Web Scraping for Dataset Curation, Part 1: Collecting Craft Beer Data
This post is the first in a 2 part series on scraping and cleaning data from the web using Python. This first part is concerned with the scraping aspect, while the second part while focus on the cleaning. A concrete example is presented.
By Jean-Nicholas Hould, JeanNicholasHould.com.
If you have read some of my posts in the past, you know by now that I enjoy a good craft beer. I decided to mix business with pleasure and write a tutorial about how to scrape a craft beer dataset from a website in Python.
This post is separated in two sections: scraping and tidying the data. In the first part, we’ll plan and write the code to collect a dataset from a website. In the second part, we’ll apply the “tidy data” principles to this freshly scraped dataset. At the end of this post, we’ll have a clean dataset of craft beers.
Web Scraping
A web scraper is a piece of code that will automatically load web pages and pull specific data for you. The web scraper will do a repetitive task that would otherwise be too long for you to manually do.
For example, we could code a web scraper that will pull a list of product names and their rating from an e-commerce website and write them in a CSV file.
Scraping a website is a great way to acquire a new dataset that would otherwise be unavailable.
A few rules on scraping
As Greg Reda pointed out a few years ago in his excellent web scraping tutorial, there are a few rules that you need to know about scraping:
- Respect the website terms & conditions.
- Don’t stress the servers. A scraper can make thousands of web page requests in a second. Make sure you don’t put too much pressure on the server.
- Your scraper code will break.Web pages change often. Your scraper code will be outdated soon.
Planning
The first step in building a scraper is the planning phase. Obviously, you want to decide what data that you want to pull and from which website.
In our case, we want to pull data from a website called CraftCans. This website lists 2692 craft canned beers. For this specific dataset, we wouldn’t need to build a scraper to pull the data. The way it’s laid out, we could easily copy and paste it into an Excel spreadsheet.
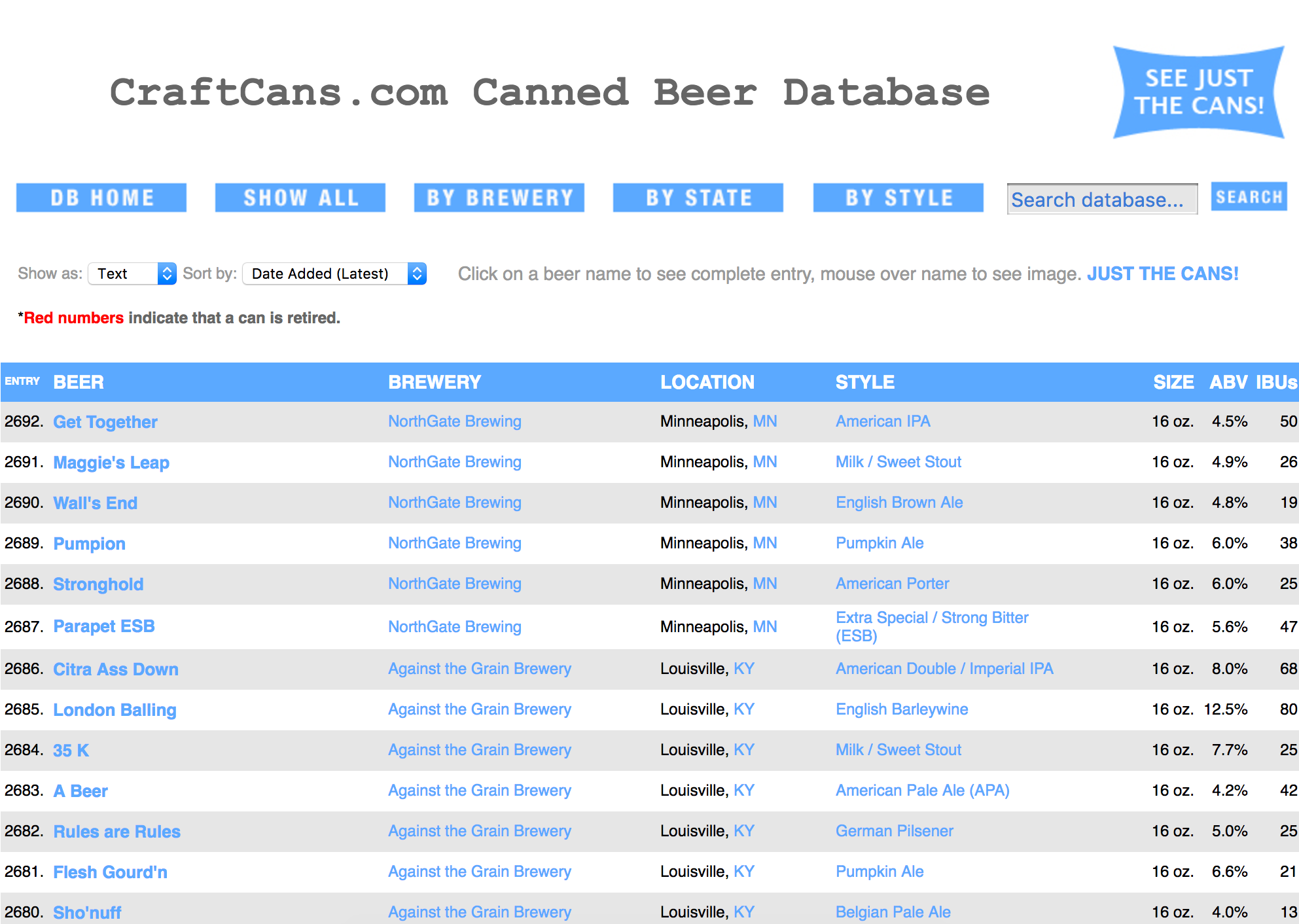
For each beer, the website presents some details:
- Name
- Style
- Size
- Alcohol by volume (ABV)
- IBU’s
- Brewer name
- Brewer location
Inspect the HTML
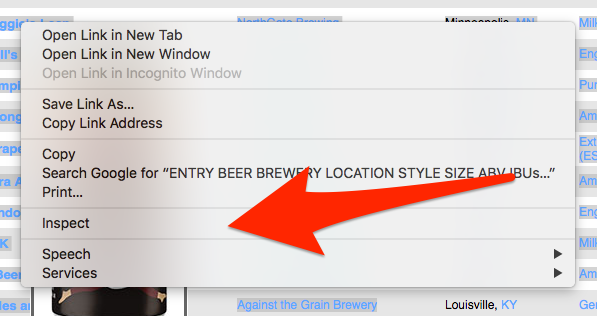
We’d like our scraper to pull all of this information for us. In order to give our scraper specific instructions, we need to look at the HTML code of CraftCans website. Most modern web browser offer a way to inspect the HTML source code of a web page by right click on the page.
On Google Chrome, you can right click on an element in a web page and the click on “Inspect” to see the HTML code.
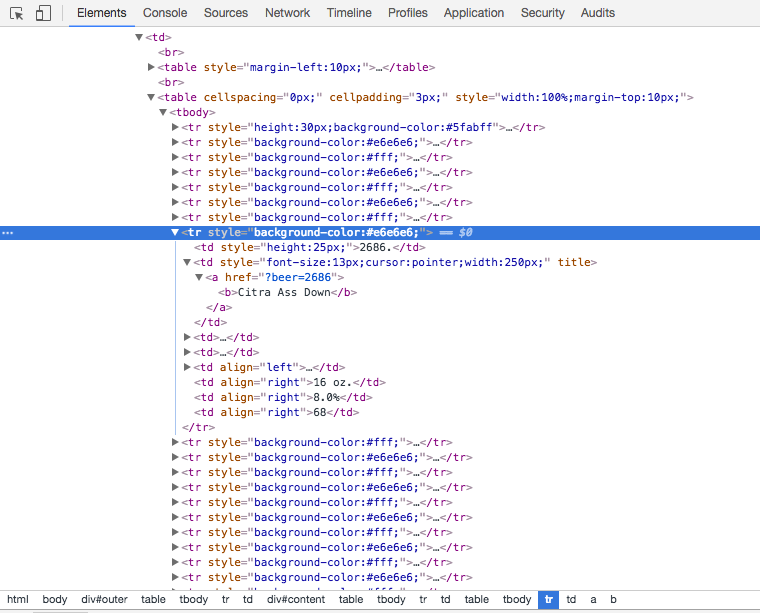
Identify patterns
Looking at the HTML code on the main page, you can see that this big list of beer is in fact an HTML table. Each beer represents a row in this table. Generally, a repeating pattern, such as an HTML table, is ideal for web scraping because the logic is straightforward.
Libraries used
For this project, we’ll import four libraries.
urlopen
The first one urlopen will be used to request an HTML page on the web and return it’s content. That’s it.
BeautifulSoup4
The second one, BeautifulSoup4, is a library that makes it easy to navigate in an HTML document. For example, with this library you can easily select a table in an HTML document and iterate over its rows.
pandas
The third one is pandas. We will not use this library for the scraping part. We will use it for the tidying part. pandas is a library designed to facilitate data manipulation and analysis.
re for regular expressions
Finally, we’ll be using re which is part of the Python Standard Library. This lib provides regular expression matching operations. Regular expressions are ways to manipulate strings. For example, we can use regular expressions to list all of the numbers in a string.
Write the code
Challenges with the HTML
After some investigation on CraftCans web page, I realized there is no clean ways to scrape the CraftCans website.
The HTML structure of CraftCans is kind of old school. The whole layout of the page is in tables. This was a common practice in the past but now the layout is generally set with some CSS.
Furthermore, there are no class or identifiers on the HTML table or rows that contains the beer entries. Pointing the scraper to the specific table that we want is challenging without a clean HTML structure or identifiers.
Solution: List all table rows
The solution I found to scrape the website is most likely not the cleanest but it works.
Since there are no identifiers on the table that contains the data, I use BeautifulSoup4 findAll function to load all of the table rows tr present in the CraftCans page. This function returns an exhaustive list of table rows, whether or not they are from the table we want to scrape.
For each row, I run a test to determine whether or not it’s a row containing a beer entry or if it’s something else. The heuristic to determine if a row is a beer data entry is straightforward: the row needs to contain eight cells and the first cell must contain a valid numeric id.
Now that we have the functions to determine if a row is indeed a beer entry, we can now scrape the whole web page. We need to decide in which format we want to store the collected data from the website. I’d like to have a JSON document like this one for each beer entry in CraftCans.
Example Beer JSON Entry
The reason I like to store the data in JSON document is because I can easily transform them into a pandas DataFrame.
Run the Scraper
Having our functions written, we can then request the CraftCans web page with urlopen and have our code take care of the rest.
With the list of beers returned by get_all_beers, we can easily create a new pandasDataFrame to conveniently visualize and manipulate our data.
Bio: Jean-Nicholas Hould is a Data Scientist from Montreal, Canada. Author at JeanNicholasHould.com.
Original. Reposted with permission.
Related: