Managing Machine Learning Cycles: Five Learnings from comparing Data Science Experimentation/ Collaboration Tools
Machine learning projects require handling different versions of data, source code, hyperparameters, and environment configuration. Numerous tools are on the market for managing this variety, and this review features important lessons learned from an ongoing evaluation of the current landscape.
By Dr. Michael Eble, Co-Founder and Managing Director with hlthfwd.
Machine learning projects come along with handling different versions of input data, source code, hyperparameters, environment configuration, and alike. Usually, many model iterations need to be computed before machine learning models can be leveraged in production.
During this experimentation process, its artefacts and their interdependencies create an additional layer of complexity in data science projects. In order to manage this complexity, we need proper structures and processes as well as adequate software tools that cover the machine learning cycle.
In case you are experiencing similar challenges, the following learnings from comparing such tools might be useful for you. You can find a link to our raw data at the end of the article.
Problem statement and Use cases
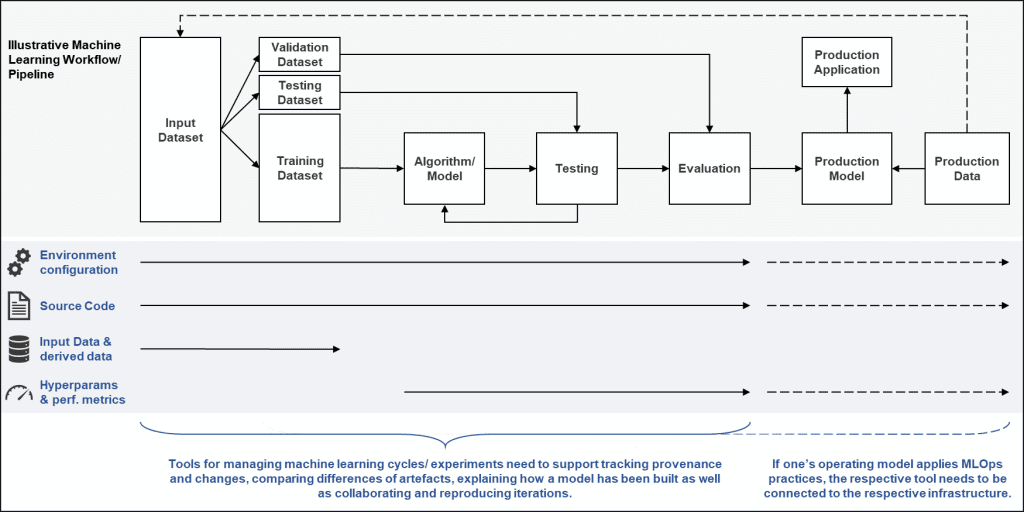
For us, the respective tool needs to cover the following use cases alongside a typical machine learning workflow:
- During machine learning cycles, we need to track provenance and changes of input data, source code, environment config, hyperparameters, and performance metrics.
- Furthermore, we need to compare differences of artefacts, in order to analyse the effects of different approaches.
- In addition, we need to be able to explain internally and externally how a model that eventually ends up in production has been built in the first place.
- Finally, being able to collaborate and reproduce iterations is important (even or especially when team members leave a project/ company).
Tools considered or excluded

We determined AI, dotscience, MLFlow, and Polyaxon target larger corporations/ enterprises, while Comet.ml, Neptune.ml as well as Weights and Biases address smaller organizations/ start-ups.
Selection criteria
- Libraries and frameworks supported: Which machine learning/ deep learning frameworks and libraries (within the Python ecosystem) does the tool work with? So far, we mainly use TensorFlow and Keras. However, switching to Caffe2 and PyTorch is possible.
- Integration with infrastructure: Which types of infrastructure does the tool support? This is relevant for bringing models to production and for enabling migration paths from Google to Amazon, for instance.
- Tracking of metrics and parameters: Which performance measures (e. g. accuracy) does the tool log? Which additional metadata does it track? This criterion covers hyperparameters (e. g. batch size), environment configuration, etc.
- Additional features: Does the tool keep track of changes in input data, code, etc.? Which approaches to automated hyperparameter optimization does it offer? What about features for exporting and sharing experiment data within a team?
- Commercial model/ community: Tools are available as open-source versions and/ or as commercial versions. With respect to open source, how active is the respective GitHub repo being maintained? In the case of commercial offers, how does the business model look like?
Learnings from the selection process
- Libraries and frameworks supported: All tools considered to support TensorFlow and Keras. In most cases (8 out of 10), scikit-learn is supported, too. When it comes to Caffe2 and PyTorch, only Comet.ml and Polyaxon seem to support these. Some tools come with additional support for MXNet, Chainer, Theano and others.
- Integration with infrastructure: Nearly all tools cover a wide range of infrastructure components – from AWS, AML, and GCP to Docker and Kubernetes. Especially MLFlow, Neptune.ml and Polyaxon address various needs. However, none of the tools seems to support CNTK. Tools allow for deployment on-premise or PaaS/ SaaS, and some offer both.
- Tracking of metrics and parameters: All tools keep track of usual performance metrics (accuracy, loss, training time, etc.) and hyperparameters (batch size, number of layers, optimizer name, learning rate etc.). MLFlow, for example, also allows for user-defined metrics. Visualization of model graphs and alike is possible within several tools.
- Additional features: Viewing code and data source differences is common – Comet.ml, dotscience, Guild and MLFlow offer this functionality, just to name a few. At least in four cases, this includes integration with GitHub repos. Five tools offer hyperparameter optimization based on Grid, Random, Bayes, Adaptive and/ or Hyberband search approaches. With respect to sharing and collaborating, Jupyter and proprietary data spaces are the interfaces of choice.
- Commercial model/ community: Comet.ml, Determined AI, dotscience, Neptune.ml, as well as Weights and Biases, are offered under a proprietary license and a corresponding payment scheme. Guild, MLFlow, Sacred and StudioML are Open Source – either under Apache 2.0 or MIT license. Stemming from the number of contributors, forks, watchers and stars on GitHub, MLFlow seems to have the most active community. Polyaxon offers both a commercial version and an open-source version of its software.
Data collection and data sources/ references
Information about the tools was collected in Q3 and Q4/2019 and updated gradually. We did not yet fully complete hands-on tests of all tools on our shortlist but reviewed relevant websites, GitHub repos and documentation. Further investigation is carried out with respect to data visualization, location of servers (in case of PaaS/ SaaS), among others.
You can download the full spreadsheet containing more detailed data about each of the tools from GitHub.
Bio: Dr. Michael Eble is co-founder of a digital health start-up in Germany and is responsible for its data-driven business models. Prior to his current position, Michael was Principal at the management consulting firm mm1 and head of the consultancy’s practice “Data Thinking.” He led project teams for clients in various industries such as telecommunication and mobility with a focus on new product development. Michael holds a M.A. in economics and management and a M.A. in computational linguistics and media studies. He received his doctoral degree from the University of Bonn while executing data analytics projects at Fraunhofer institute IAIS. Michael is currently completing his studies in computer science and is writing his master’s thesis about machine learning in the medical field.
Related: