5 More Machine Learning Projects You Can No Longer Overlook
There are a lot of popular machine learning projects out there, but many more that are not. Which of these are actively developed and worth checking out? Here is an offering of 5 such projects.
Last month's post "5 Machine Learning Projects You Can No Longer Overlook" was a well-received piece on 5 lesser-known machine learning projects in the Python ecosystem, and included deep learning libraries, along with auxiliary support, data cleaning, and automation tools. As such, we thought it may be worth doing a follow-up post, but broadening our scope this time.
This post will showcase 5 machine learning projects that you may not yet have heard of. This time, however, the projects will include those from across a number of different ecosystems and programming languages, as opposed to focusing solely on Python tools. You may find that, even if you have no requirement for any of these particular tools, inspecting their broad implementation details or their specific code may help in generating some ideas of your own. Like the previous iteration, there is no formal criteria for inclusion beyond projects that have caught my eye over time spent online, and the projects have Github repositories. Subjective, to be sure.
Here they are: 5 more machine learning projects you should consider having a look at. They are presented in no particular order, but are numbered for convenience, and because numbering things is where it's at.
Rusty Machine is machine learning in Rust. Rust, itself, is only about 6 years old, with development sponsored by Mozilla. For those unfamiliar with Rust, it is a systems language with similarities to C and C++, self-described as:
Rust is a systems programming language that runs blazingly fast, prevents segfaults, and guarantees thread safety.
Rusty Machine is actively developed, and currently supports a selection of learning techniques, including Linear Regression, Logistic Regression, K-Means Clustering, Neural Networks, Support Vector Machines, and more. The project is relatively new, and at this point leaves functionality such as cross-validation and data handling to the user. The project also has solid documentation.
Supporting data structures, such as vectors and matrices, come built-in. Perhaps familiarly, Rusty Machine provides a train and a predict function for each of its supported models, as a common interface to models. If you are a Rust user looking for a general purpose machine learning library, download Rusty Machine and give it a try.
2. scikit-image
scikit-image is image processing in Python for SciPy. Is scikit-image, itself, machine learning? Well, remember that this is a list of machine learning projects (nothing actually says they must perform machine learning), and recall that the previous post included support projects as well, such as data processing and preparation tools. scikit-image falls into this category. The project includes a number of image processing algorithms, such as point detection, filters, feature selection, and morphology.
This post from y-hat is a nice overview of image processing with scikit-image. The post also recognizes the importance of image processing in relation to machine learning:
Emphasizing important traits and diluting noisy ones is the backbone of good feature design. In the context of machine vision, this means that image preprocessing plays a huge role. Before extracting features from an image, it's extremely useful to be able to augment it so that aspects which are important to the machine learning task stand out.
Here's a quick example of using scikit-image to filter an image:
from skimage import data, io, filters image = data.coins() # or any NumPy array! edges = filters.sobel(image) io.imshow(edges) io.show()
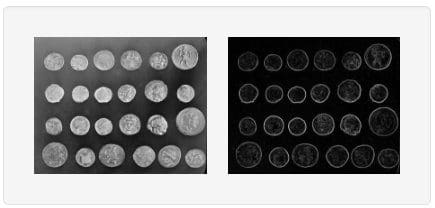
I would suggest the project documentation and the y-hat post as good starting points if interested in using scikit-image for image processing tasks.
NLP Compromise is written in Javascript, and does Natural Language Processing in the browser. It has a fully-documented API, is actively developed, and has an in-progress wiki promising some additional useful information as well.
NLP Compromise is very easy to both install and use. Here's a short set of examples:
let nlp = require('nlp_compromise'); // or nlp = window.nlp_compromise nlp.noun('dinosaur').pluralize(); // 'dinosaurs' nlp.verb('speak').conjugate(); // { past: 'spoke', // infinitive: 'speak', // gerund: 'speaking', // actor: 'speaker', // present: 'speaks', // future: 'will speak', // perfect: 'have spoken', // pluperfect: 'had spoken', // future_perfect: 'will have spoken' // } nlp.statement('She sells seashells').negate().text() // "She doesn't sell seashells" nlp.sentence('I fed the dog').replace('the [Noun]', 'the cat').text() // 'I fed the cat' nlp.text('Tony Hawk did a kickflip').people(); // [ Person { text: 'Tony Hawk' ..} ] nlp.noun('vacuum').article(); // 'a' nlp.person('Tony Hawk').pronoun(); // 'he'
The project repository has gathered a high number of stars on Github (nearly 6,000), and its adoption by a handful of downstream projects is also reassuring. NLP in the browser probably can't get any easier, or more lightweight.
4. Datatest
Now this is interesting. Datatest is test driven data wrangling, in Python.
From the project's documentation:
Datatest extends the standard library’s unittest package to provide testing tools for asserting data correctness.
Datatest has detailed documentation, and perhaps the best way to get an idea of what it is and how to use it is to check out an example from the documentation:
import datatest def setUpModule(): global subjectData subjectData = datatest.CsvSource('users.csv') class TestUserData(datatest.DataTestCase): def test_columns(self): self.assertDataColumns(required={'user_id', 'active'}) def test_user_id(self): def must_be_digit(x): # <- Helper function. return str(x).isdigit() self.assertDataSet('user_id', required=must_be_digit) def test_active(self): self.assertDataSet('active', required={'Y', 'N'}) if __name__ == '__main__': datatest.main()
You can check out the entire list of available assert methods here.
Datatest is a different way of looking at data wrangling and preparation. Given that so much of your time may be spent on this task, however, perhaps a new approach is worth checking out.
5. GoLearn

Adding to our collection of non-Python machine learning libraries and/or frameworks in the post, GoLearn is a general purpose machine learning library for Go.
Here is what GoLearn has to say about itself:
GoLearn is a 'batteries included' machine learning library for Go. Simplicity, paired with customisability, is the goal. We are in active development, and would love comments from users out in the wild.
Some good news for both users of Python who may be thinking of branching out, as well as for Go users looking to make the shift to machine learning, GoLearn implements the familiar Scikit-learn Fit/Predict interface, enabling fast estimator testing and swapping. It also allows for a smooth transition, and enables dedicated Go users to take advantage of all the Scikit-learn tutorial material out there without having to recreate the foundational practical machine learning concept instructions.
GoLearn is a mature enough project that it provides cross-validation and train/test splitting helper functions, which, if you recall, the relative newcomer Rusty Machine had not yet implemented. Looking to undertake some machine learning in Go, or looking for an excuse to try out the Go language? GoLearn might just be what you're after.
Related: