Yahoo Releases the Largest-ever Machine Learning Dataset for Researchers
Are you interested in massive amounts of data for research? Yahoo has just released the largest-ever machine learning dataset to the research community.
By Suju Rajan, Yahoo.
Data is the lifeblood of research in machine learning. However, access to truly large-scale datasets is a privilege that has been traditionally reserved for machine learning researchers and data scientists working at large companies – and out of reach for most academic researchers.
Research scientists at Yahoo Labs have long enjoyed working on large-scale machine learning problems inspired by consumer-facing products. This has enabled us to advance the thinking in areas such as search ranking, computational advertising, information retrieval, and core machine learning. A key aspect of interest to the external research community has been the application of new algorithms and methodologies to production traffic and to large-scale datasets gathered from real products.
Today, we are proud to announce the public release of the largest-ever machine learning dataset to the research community. The dataset stands at a massive ~110B events (13.5TB uncompressed) of anonymized user-news item interaction data, collected by recording the user-news item interactions of about 20M users from February 2015 to May 2015.
The Yahoo News Feed dataset is a collection based on a sample of anonymized user interactions on the news feeds of several Yahoo properties, including the Yahoo homepage, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Movies, and Yahoo Real Estate.

The news feed on Yahoo’s homepage.
Our goals are to promote independent research in the fields of large-scale machine learning and recommender systems, and to help level the playing field between industrial and academic research. The dataset is available as part of the Yahoo Labs Webscope data-sharing program, which is a reference library of scientifically-useful datasets comprising anonymized user data for non-commercial use.
In addition to the interaction data, we are providing categorized demographic information (age range, gender, and generalized geographic data) for a subset of the anonymized users. On the item side, we are releasing the title, summary, and key-phrases of the pertinent news article. The interaction data is timestamped with the relevant local time and also contains partial information about the device on which the user accessed the news feeds, which allows for interesting work in contextual recommendation and temporal data mining.
The Personalization Science team at Yahoo Labs has had a ton of fun working on a full-scale version of the Yahoo News Feed dataset, which has sparked some compelling ideas (e.g. Birds, Apps, and Users: Scalable Factorization Machines and Science Powering Product and Personalization: Going Beyond Clicks) in the areas of behavior modeling, recommender systems, large-scale and distributed machine learning, ranking, online algorithms, content modeling, and time-series mining.
We hope that this data release will similarly inspire our fellow researchers, data scientists, and machine learning enthusiasts in academia, and help validate their models on an extensive, “real-world” dataset. We strongly believe that this dataset can become the benchmark for large-scale machine learning and recommender systems, and we look forward to hearing from the community about their applications of our data.
Happy (large-scale) machine learning in 2016!
Note on our approach to user privacy: Our users place their trust in us each and every day, and we work hard to earn that trust. We zealously protect our users’ privacy, and responsibly and transparently use and protect our users’ personal information. Accordingly, the dataset that we’re releasing as part of this project has been anonymized.
Related:
Data is the lifeblood of research in machine learning. However, access to truly large-scale datasets is a privilege that has been traditionally reserved for machine learning researchers and data scientists working at large companies – and out of reach for most academic researchers.
Research scientists at Yahoo Labs have long enjoyed working on large-scale machine learning problems inspired by consumer-facing products. This has enabled us to advance the thinking in areas such as search ranking, computational advertising, information retrieval, and core machine learning. A key aspect of interest to the external research community has been the application of new algorithms and methodologies to production traffic and to large-scale datasets gathered from real products.
Today, we are proud to announce the public release of the largest-ever machine learning dataset to the research community. The dataset stands at a massive ~110B events (13.5TB uncompressed) of anonymized user-news item interaction data, collected by recording the user-news item interactions of about 20M users from February 2015 to May 2015.
The Yahoo News Feed dataset is a collection based on a sample of anonymized user interactions on the news feeds of several Yahoo properties, including the Yahoo homepage, Yahoo News, Yahoo Sports, Yahoo Finance, Yahoo Movies, and Yahoo Real Estate.
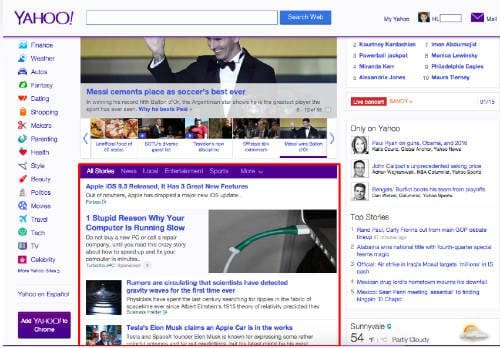
The news feed on Yahoo’s homepage.
Our goals are to promote independent research in the fields of large-scale machine learning and recommender systems, and to help level the playing field between industrial and academic research. The dataset is available as part of the Yahoo Labs Webscope data-sharing program, which is a reference library of scientifically-useful datasets comprising anonymized user data for non-commercial use.
In addition to the interaction data, we are providing categorized demographic information (age range, gender, and generalized geographic data) for a subset of the anonymized users. On the item side, we are releasing the title, summary, and key-phrases of the pertinent news article. The interaction data is timestamped with the relevant local time and also contains partial information about the device on which the user accessed the news feeds, which allows for interesting work in contextual recommendation and temporal data mining.
The Personalization Science team at Yahoo Labs has had a ton of fun working on a full-scale version of the Yahoo News Feed dataset, which has sparked some compelling ideas (e.g. Birds, Apps, and Users: Scalable Factorization Machines and Science Powering Product and Personalization: Going Beyond Clicks) in the areas of behavior modeling, recommender systems, large-scale and distributed machine learning, ranking, online algorithms, content modeling, and time-series mining.
We hope that this data release will similarly inspire our fellow researchers, data scientists, and machine learning enthusiasts in academia, and help validate their models on an extensive, “real-world” dataset. We strongly believe that this dataset can become the benchmark for large-scale machine learning and recommender systems, and we look forward to hearing from the community about their applications of our data.
Happy (large-scale) machine learning in 2016!
Note on our approach to user privacy: Our users place their trust in us each and every day, and we work hard to earn that trust. We zealously protect our users’ privacy, and responsibly and transparently use and protect our users’ personal information. Accordingly, the dataset that we’re releasing as part of this project has been anonymized.
Related: