 The 10 Algorithms Machine Learning Engineers Need to Know
The 10 Algorithms Machine Learning Engineers Need to Know
 The 10 Algorithms Machine Learning Engineers Need to Know
The 10 Algorithms Machine Learning Engineers Need to KnowRead this introductory list of contemporary machine learning algorithms of importance that every engineer should understand.
6. Ensemble Methods:
Ensemble methods are learning algorithms that construct a set of classifiers and then classify new data points by taking a weighted vote of their predictions. The original ensemble method is Bayesian averaging, but more recent algorithms include error-correcting output coding, bagging, and boosting.
- They average out biases: If you average a bunch of democratic-leaning polls and republican-leaning polls together, you will get an average something that isn’t leaning either way.
- They reduce the variance: The aggregate opinion of a bunch of models is less noisy than the single opinion of one of the models. In finance, this is called diversification — a mixed portfolio of many stocks will be much less variable than just one of the stocks alone. This is why your models will be better with more data points rather than fewer.
- They are unlikely to over-fit: If you have individual models that didn’t over-fit, and you are combining the predictions from each model in a simple way (average, weighted average, logistic regression), then there’s no room for over-fitting.
Unsupervised Learning Algorithms
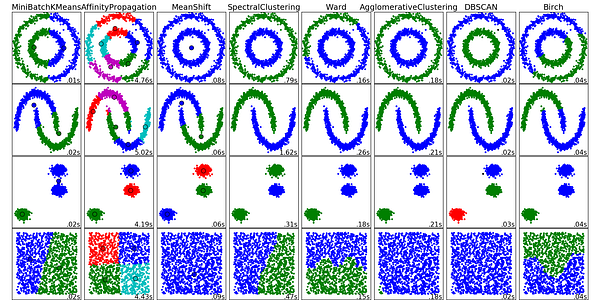
7. Clustering Algorithms:
Clustering is the task of grouping a set of objects such that objects in the same group (cluster) are more similar to each other than to those in other groups.
- Centroid-based algorithms
- Connectivity-based algorithms
- Density-based algorithms
- Probabilistic
- Dimensionality Reduction
- Neural networks / Deep Learning
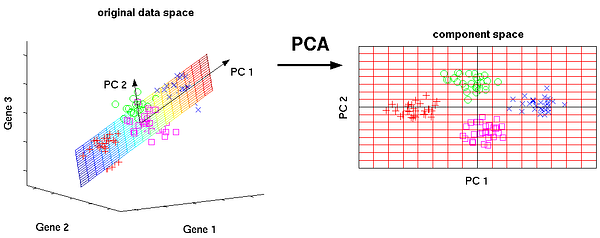
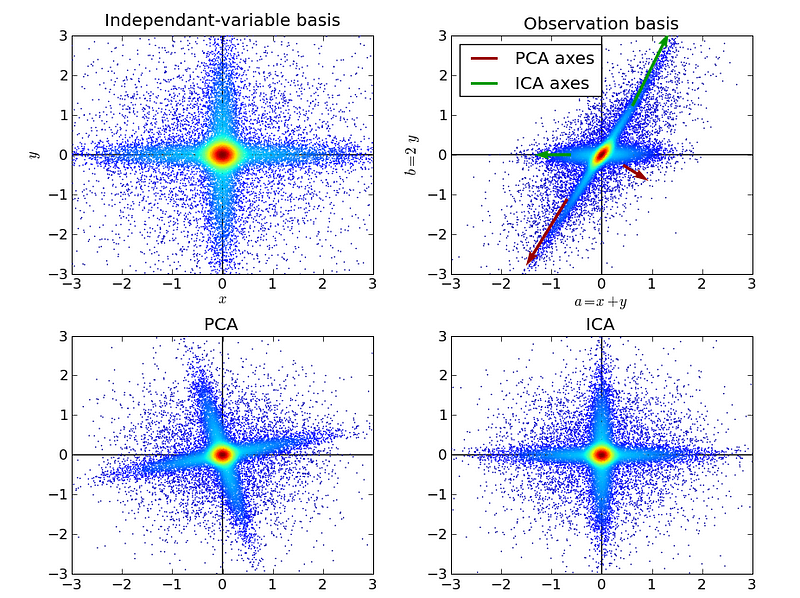
8. Principal Component Analysis:
PCA is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components.
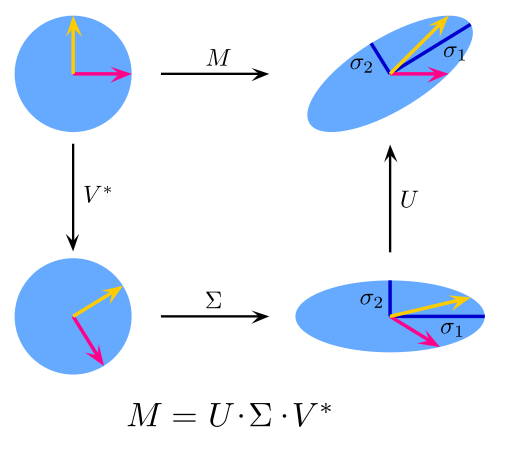
9. Singular Value Decomposition:
In linear algebra, SVD is a factorization of a real complex matrix. For a given m * n matrix M, there exists a decomposition such that M = UΣV, where U and V are unitary matrices and Σ is a diagonal matrix.
10. Independent Component Analysis:
ICA is a statistical technique for revealing hidden factors that underlie sets of random variables, measurements, or signals. ICA defines a generative model for the observed multivariate data, which is typically given as a large database of samples.
In the model, the data variables are assumed to be linear mixtures of some unknown latent variables, and the mixing system is also unknown. The latent variables are assumed non-gaussian and mutually independent, and they are called independent components of the observed data.
Now go forth and wield your understanding of AI algorithms to create machine learning applications that make better experiences for people everywhere.
Bio: James Le is a Product Intern at New Story Charity and a Computer Science and Communication student at Denison University.
Original. Reposted with permission.
Related: