Introducing Dask for Parallel Programming: An Interview with Project Lead Developer
Introducing Dask, a flexible parallel computing library for analytics. Learn more about this project built with interactive data science in mind in an interview with its lead developer.
In the coming weeks, KDnuggets plans on sharing some information and tutorials about Dask.
What is Dask, you ask? From its documentation:
Dask is a flexible parallel computing library for analytics.
Is your interest piqued? If you are interested in learning more about a software project built for computation and interactive data science which could literally help revolutionize the way you perform data processing and parallelize your own projects, read the the discussion I had with Matthew Rocklin, lead developer of Dask.

Matthew Mayo: First off, can you give us the one sentence overview of Dask?
Matthew Rocklin: Ha, that's tough. Dask is used in a few very different ways so we'll have to be fairly general here.
Dask is a Python library for parallel programming that leverages task scheduling for computational problems.
It would be easy to draw comparisons with other superficially similar projects. What other open source projects do *you* see Dask competing with?
Dask straddles two different groups of "competitor" projects:
- Dynamic task schedulers like AirFlow/Luigi/Celery
- "Big Data" analysis frameworks like Hadoop/Spark.
At its core Dask looks a lot like a tweaked Airflow/Luigi/Celery. There is a central task scheduler that sends jobs (Python functions) out to lots of worker processes either on the same machine or on a cluster:
Worker A, please compute x = f(1), Worker B please compute y = g(2).
Worker A, when g(2) is done please get y from Worker B and compute z = h(x, y).
Where Dask differs is that while Airflow/Luigi/Celery were primarily designed for long-ish running data engineering jobs Dask was designed for computation and interactive data science. We focus less on running jobs regularly (like Airflow) or integrating with lots of Data engineering services (like Luigi) and much more on millisecond response times, inter-worker data sharing, Jupyter notebook integration, etc.. I wouldn't use Dask to do a daily ingest of data, but I would use it to design and run algorithms to analyze that data.
On top of this task scheduler we built higher-level array, dataframe, and list interfaces that mimic NumPy, Pandas, and Python iterators. This pushes Dask into the space of the popular "Big Data" frameworks like Hadoop and Spark. The dominance of Spark in particular these days is pretty huge, especially in business analytics use cases (data ingest, SQL stuff, some light machine learning.) Most of the people who use Dask in these use cases use it either because they want to stay in Python, because they love Pandas, or because they were doing things that were a bit too complex for Spark, like N-dimensional arrays, or some of the fancier Pandas time series functionality. Dask generally feels a bit lighter weight if you're already in Python. That being said, Spark is way more mature and definitely does what it was designed to do very very well.
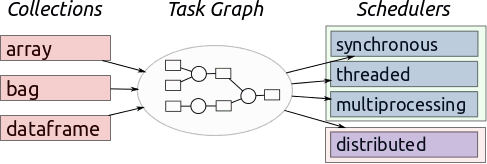
What does Dask do better than any other potential solution?
Well, first, lets say that Dask does lots of things worse than other potential solutions. It's not trying to implement SQL or be a parallel database. It's not going to out-compete MPI on super computers. Nor is it going to out-compete your hand-tuned C code.
Second, lets say how Dask most often gets used. Most users use Dask.dataframe or Dask.bag to analyze directories of CSV or JSON files. However if Dask disappeared today these users would be fine, there are loads of software projects trying to solve this problem.
OK, so what's left? Quite a lot of un-served territory actually. The people for whom Dask is really a life saver are people with custom or irregular computational problems that need parallelism. These are scientists, quants, algorithm developers, and a growing contingent of enterprise research groups. These people have novel problems that require them to build their own parallel computing solutions. The core of Dask (the part that looks like Airflow/Luigi/Celery) seems to suit their needs well. They want someone else to handle sockets/threads/resiliency/dat
Dask's interface (for instance, Dask DataFrame, Dask Array, Dask Bag) seems incredibly straightforward. What else about Dask do you think makes it attractive for potential adopters?
Yeah, as you suggest copying the NumPy and Pandas interfaces definitely lowers the barrier to entry. Many people know and love NumPy and Pandas. This sounds silly, but this choice to copy the interface also reduces the amount of time Dask developers spend stressing about and bikesheding over API.
The ease of installation and ability to start immediately on a laptop is a big win. The fact that Dask is a pure Python library that can be installed with standard Python package managers and just runs without setup or config files helps with a broad class of user.
Conceptually there is a big leap from "just a library" to "a framework" in people's minds. You can use dask in a way that feels like "just a library" like the multiprocessing module, Joblib, or concurrent.futures modules in Python. Dask was designed to be the smallest possible library that would complement the existing PyData ecosystem with parallelism. It was never designed to replace anything. A lot of the core developers of other libraries seem to be buying into it for this reason.
Finally, Dask focused the first year of its life on just single machine parallelism. It served the needs of people with "moderately large data" who want to use all of the power within their laptop or a heavy workstation. There is a huge community of users, mostly in science and finance, who have "moderately large data" and don't want to deal with the separation of running their code on a cluster. Dask was a huge hit with these users early on. Also, the performance and productivity of a single heavy workstation is pretty hard to beat for all but the largest of problems. We've since moved on to distributed systems, but single-machine parallelism still accounts for something like 80% of use today.
Could you describe a simple use case for Dask, to give readers something to visualize?
I'll give two, one for task scheduling (Airflow-like) and one for big data collections (Spark-like)
A hypothetical quality assurance group at an automobile company is looking for failures using a combination of collected telemetry data (they collect data from hundreds of sensors in each car) and from engineering models about how they think their car components function. Several different researchers in a team are in charge of different components of the car, and build custom Python functions to model how these components respond to different situations. Other researchers in charge of integrating these components take the models that the previous level of component-focused researchers created and combine them to create a complex tree of relationships (cars are complex). They run these models over millions of situations coming from their data. Their aggregate model has tons of parallelism, but it's very messy. They throw all of their functions into Dask which manages this parallelism for them, running on their team's laptops during prototyping and their cluster when they want to run over the full dataset. Afterwards they generate visual reports, and get together to look at the results. Based on the results the researchers at various parts go away and tweak various parts of their models, changing small parts of the Dask graph, rerunning only the parts of the computation that were affected.
For big-data collections (array/dataframe/list) lets look at climate science. Climate scientists have data that looks like "the temperature, air pressure, and windspeed measured every square kilometer of the Earth, for various altitudes, going back fifty years." They want to sift through this 5D dense data cube, grouping it, joining it against other datasets, and reducing it down to aggregates that help them answer their research questions. They use the popular XArray project to manage their data. XArray uses NumPy when datasets are small and fit in memory (say, 1GB) but switches to Dask.array when datasets grow larger than memory but still fit on disk (say 10GB-100GB). On these larger datasets a full computation might take a minute or two (disks are sometimes slow), but the climate scientist is happy because they are able to keep working on their laptop, rather than switch to a cluster. They now look at finer resolution data that goes back longer in time without really worrying about scale, all from their personal machine and with the same interface they used before on in-memory data.
How did you get involved in Dask development, Matthew?
This is actually my full time job. I work for Continuum Analytics, a for-profit company embedded in the open source numeric Python ecosystem. They're a bit like RedHat for numeric Python. The company has strong incentives to keep the open source Python ecosystem strong so they build open source projects that fill perceived gaps. Dask is one of those projects, along with others like Conda, Numba, and Bokeh.
What's the best way to get involved in Dask development, if there are any readers so inclined?
The docs are a good start:
http://dask.
There is an issue tracker with a label for Introductory issues:
https://github.com/
I also suggest trying out the quickstart for the distributed scheduler, which is a bit more focused on Airflow/Luigi workloads:
http://distributed.
Mostly though the core parts of Dask feel pretty solid at this point. I'd say that the best thing to do now is to use Dask on novel problems and see how they can break it. Every time this happens we learn more about how to perform task scheduling better.
Is there anything else we should know about Dask?
Yeah, people are paying for this stuff now, which is crazy. Dask is mostly grant funded (thanks DARPA and Moore!) but I'm now starting to get e-mails pretty regularly from companies asking to pay for the development of particular open source features. Gone is the conversation where we have to convince them that open-sourcing the work would be better for everyone. They bring it up right away. So if you're into open source software you should be really happy. And if you're a company interested in a flexible distributed computing system in Python, you know how to get in contact with me :)
I want to thank you for your time, Matthew. Your name seems synonymous with Dask development on the interwebs, and I'm sure it keeps you busy. We appreciate you taking the time to talk with us.
Heh, that's only because I'm the loudest :)
There are several others without whom Dask would never be where it is today. There are core developers like Jim Crist, Martin Durant, Erik Welch, Masakai Horikoshi, Blake Griffith, and about 70 others. There are developers of other PyData libraries like MinRK (Jupyter), Stephan Hoyer (XArray, Pandas), Jeff Reback (Pandas), Stefan van der Walt (NumPy, SKImage), Olivier Grisel (SKLearn, Joblib) that collaborate heavily to make sure that Dask integrates well with the rest of the Python ecosystem. There are people within Continuum like Ben Zaitlen, Kris Overholt, Daniel Rodriguez, and Christine Doig who make sure that systems run smoothly so that development happens rapidly. There are also people who fund Dask's development, like the DARPA XData project, the Moore Foundation, and private companies. These organizations make sure that people like me can work on projects like Dask full time; which is pretty great!
I'm definitely forgetting several awesome people in that list.
Related: