 Top 20 Python Machine Learning Open Source Projects, updated
Top 20 Python Machine Learning Open Source Projects, updated
 Top 20 Python Machine Learning Open Source Projects, updated
Top 20 Python Machine Learning Open Source Projects, updatedOpen Source is the heart of innovation and rapid evolution of technologies, these days. This article presents you Top 20 Python Machine Learning Open Source Projects of 2016 along with very interesting insights and trends found during the analysis.
Continuing analysis from last year: Top 20 Python Machine Learning Open Source Projects, this year KDnuggets bring you latest top 20 Python Machine Learning Open Source Projects on Github. Strangely, some of the most active projects of last year have become stagnant and also some lost their position from top 20 (considering contributions and commits), whereas new 13 projects have entered into top 20.

Top 20 Python Machine Learning Open Source Projects 2016.
- Scikit-learn is simple and efficient tools for data mining and data analysis, accessible to everybody, and reusable in various context, built on NumPy, SciPy, and matplotlib, open source, commercially usable – BSD license.
Commits: 21486, Contributors: 736, Github URL: Scikit-learn - Tensorflow was originally developed by researchers and engineers working on the Google Brain Team within Google’s Machine Intelligence research organization. The system is designed to facilitate research in machine learning, and to make it quick and easy to transition from research prototype to production system.
Commits: 10466, Contributors: 493, Github URL: Tensorflow - Theano allows you to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently.
Commits: 24108, Contributors: 263, Github URL: Theano - Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by the Berkeley Vision and Learning Center (BVLC) and community contributors.
Commits: 3801, Contributors: 215, Github URL: Caffe - Gensim is a free Python library with features such as scalable statistical semantics, analyze plain-text documents for semantic structure, retrieve semantically similar documents.
Commits: 2702, Contributors: 145, Github URL: Gensim - Pylearn2 is a machine learning library. Most of its functionality is built on top of Theano. This means you can write Pylearn2 plugins (new models, algorithms, etc) using mathematical expressions, and Theano will optimize and stabilize those expressions for you, and compile them to a backend of your choice (CPU or GPU).
Commits: 7100, Contributors: 115, Github URL: Pylearn2 - Statsmodels is a Python module that allows users to explore data, estimate statistical models, and perform statistical tests. An extensive list of descriptive statistics, statistical tests, plotting functions, and result statistics are available for different types of data and each estimator.
Commits: 8664, Contributors: 108, Github URL: Statsmodels - Shogun is Machine learning toolbox which provides a wide range of unified and efficient Machine Learning (ML) methods. The toolbox seamlessly allows to easily combine multiple data representations, algorithm classes, and general purpose tools.
Commits: 15172 Contributors: 105, Github URL: Shogun - Chainer is a Python-based, standalone open source framework for deep learning models. Chainer provides a flexible, intuitive, and high performance means of implementing a full range of deep learning models, including state-of-the-art models such as recurrent neural networks and variational autoencoders.
Commits: 6298, Contributors: 84, Github URL: Chainer - NuPIC is an open source project based on a theory of neocortex called Hierarchical Temporal Memory (HTM). Parts of HTM theory have been implemented, tested, and used in applications, and other parts of HTM theory are still being developed.
Commits: 6088, Contributors: 76, Github URL: NuPIC - Neon is Nervana ’s Python-based deep learning library. It provides ease of use while delivering the highest performance.
Commits: 875, Contributors: 47, Github URL: Neon - Nilearn is a Python module for fast and easy statistical learning on NeuroImaging data. It leverages the scikit-learn Python toolbox for multivariate statistics with applications such as predictive modelling, classification, decoding, or connectivity analysis.
Commits: 5254, Contributors: 46, Github URL: Nilearn - Orange3 is open source machine learning and data visualization for novice and expert. Interactive data analysis workflows with a large toolbox.
Commits: 6356, Contributors: 40, Github URL: Orange3 - Pymc is a python module that implements Bayesian statistical models and fitting algorithms, including Markov chain Monte Carlo. Its flexibility and extensibility make it applicable to a large suite of problems.
Commits: 2701, Contributors: 37, Github URL: Pymc - PyBrain is a modular Machine Learning Library for Python. Its goal is to offer flexible, easy-to-use yet still powerful algorithms for Machine Learning Tasks and a variety of predefined environments to test and compare your algorithms.
Commits: 984, Contributors: 31, Github URL: PyBrain - Fuel is a data pipeline framework which provides your machine learning models with the data they need. It is planned to be used by both the Blocks and Pylearn2 neural network libraries.
Commits: 1053, Contributors: 29, Github URL: Fuel - PyMVPA is a Python package intended to ease statistical learning analyses of large datasets. It offers an extensible framework with a high-level interface to a broad range of algorithms for classification, regression, feature selection, data import and export.
Commits: 9258, Contributors: 26, Github URL: PyMVPA - Annoy (Approximate Nearest Neighbors Oh Yeah) is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mmapped into memory so that many processes may share the same data.
Commits: 365, Contributors: 24, Github URL: Annoy - Deap is a novel evolutionary computation framework for rapid prototyping and testing of ideas. It seeks to make algorithms explicit and data structures transparent. It works in perfect harmony with parallelisation mechanism such as multiprocessing and SCOOP.
Commits: 1854, Contributors: 21, Github URL: Deap - Pattern is a web mining module for the Python programming language. It bundles tools for data mining (Google + Twitter + Wikipedia API, web crawler, HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, k-means clustering, Naive Bayes + k-NN + SVM classifiers) and network analysis (graph centrality and visualization).
Commits: 943, Contributors: 20 , Github URL: Pattern
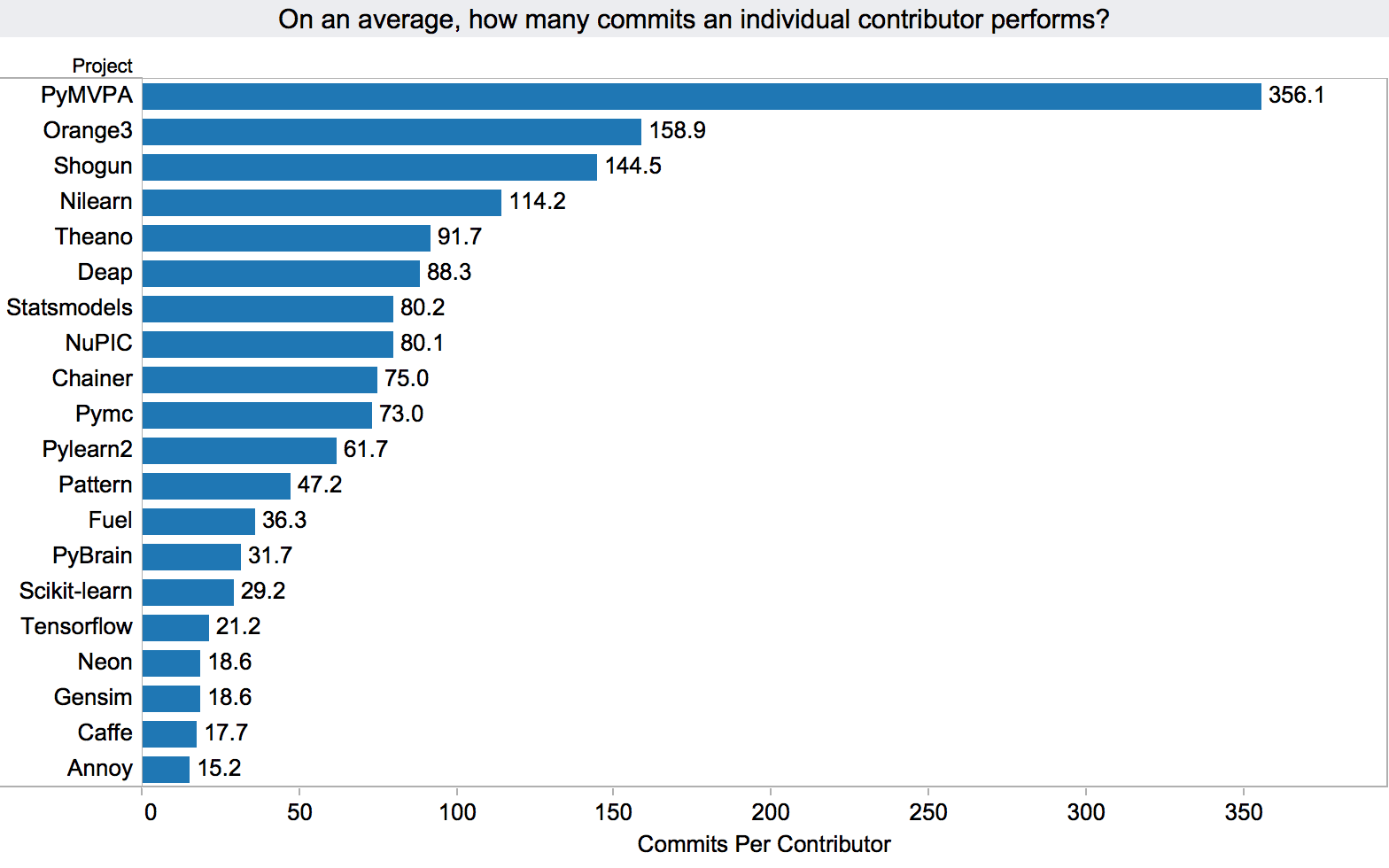
We can see in the following chart that PyMVPA has highest contribution rate compare to all top projects in the list. Surprisingly, Scikit-learn has low contribution rate, despite maximum no. of contributors compare to other projects. Reason behind this could be that, as PyMVPA is a new project and going through early phases of development, leading to many commits because of new ideas/features development, defect fixing, refactoring etc. Whereas, Scikit-learn is old and stable project leading to less no. of improvements or defect fixing.
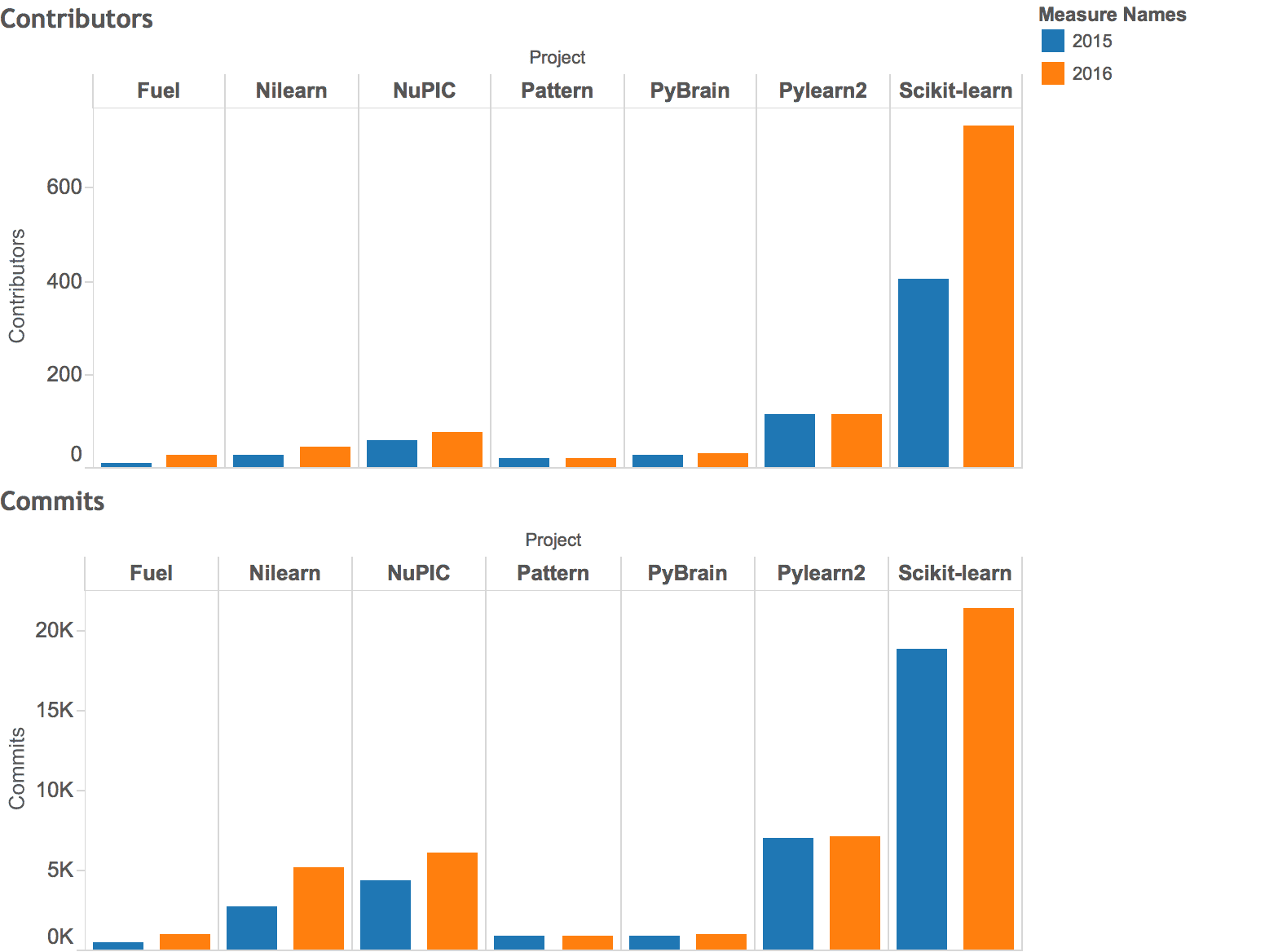
When we compare 2016 and 2015 projects which are part of both Top 20 list, we can see Pattern, PyBrain and Pylearn2 have no major contribution as well as no new contributors. Also, one prominent correlation can be seen in no. of contributors and no. of commits. Increase in contributors may cause increase in commits and I think that’s the magic of open source projects and community; it leads to brainstorming, new ideas and better software tools.
This was the analysis of Top 20 Python Machine Learning Open Source Projects 2016, based on no. of. contributors and no. of commits, by KDnuggets Team – Prasad and Gregory.
Happy Open Sourcing and Knowledge Sharing!
Prasad Pore. [Ln] [Tw] [Fb]
Bio: Prasad Pore is a Business focused Analytics Consultant having 8 years of strong and diverse experience in IT and skills honed in business transformation, data engineering, statistical modelling, machine learning and project management. He holds Masters degree in Data Analytics with specialisation in Business and Bachelor of Engineering degree in Information Technology. He always likes to brainstorm about how technological innovations like mobile apps, IoT, block chain and data analytics can be utilised to help to make better business decisions.
Related: