Auto-Scaling scikit-learn with Spark
Databricks gives us an overview of the spark-sklearn library, which automatically and seamlessly distributes model tuning on a Spark cluster, without impacting workflow.
By Tim Hunter and Joseph Bradley, Databricks.
Data scientists often spend hours or days tuning models to get the highest accuracy. This tuning typically involves running a large number of independent Machine Learning (ML) tasks coded in Python or R. Following some work presented at Spark Summit Europe 2015, we are excited to release a library that dramatically simplifies the life of data scientists using Python. This library, published as spark-sklearn, automatically distributes the most repetitive tasks of model tuning on a Spark cluster, without impacting the workflow of data scientists:
- When used on a single machine, Spark can be used as a substitute to the default multithreading framework used by scikit-learn (Joblib).
- If a need comes to spread the work across multiple machines, no change is required in the code between the single-machine case and the cluster case.
Scale data science effortlessly
Python is one of the most popular programming languages for data exploration and data science, and this is in no small part due to high quality libraries such as Pandas for data exploration or scikit-learn for machine learning. Scikit-learn provides fast and robust implementations of standard ML algorithms such as clustering, classification, and regression.
Scikit-learn’s strength has typically been in the realm of computing on a single node, though. For some common scenarios, such as parameter tuning, a large number of small tasks can be run in parallel. These scenarios are perfect use cases for Spark.
We explored how to integrate Spark with scikit-learn, and the result is the spark-sklearn Python package. Spark-sklearn combines the strengths of Spark and scikit-learn with no changes to users’ code. It re-implements some components of scikit-learn that benefit the most from distributed computing. Users will find a Spark-based cross-validator class that is fully compatible with scikit-learn’s cross-validation tools. By swapping out a single class import, users can distribute cross-validation for their existing scikit-learn workflows.
Distribute tuning of Random Forests
Consider a classical example of identifying digits in images. Here are a few examples of images taken from the popular digits dataset, with their labels:
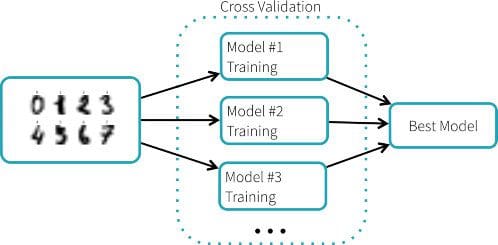
We are going to train a random forest classifier to recognize the digits. This classifier has a number of parameters to adjust, and there is no easy way to know which parameters work best, other than trying out many different combinations. Scikit-learn provides GridSearchCV, a search algorithm that explores many parameter settings automatically. GridSearchCV uses selection by cross-validation, illustrated below. Each parameter setting produces one model, and the best-performing model is selected.
The original code, using only scikit-learn, is as follows:
from sklearn import grid_search, datasets from sklearn.ensemble import RandomForestClassifier from sklearn.grid_search import GridSearchCV digits = datasets.load_digits() X, y = digits.data, digits.target param_grid = {"max_depth": [3, None], "max_features": [1, 3, 10], "min_samples_split": [1, 3, 10], "min_samples_leaf": [1, 3, 10], "bootstrap": [True, False], "criterion": ["gini", "entropy"], "n_estimators": [10, 20, 40, 80]} gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid) gs.fit(X, y)
The dataset is small (in the hundreds of kilobytes), but exploring all the combinations takes about 5 minutes on a single core. Spark-sklearn provides an alternative implementation of the cross-validation algorithm that distributes the workload on a Spark cluster. Each node runs the training algorithm using a local copy of the scikit-learn library, and reports the best model back to the master:
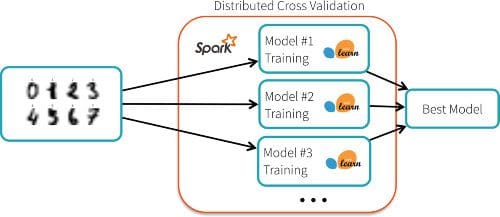
The code is the same as before, except for a one-line change:
from sklearn import grid_search, datasets from sklearn.ensemble import RandomForestClassifier # Use spark_sklearn’s grid search instead: from spark_sklearn import GridSearchCV digits = datasets.load_digits() X, y = digits.data, digits.target param_grid = {"max_depth": [3, None], "max_features": [1, 3, 10], "min_samples_split": [1, 3, 10], "min_samples_leaf": [1, 3, 10], "bootstrap": [True, False], "criterion": ["gini", "entropy"], "n_estimators": [10, 20, 40, 80]} gs = grid_search.GridSearchCV(RandomForestClassifier(), param_grid=param_grid) gs.fit(X, y)
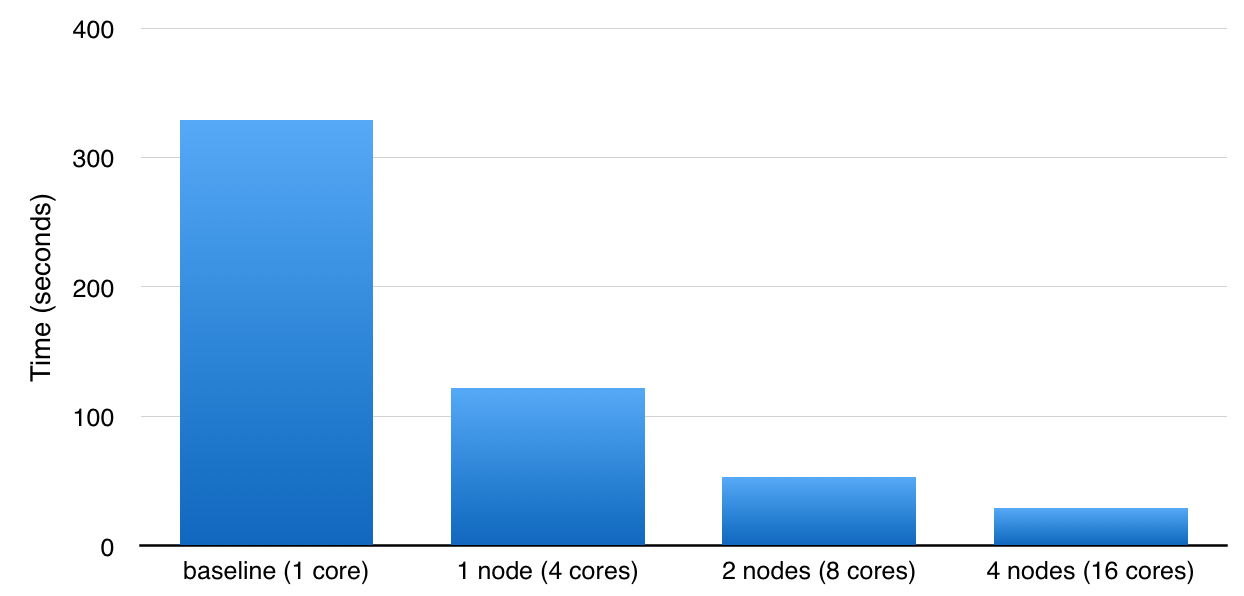
This example runs under 30 seconds on a 4-node cluster (which has 16 CPUs). For larger datasets and more parameter settings, the difference is even more dramatic.
Get started
If you would like to try out spark-sklearn yourself, it is available as a Spark package and as a Pypi library. To get started, check out this example notebook on Databricks.
In addition to distributing ML tasks in Python across a cluster, spark-sklearn provides additional tools to export data from Spark to python and vice-versa. You can find methods to convert Spark DataFrames to Pandas dataframes and numpy arrays. More details can be found in this Spark Summit Europe presentation and in the API documentation.
We welcome feedback and contributions to our open-source implementation on Github (Apache 2.0 license).
About: Databricks was founded by the team at UC Berkeley AMPLab that created and continues to drive Apache Spark. Their vision is to make big data simple for data scientists, engineers, developers, and business users alike.
Original. Reposted with permission.
Related: