America’s Next Topic Model
Topic modeling is a a great way to get a bird's eye view on a large document collection using machine learning. Here are 3 ways to use open source Python tool Gensim to choose the best topic model.
By Lev Konstantinovskiy, RaRe Technologies.
"How to choose the best topic model?" is the #1 question on our community mailing list. At RaRe Technologies I manage the community for the Python open source topic modeling package gensim. As so many people are looking for the answer, we’ve recently released an updated gensim 0.13.1 incorporating several new exciting features which evaluate if your model is any good, helping you to select the best topic model.

What is Topic Modeling?
Topic modeling is a technique for taking some unstructured text and automatically extracting its common themes, using machine learning. It is a great way to get a bird's eye view on a large text collection.
A quick recap on what topic modeling does: a topic is a probability distribution over the vocabulary. For example, if we were to create three topics for the Harry Potter series of books manually, we might come up with something like this:
- (the Muggle topic) 50% “Muggle”, 25% “Dursey”, 10% “Privet”, 5% “Mudblood”...
- (the Voldemort topic) 65% “Voldemort”, 12% “Death”, 10% “Horcrux”, 5% “Snake”...
- (the Harry topic) 42% “Harry Potter”, 15% “Scar”, 7% “Quidditch”, 7% “Gryffindor”...
In the same way, we can represent individual documents as a probability distribution over topics. For example, Chapter 1 of Harry Potter book 1 introduces the Dursley family and has Dumbledore discuss Harry’s parent’s death. If we take this chapter to be a single document, it could be broken up into topics like this: 40% Muggle topic, 30% Voldemort topic, and the remaining 30% is the Harry topic.
Of course, we don’t want to extract the topics and document probabilities by hand like this. We want the machine to do it automatically using our unlabelled text collection as the only input. Because there is no document labeling nor human annotations, topic modeling an example of an unsupervised machine learning technique.
Another, more practical example would be breaking your internal company documents into topics, providing a bird's eye view of their contents for convenient visualization and browsing:
Latent Dirichlet Allocation = LDA
The most popular topic model in use today is Latent Dirichlet Allocation. To understand how this works, Edwin Chen’s blog post is a very good resource. This link has a nice repository of explanations of LDA, which might require a little mathematical background. This paper by David Blei is a good go-to as it sums up various types of topic models which have been developed to date.
If you want to get your hands dirty with some nice LDA and vector space code, the gensim tutorial is always handy.
Choosing the Best Topic Model: Coloring words
Once you have your topics the next step is to determine if they are any good or not. If they are, then you would simply go ahead and plug them into your collection browser or classifier. If not, maybe you should train the model a bit more or with different parameters.
One of the ways to analyze the model is to color document words depending on the topic they belong to. This feature was recently added to gensim by our 2016 Google Summer of Code student Bhargav. You can take a look at the Python code in this notebook. Figure 1 above is an example of this functionality from the original LDA paper by David Blei.
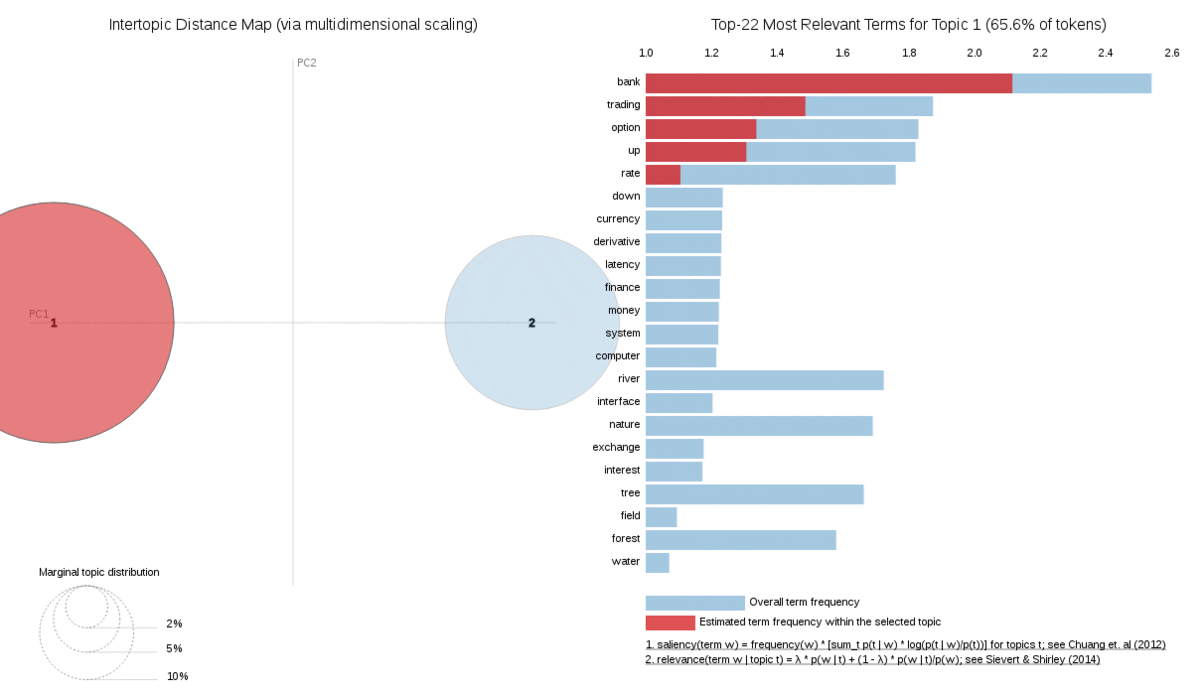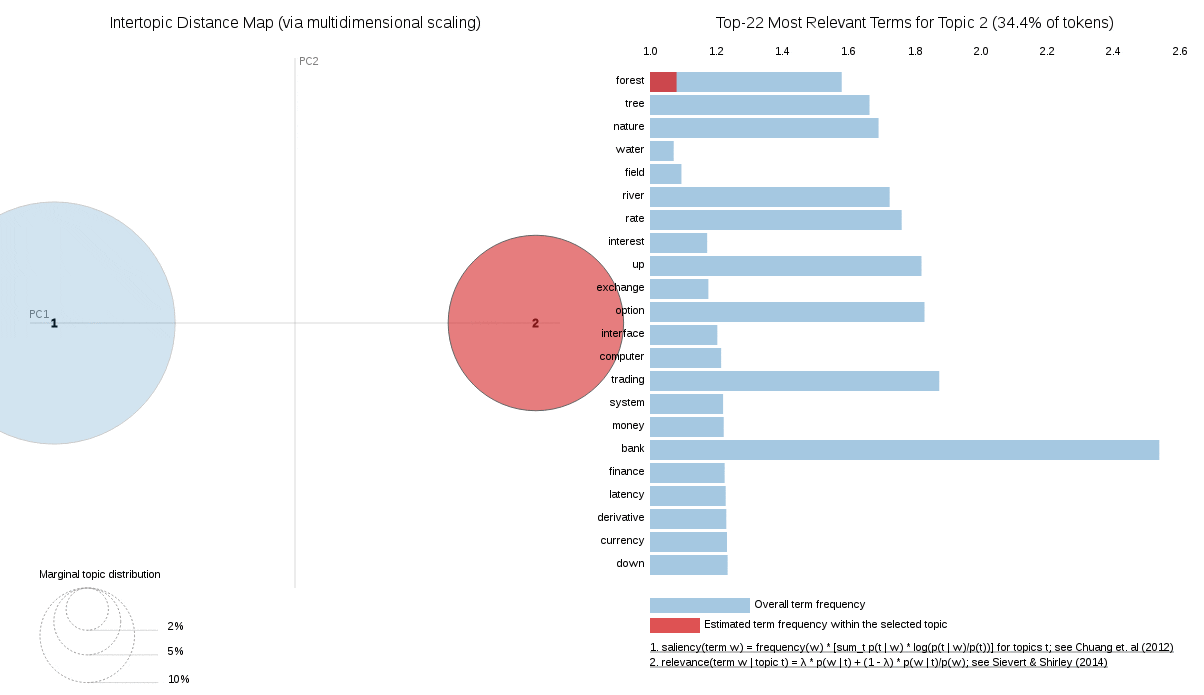
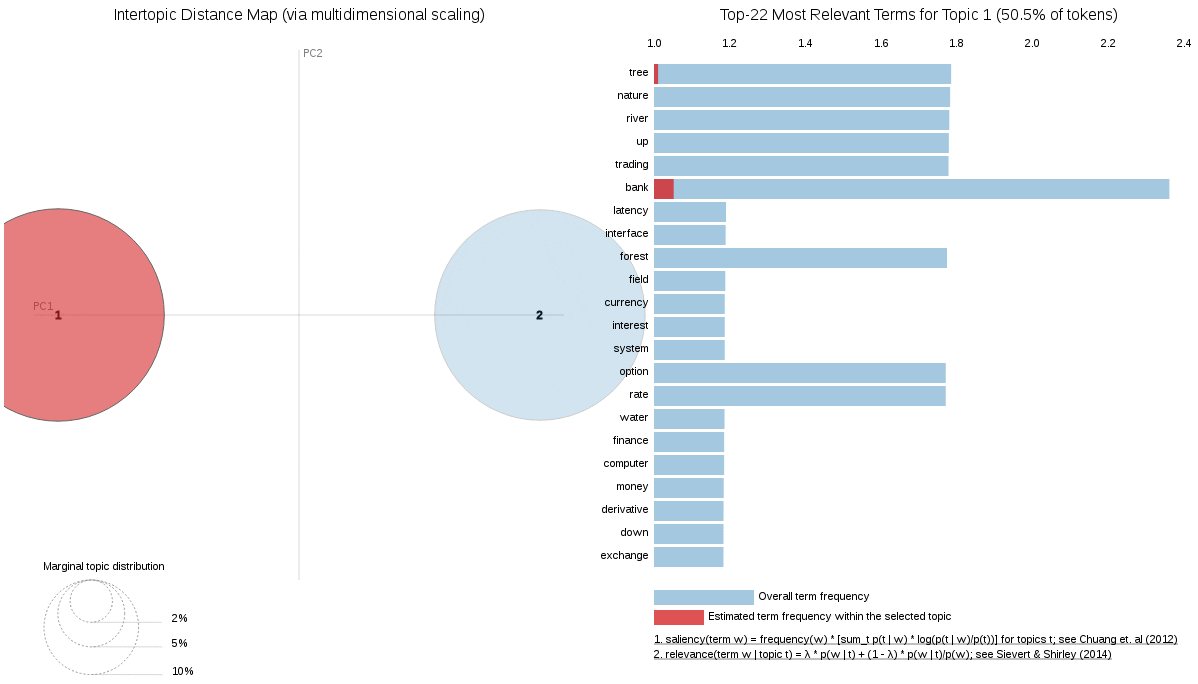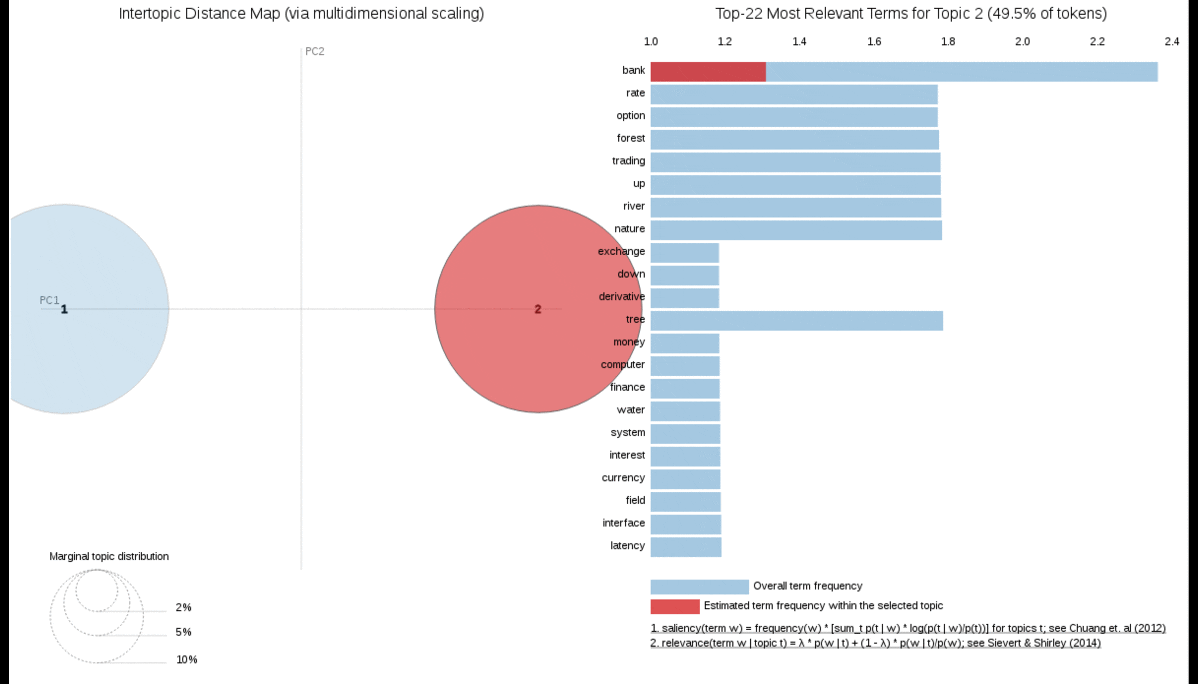
An interesting example would be the word ‘bank’ which could mean ‘a financial institution’ or ‘a river bank’. A good topic modeling algorithm can tell the difference between these two meanings based on context. Coloring words is a quick way to assess if the model understands their meaning and if it is any good.
For example, we trained two topic models on a toy corpus of nine documents.
texts = [['river', 'bank', 'nature'], ['money', 'finance', 'bank', 'currency', 'up', 'down'], ['trading', 'computer', 'interface', 'system'], ['forest', 'nature', 'water', 'tree'], ['option', 'derivative', 'latency', 'bank', 'trading'], ['tree'], ['exchange', 'rate', 'option'], ['interest', 'rate', 'up'], ['field', 'forest', 'river']] dictionary = Dictionary(texts) corpus = [dictionary.doc2bow(text) for text in texts] goodLdaModel = LdaModel(corpus=corpus, id2word=dictionary, iterations=50, num_topics=2) badLdaModel = LdaModel(corpus=corpus, id2word=dictionary, iterations=1, num_topics=2)
One LDA model is trained for 50 iterations and another is trained for just one iteration. We expect the model to get better the longer we train it.
You may notice that the texts above don’t look like the texts we are used to, instead they are actually Python lists. It is because we converted them to a Bag of Words representation. That is how the LDA model sees text. The word order doesn’t matter and some very frequent words are removed. For example 'A bank of a fast river.' becomes ['bank', 'river', 'fast'] in Bag of Words format.
Let’s see how good the two models are at distinguishing between a ‘river bank’ and a ‘financial bank. If all the words in a document are about nature then our swing word ‘bank’ should become a “river bank” colored in the nature topic color of ‘blue’.
bow_water = ['bank','water','river', 'tree'] color_words(goodLdaModel, bow_water)
bank river water tree
color_words(badLdaModel, bow_water)
bank river water tree
The good model successfully completes this task while the bad model thinks it is a ‘financial bank’ and colors it red.
Choosing the Best Topic Model: pyLDAvis
We can also tell the better trained model fits quite well because it has clear Nature and Finance topics. The visualisation below is from pyLDAvis, a wonderful visualisation tool for qualitative assessment of Topic Models. You can play interactively with this particular visualization in this Jupyter notebook.There is also a great introduction to pyLDAvis from its creator Ben Mabey in his talk on YouTube.
Choosing the Best Topic Model: Quantitative approach
There is a new gensim feature to automatically choose the best model without a manual visualisation in pyLDAvis or word coloring. It is called ‘topic coherence’. One of the students currently enrolled in our Incubator program, Devashish, has implemented this in Python based on paper by Michael Röder et al.
There is an interesting twist here. Surprisingly, a mathematically rigorous calculation of model fit (data likelihood, perplexity) doesn't always agree with human opinion about the quality of the model, as shown in a well-titled paper "Reading Tea Leaves: How Humans Interpret Topic Models". But another formula has been found to correlate well with human judgement. It is called 'C_v topic coherence'. It measures how often the topic words appear together in the corpus. Of course, the trick is how to define ‘together’. Gensim supports several topic coherence measures including C_v. You can explore them in this Jupyter notebook.
As expected from our manual inspections above, the model which trained for 50 epochs has higher coherence. Now you can automatically choose the best model using this number.
goodcm = CoherenceModel(model=goodLdaModel, texts=texts, dictionary=dictionary, coherence='c_v') print goodcm.get_coherence() 0.552164532134 badcm = CoherenceModel(model=badLdaModel, texts=texts, dictionary=dictionary, coherence='c_v') print badcm.get_coherence() 0.5269189184
Conclusion
We have covered three ways to evaluate a topic model – coloring words, pyLDAvis and topic coherence. The one you choose depends on the number of models and topics. If you have a handful of models and a small number of topics, then you could run the manual inspections in a reasonable amount of time. Coloring swing words in your specific domain is an important one to get right. In other situations manual inspections are not feasible. For example, if you’ve run an LDA parameter grid search and have a lot of models, or if you have thousands of topics. In that case the only way is the automated topic coherence to find the most coherent model, then a quick manual validation of the winner with word coloring and pyLDAvis.
I hope you find these model selection techniques useful in your NLP applications! Let us know if you have any questions about them on the gensim mailing list. We also offer NLP consulting services at RaRe Technologies.
 Bio: Lev Konstantinovskiy, an expert in natural language processing, is a Python and Java developer. Lev has extensive experience working with financial institutions and is RaRe’s manager of open source communities including gensim, an open source machine learning toolkit for understanding human language. Lev holds the position of Open Source Evangelist, R&D at RaRe Technologies.
Bio: Lev Konstantinovskiy, an expert in natural language processing, is a Python and Java developer. Lev has extensive experience working with financial institutions and is RaRe’s manager of open source communities including gensim, an open source machine learning toolkit for understanding human language. Lev holds the position of Open Source Evangelist, R&D at RaRe Technologies.
Related: