and artificial intelligence, and currently a senior research scientist at Google DeepMind in London. Before that he was a CIFAR scholar with Nando de Freitas at the UBC. He has a PhD from University of Cambridge.
Original.
Related: