Data Science Basics: An Introduction to Ensemble Learners
New to classifiers and a bit uncertain of what ensemble learners are, or how different ones work? This post examines 3 of the most popular ensemble methods in an approach designed for newcomers.
Algorithm selection can be challenging for machine learning newcomers. Often when building classifiers, especially for beginners, an approach is adopted to problem solving which considers single instances of single algorithms.
However, in a given scenario, it may prove more useful to chain or group classifiers together, using the techniques of voting, weighting, and combination to pursue the most accurate classifier possible. Ensemble learners are classifiers which provide this functionality in a variety of ways.
This post will provide an overview of bagging, boosting, and stacking, arguably the most used and well-known of the basic ensemble methods. They are not, however, the only options. Random Forests is another example of an ensemble learner, which uses numerous decision trees in a single predictive model, and which is often overlooked and treated as a "regular" algorithm. There are other approaches to selecting effective algorithms as well, treated below.
Bagging
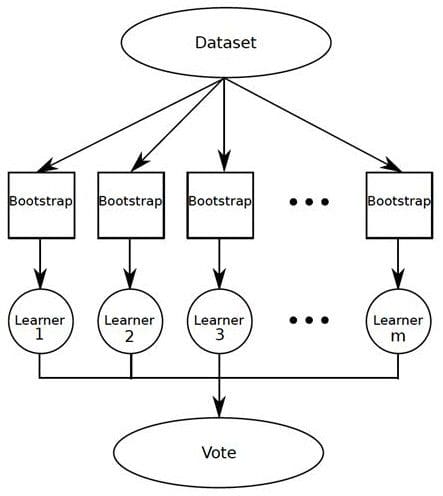
Bagging operates by simple concept: build a number of models, observe the results of these models, and settle on the majority result. I recently had an issue with the rear axle assembly in my car: I wasn't sold on the diagnosis of the dealership, and so I took it to 2 other garages, both of which agreed the issue was something different than the dealership suggested. Voila. Bagging in action.
I only visited 3 garages in my example, but you could imagine that accuracy would likely increase if I had visited tens or hundreds of garages, especially if my car's problem was one of a very complex nature. This holds true for bagging, and the bagged classifier often is significantly more accurate than single constituent classifiers. Also note that the type of constituent classifier used are inconsequential; the resulting model can be made up of any single classifier type.
Bagging is short for bootstrap aggregation, so named because it takes a number of samples from the dataset, with each sample set being regarded as a bootstrap sample. The results of these bootstrap samples are then aggregated.
Bagging TL;DR:
- Operates via equal weighting of models
- Settles on result using majority voting
- Employs multiple instances of same classifier for one dataset
- Builds models of smaller datasets by sampling with replacement
- Works best when classifier is unstable (decision trees, for example), as this instability creates models of differing accuracy and results to draw majority from
- Bagging can hurt stable model by introducing artificial variability from which to draw inaccurate conclusions
Boosting
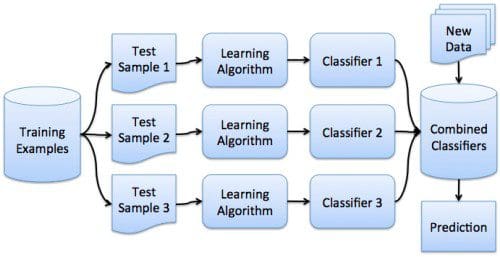
Boosting is similar to bagging, but with one conceptual modification. Instead of assigning equal weighting to models, boosting assigns varying weights to classifiers, and derives its ultimate result based on weighted voting.
Thinking again of my car problem, perhaps I had been to one particular garage numerous times in the past, and trusted their diagnosis slightly more than others. Also suppose that I was not a fan of previous interactions with the dealership, and that I trusted their insight less. The weights I assigned would be reflective.
Boosting TL;DR:
- Operates via weighted voting
- Algorithm proceeds iteratively; new models are influenced by previous ones
- New models become experts for instances classified incorrectly by earlier models
- Can be used without weights by using resampling, with probability determined by weights
- Works well if classifiers are not too complex
- Also works well with weak learners
- AdaBoost (Adaptive Boosting) is a popular boosting algorithm
- LogitBoost (derived from AdaBoost) is another, which uses additive logistic regression, and handles multi-class problems
Stacking
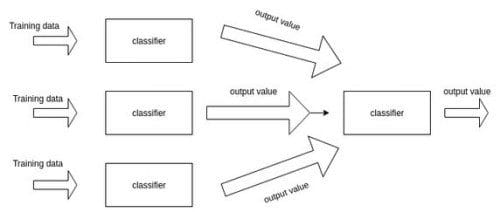
Stacking is a bit different from the previous 2 techniques as it trains multiple single classifiers, as opposed to various incarnations of the same learner. While bagging and boosting would use numerous models built using various instances of the same classification algorithm (eg. decision tree), stacking builds its models using different classification algorithms (perhaps decision trees, logistic regression, an ANNs, or some other combination).
A combiner algorithm is then trained to make ultimate predictions using the predictions of other algorithms. This combiner can be any ensemble technique, but logistic regression is often found to be an adequate and simple algorithm to perform this combining. Along with classification, stacking can also be employed in unsupervised learning tasks such as density estimation.
Stacking TL;DR:
- Trains multiple learners (as opposed to bagging/boosting which train a single learner)
- Each learner uses a subset of data
- A "combiner" is trained on a validation segment
- Stacking uses a meta learner (as opposed to bagging/boosting which use voting schemes)
- Difficult to analyze theoretically ("black magic")
- Level-1 → meta learner
- Level-0 → base classifiers
- Can also be used for numeric prediction (regression)
- The best algorithms to use for base models are smooth, global learners
While the above ensemble learners are likely the most well-known and -utilized, numerous other options exist. Besides stacking, a variety of other meta learners exist as well.
An easy mistake for data science newcomers to make is to underestimate the complexity of the algorithm landscape, thinking that a decision tree is a decision tree, a neural network is a neural network, etc. Besides overlooking the fact that there is significant difference between various specific implementations of algorithm families (look at the vast amount of research being done in neural networks over the past few years for explicit evidence), the idea that various algorithms can be used in tandem (via ensemble or intervening meta-learners) to accomplish greater accuracy in a given task, or even to tackle tasks which, alone, would not be solvable, does not even register. Any form of recent "artificial intelligence" you can think of takes this approach. But that's a different conversation completely.
Related: