The Human Vector: Incorporate Speaker Embeddings to Make Your Bot More Powerful
One of the many ways in which bots can fail is by their (lack of) persona. Learn how speaker embeddings can help with this problem, and can help improve the persona of your bot.
By Megan Barnes, Init.ai.
How do we evaluate AI? You may have heard about self-driving cars recently; their release seems imminent. Self-driving cars have a clear objective for evaluation: don’t crash. Beyond avoiding accidents, there isn’t a notion of how well a car drives.
In the engineering challenge of conversational agents, the threshold for what we want becomes higher and hazier. There is a don’t crash analog in conversational AI: functional failures. We can tell when bots don’t really understand us. They respond in ways that don’t answer our questions, aren’t relevant to the conversation, or just don’t make sense. The researchers behind “A Persona-Based Neural Conversation Model” point out a more subtle way in which bots can fail: their (lack of) persona.
In human conversations, we rely on assumptions about how other speakers conduct themselves. This is known as the cooperative principle in the field of pragmatics. This principle breaks down into ‘maxims’ for speech that speakers either follow or flout. In short, we rely on others saying truthful statements, providing as much information as possible, being relevant, and saying things appropriately. When speakers purposefully flout these maxims, it carries meaning that we can understand (e.g. sarcasm, in which a speaker makes statements that are obviously untrue). When deviation from the maxims is unintentional, however, it can derail a conversation.
Consider these example exchanges from “A Persona-Based Neural Conversation Model”:

The problem here is that our knowledge of the world makes this a clear violation of the Maxim of Quality (paraphrase: say things that are true). One person can’t live in two different places or be two different ages at the same time. That means that we understand at least some of the responses to be untrue. It’s conceivable that a skilled speaker of English could make these exact same statements intentionally and make an implicature in the process. In the last exchange above, for example, the responder could be making a joke about the amount of reading required for a psych major. Whether it’s actually funny is a matter of taste. The difference with bots is that we don’t expect humor. It becomes clear to us that inconsistent responses are unintentional and that makes communication difficult.
The specific issue of inconsistent responses is intrinsic to language modeling because data-driven systems are geared toward generating responses with the highest likelihood, without regard for the source of that response. When searching through the output space, an inference is made based on the most likely sequence of words to follow another sequence according to the model. In the study referenced above, the baseline model is an LSTM recurrent neural network, an architecture common in conversational AI. It uses the softmax function to create a probability distribution over possible outputs and picks the most likely next word in the sequence, no matter who generated it in the training data. Human speakers expect consistent personasfrom the bots they speak to and current techniques are ignoring that.
Li et al. describe personas as, “composite[s] of elements of identity (background facts or user profile), language behavior, and interaction style”(1). A persona is based on a real individual that generated part of the training data, and is represented by a vector, the speaker embedding. They randomly initialize speaker embeddings and learn them during training.
A basic LSTM can be graphically represented like this:
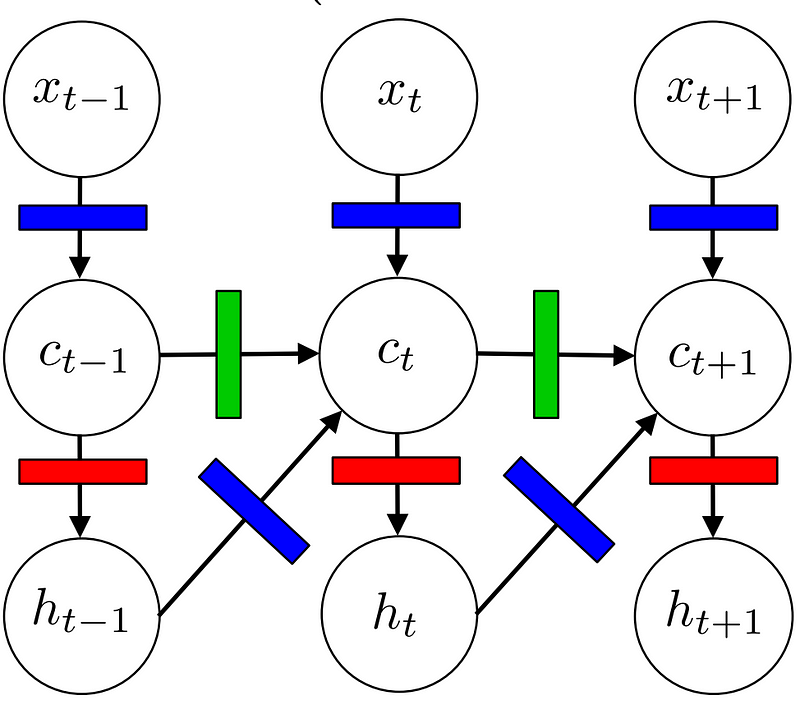
where x represents a word embedding in a sequence, c represents a hidden layer and h represents the output of the model, all at time t. The colored rectangles represent gates, which transform input vectors. The model can also be represented by the functions below (in which e takes the place of xto represent a word embedding), where i, f, o, and l represent the multicolor gates above.
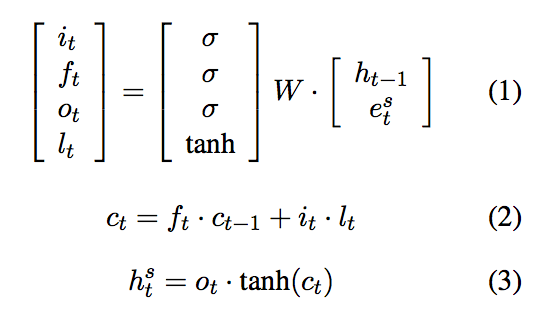
In what Li et al. term the Speaker Model, they inject the model with the speaker embedding, v, which can be seen in its representation below.
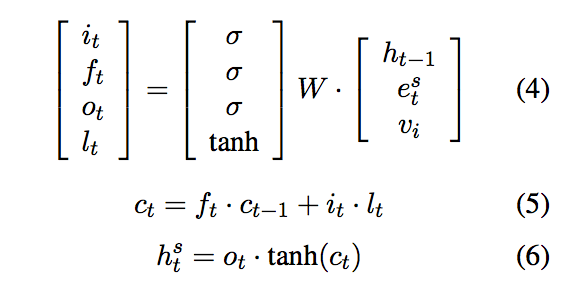
This adds information about speaker i into every time step of the sequence. This is equivalent to adding a v input node into the hidden layer of the LSTM graphical model, marked with a blue gate. Incorporating speaker embeddings into the LSTM model improved its performance, decreasing perplexity and increasing BLEU score in the majority of the datasets the researchers examined.
The researchers also noted that a single persona should be adaptable. A person doesn’t address their boss in the same way they address their little brother. Because of this, they also decided to try what they termed the Speaker-Addressee Model. This model substitutes a speaker pair embedding,V, for a speaker embedding, of the form below. The speaker pair embedding is meant to model interactions between specific individuals.
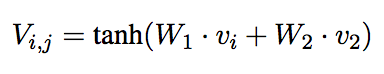
The Speaker-Addressee model achieved similar success. This is a particularly cute result that the Speaker-Addressee model generates when trained on movie conversation data (with reference to character relationships in Friendsand The Big Bang Theory):

The important takeaway from Li et al.’s research is that AI is a diverse field with a range of different tasks that need nuanced solutions. Neural nets are great, but if they are treated like a black box, they can only perform so well on complex tasks like conversation. We need to take into account what we actually expect out of a bot. Cohesive, adaptive personas and systems tailored to reflect those expectations are the key to achieving sophisticated results. After all, we want more from bots than just avoiding crash and burn.
Bio: Megan Barnes is a software developer working on machine learning infrastructure. If you’re interested in learning more about conversational interfaces, follow her on Medium and Twitter.
And if you’re looking to create a conversational app for your company, check out Init.ai and our blog on Medium, or connect with us on Twitter. Check out the original research referenced in this article here.
Original. Reposted with permission.
Related: