Reinforcement Learning and the Internet of Things
Gain an understanding of how reinforcement learning can be employed in the Internet of Things world.
By Ajit Jaokar, FutureText, and Pragnesh Shah.

Introduction
At the Data Science for IoT course, we explore some interesting problems – one of which is the implications of Deep Learning for the Internet of Things. More specifically, I am interested in the use of Reinforcement learning for the Internet of Things i.e. thinking beyond convolutional neural networks for IoT.
Also, if you follow my tweets and work, I like the work of Senior Data Scientist Brandon Rohrer at Microsoft. For example, a three part blog I have often referred to: Which algorithm family can answer my question
This blog is based on an open source initiative from Brandon called Becca which acts as a ‘general purpose brain for houses and robots and other things’. Becca is a personal initiative and completely Open sourced. It is not associated with a company and is free to download and use under the MIT license. Becca is based on a toy algorithm which is an improvement over traditional Reinforcement neural networks. In exploring Becca through the Open Source code and other videos, we have a great example of how IoT could engage with Reinforcement learning. This post is written by me and also Pragnesh Shah who is exploring this theme in the course with me.
A brief overview or Reinforcement Learning
Before we begin, here is a brief introduction of Reinforcement learning. This section is adapted from a book by Richard Sutton (MIT Press) on reinforcement learning.
Reinforcement learning is learning what to do i.e. how to map situations to actions--so as to maximize a numerical reward signal. Unlike most forms of machine learning, the learner is not told which actions to take. Instead, the learner must discover which actions yield the most reward by trying them. Actions may affect not only the immediate reward but also all subsequent rewards. Thus, the two characteristics: trial and error search and delayed reward are the two most important distinguishing features of reinforcement learning.
Reinforcement learning works in a cycle of sense-action-goals. Because reinforcement learning learns from immediate interaction with the environment, it is different from supervised learning (learning from examples provided by a knowledgeable external supervisor). The interactive learning approach is beneficial in navigating in uncharted territory. Here, ‘uncharted territory’ refers to situations where we
- We don’t know the examples to train on
- We don’t know the right and wrong values for the examples
- However, we do know an overall goal and
- We can sense the environment and take steps to maximise both immediate and long term rewards.
One of the challenges that arise in reinforcement learning and not in other kinds of learning is the trade-off between exploration and exploitation. The agent must perform both exploration and exploitation simultaneously. At the same time, the agent must consider the whole problem and operate in an environment of uncertainty.
For example, when applied to IoT: An adaptive controller adjusts parameters of a petroleum refinery's operation in real time. The controller optimizes the yield/cost/quality trade-off (i.e. the end goal) on the basis of specified marginal costs (i.e. learning by interaction with its environment) without sticking strictly to the set points originally suggested by engineers. The agent improves its performance over time
Explaining the problem to be solved for IoT
Previously, Sibanjan Das and I have addressed this problem on kdnuggets (Deep Learning – IoT – H2O) where we said:
Deep learning algorithms play an important role in IOT analytics. Data from machines is sparse and/or has a temporal element in it. Even when we trust data from a specific device, devices may behave differently at different conditions. Hence, capturing all scenarios for data preprocessing/training stage of an algorithm is difficult. Monitoring sensor data continuously is also cumbersome and expensive. Deep learning algorithms can help to mitigate these risks. Deep Learning algorithms learn on their own allowing the developer to concentrate on better things without worrying about training them.
This idea can be expanded in terms of Becca as below by viewing a house as a Robot based on Reinforcement learning.
A Robot has Sensors, Joint positions, Odometers, Cameras, Proximity sensors, Contact sensors, Pressure sensors, Laser scanners etc. Similarly, a house also has sensors such as Thermometer, Security camera, Smoke detector, Microphone, Window and door position, Electric, gas and water flow etc. We also have actuators. In a house, these are: Light switches, Blinds, Camera motion, Sound fire alarm, Locks etc
The ‘Brain’ for such as system can be ‘rule based’ or algorithm based (based on learned behaviour) addressing questions such as: Which action is most relevant here? i.e. Should I raise or lower the temperature? Should I vacuum the living room again or stay plugged in to my charging station?
Should I brake or accelerate in response to that yellow light? Etc.
Instead of rule based algorithms or algorithms based on learned behaviour(ex supervised learning algorithms), the application of Reinforcement Learning to this scenario is even more interesting - because not all rules can be set in advance. Further, the ‘rules’ can be discovered by interacting with the environment through sensors for optimizing the long term/delayed reward.
However, in practise, this scenario has many challenges:
- Nearly all machine learning algorithms assume that your world does not change.For example – if a Robot learns about the structure of your room and then you rearrange the furniture – that breaks the algorithm!
- Reinforcement learning algorithms don’t handle changes in sensors and actuators. Replacing a floor lamp with a light fixture would break them (changes in actuators)
- Most reinforcement learning algorithms don’t handle changing goals: They would fight keeping the house warmer even when you changed to goal intentionally (changed setting to warmer)
- Most machine learning algorithms take a lot of time to learn. By the time they’ve learned it is too late: Typically the algorithm takes 10,000 samples from data points to learn what to do. If 1 data point is one 24 hour cycle – 10,000 samples is 27 years!
- Most reinforcement learning algorithms don’t scale gracefully. If you double the number of sensors – this affects training. If you double the number of sensors, for a linear algorithm, it doubles the training time. With a polynomial algorithm, takes the factor of 2 and raises it to a power (like square or cube). But many reinforcement learning algorithms are exponential – which radically increases the training time
So, Becca proposes a new reinforcement learning algorithm
Consider a smart thermostat
The Sensor is the Thermometer
The Actuator is the Heater switch
The ‘World’ comprises of Heater, ducts, rooms, walls, weather
The Cycle takes 10 minutes
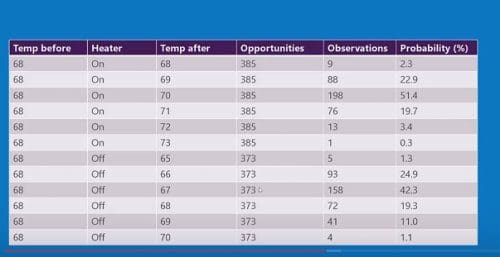
Once we are through the loop i.e. after 10 mins, the temperature measured at 68 degrees
The next time the heater switched on for 10 minutes (arbitrarily)
The temperature is measured at 70 degrees
We put these readings in a table. And observe how many times this has occurred
We also add to this the estimate of the probability that each measurement has occurred
Consider now a new scenario
A fresh decision is to be made
Temperature is 68
Arbitrarily turn off heater for 10 mins
Temperature is now 65 degrees
Update table and probabilities for this scenario
Thus, you build up the table
Thus the table gives us the probability of the new temperature given a starting temperature and a heating duration
This represents a model and can be used for any scenario
Answering the challenge of reinforcement learning algorithms, we have
- An Incremental algorithm based on reinforcement learning.
- Needs no data to start.
- Doesn’t require on-going human participation.
- On-going training.
- Constant adaptation.
- Learns decisions.
The Caveat is: For a whole house this includes
1. All the measurements,
2. Of all the sensors,
3. Both before and after,
4. Across all actions.
That is a lot of work but...
- It’s still fast
- Data volumes get big but it’s polynomial, not exponential
- And it’s storage intensive, not CPU intensive. Using traditional Big Data techniques – storage intensive tasks can easily be scaled up
- Computation is mostly comparisons and arithmetic
Thus, this implementation is suited for: Large databases, Cloud processing and Data lakes. You can see this in the wider context A methodology for solving problems with Data Science for Internet of Things.
The basic action is still the same as Reinforcement learning as we see below:
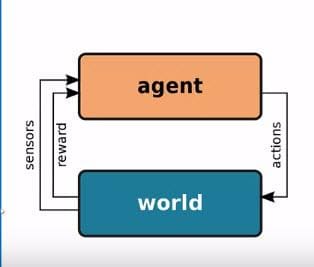
The question is: To what extent can IoT ecosystems be turned into Robots (as described above)?
Also the same reinforcement learning based model can scale to neighbourhoods, transports, media, social networks etc – anywhere people and sensors are involved and their interaction(i.e. rule formation) is hard to predict.
We have the sensors and we have the actuators – we are just missing the brain.
Conclusion
To conclude, we discuss here an enhancement to a Reinforcement algorithm – but in doing so – I see one the best ways I can illustrate Reinforcement learning networks with IoT.
Many thanks to Brandon for his insights on the post.
If you want to join the next batch of the Data Science for IoT course, please email me at ajit.jaokar at futuretext.com.
Related: