Deep Learning Reading Group: Skip-Thought Vectors
Skip-thought vectors take inspiration from Word2Vec skip-gram and attempt to extend it to sentences, and are created using an encoder-decoder model. Read on for an overview of the paper.

Continuing the tour of older papers that started with our ResNet blog post, we now take on Skip-Thought Vectors by Kiros et al. Their goal was to come up with a useful embedding for sentences that was not tuned for a single task and did not require labeled data to train. They took inspiration from Word2Vec skip-gram (you can find my explanation of that algorithm here) and attempt to extend it to sentences.
Skip-thought vectors are created using an encoder-decoder model. The encoder takes in the training sentence and outputs a vector. There are two decoders both of which take the vector as input. The first attempts to predict the previous sentence and the second attempts to predict the next sentence. Both the encoder and decoder are constructed from recurrent neural networks (RNN). Multiple encoder types are tried including uni-skip, bi-skip, and combine-skip. Uni-skip reads the sentence in the forward direction. Bi-skip reads the sentence forwards and backwards and concatenates the results. Combined-skip concatenates the vectors from uni- and bi-skip. Only minimal tokenization is done to the input sentences. A diagram indicating the input sentence and the two predicted sentences is shown below.

Their model requires groups of sentences in order to train, and so trained on the BookCorpus Dataset. The dataset consists of novels by unpublished authors and is (unsurprisingly) dominated by romance and fantasy novels. This “bias” in the dataset will become apparent later when discussing some of the sentences used to test the skip-thought model; some of the retrieved sentences are quite exciting!
Building a model that accounts for the meaning of an entire sentence is tough because language is remarkably flexible. Changing a single word can either completely change the meaning of a sentence or leave it unaltered. The same is true for moving words around. As an example:
One difficulty in building a model to handle sentences is that a single word can be changed and yet the meaning of the sentence is the same.
Put a different way:
One challenge in building a model to handle sentences is that a single word can be changed and yet the meaning of the sentence is the same.
Changing a single word has had almost no effect on the meaning of that sentence. To account for these word level changes, the skip-thought model needs to be able to handle a large variety of words, some of which were not present in the training sentences. The authors solve this by using a pre-trained continuous bag-of-words (CBOW) Word2Vec model and learning a translation from the Word2Vec vectors to the word vectors in their sentences. Below are shown the nearest neighbor words after the vocabulary expansion using query words that do not appear in the training vocabulary:
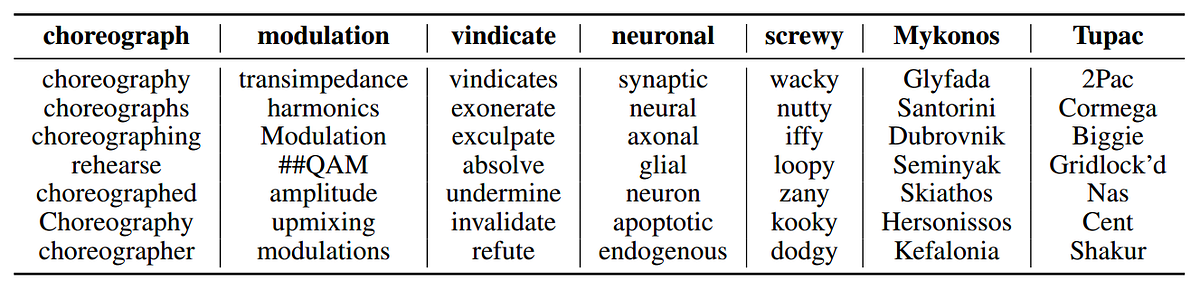
So how well does the model work? One way to probe it is to retrieve the closest sentence to a query sentence; here are some examples:
Query: “I’m sure you’ll have a glamorous evening,” she said, giving an exaggerated wink.
Retrieved: “I’m really glad you came to the party tonight,” he said, turning to her.
And:
Query: Although she could tell he hadn’t been too interested in any of their other chitchat, he seemed genuinely curious about this.
Retrieved: Although he hadn’t been following her career with a microscope, he’d definitely taken notice of her appearance.
The sentences are in fact very similar in both structure and meaning (and a bit salacious, as I warned earlier) so the model appears to be doing a good job.
To perform more rigorous experimentation, and to test the value of skip-thought vectors as a generic sentence feature extractor, the authors run the model through a series of tasks using the encoded vectors with simple, linear classifiers trained on top of them.
They find that their generic skip-thought representation performs very well for detecting the semantic relatedness of two sentences and for detecting where a sentence is paraphrasing another one. Skip-thought vectors perform relatively well for image retrieval and captioning (where they use VGG to extract image feature vectors). Skip-thought performs poorly for sentiment analysis, producing equivalent results to various bag of word models but at a much higher computational cost.
We have used skip-thought vectors a little bit at the Lab, most recently for the Pythia challenge. We found them to be useful for novelty detection, but incredibly slow. Running skip-thought vectors on a corpus of about 20,000 documents took many hours, where as simpler (and as effective) methods took seconds or minutes. I will update with a link to their blog post when it comes online.
Alexander Gude is currently a data scientist at Lab41 working on investigating recommender system algorithms. He holds a BA in physics from University of California, Berkeley, and a PhD in Elementary Particle Physics from University of Minnesota-Twin Cities.
Lab41 is a “challenge lab” where the U.S. Intelligence Community comes together with their counterparts in academia, industry, and In-Q-Tel to tackle big data. It allows participants from diverse backgrounds to gain access to ideas, talent, and technology to explore what works and what doesn’t in data analytics. An open, collaborative environment, Lab41 fosters valuable relationships between participants.
Original. Reposted with permission.
Related: