3D Human Pose Estimation Experiments and Analysis
In this article, we explore how 3D human pose estimation works based on our research and experiments, which were part of the analysis of applying human pose estimation in AI fitness coach applications.
By Maksym Tatariants, Data Science Engineer at MobiDev
The basic idea of human pose estimation is understanding people’s movements in videos and images. By defining keypoints (joints) on a human body like wrists, elbows, knees, and ankles in images or videos, the deep learning-based system recognizes a specific posture in space. Basically, there are two types of pose estimation: 2D and 3D. 2D estimation involves the extraction of X, Y coordinates for each joint from an RGB image, and 3D - XYZ coordinates from an RGB image.
In this article, we explore how 3D human pose estimation works based on our research and experiments, which were part of the analysis of applying human pose estimation in AI fitness coach applications.
How 3D Human Pose Estimation Works
The goal of 3D human pose estimation is to detect the XYZ coordinates of a specific number of joints (keypoints) on the human body by using an image containing a person. Visually 3D keypoints (joints) are tracked as follows:
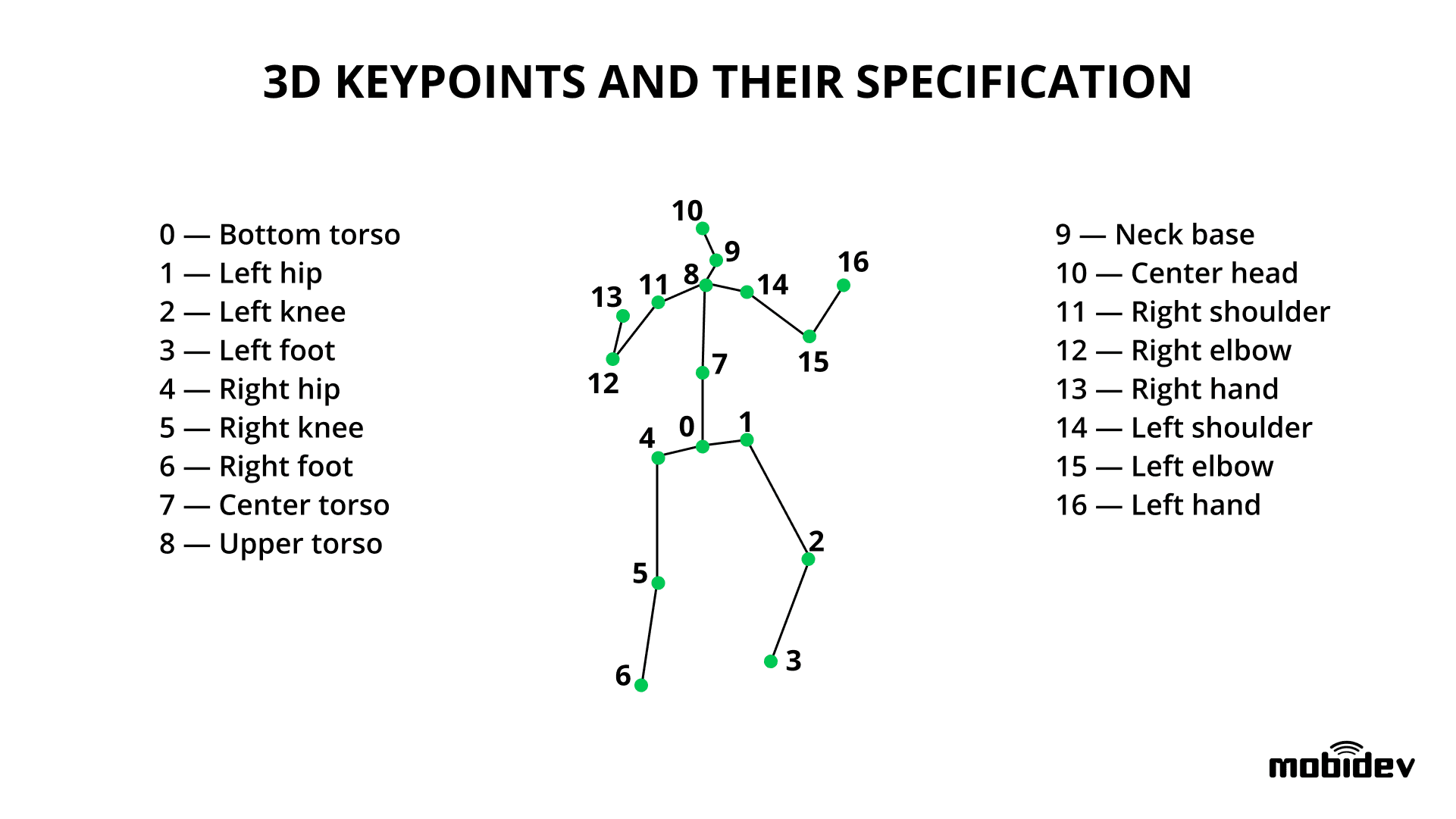
Once the position of joints is extracted, the movement analysis system checks the posture of a person. When keypoints are extracted from a sequence of frames of a video stream, the system can analyze the person’s actual movement.
There are multiple approaches to 3D human pose estimation:
- To train a model capable of inferring 3D keypoints directly from the provided images.
For example, a multi-view model EpipolarPose is trained to jointly estimate the positions of 2D and 3D keypoints. The interesting thing is that it requires no ground truth 3D data for training - only 2D keypoints. Instead, it constructs the 3D ground truth in a self-supervised way by applying epipolar geometry to 2D predictions. It is helpful since a common problem with training 3D human pose estimation models is a lack of high-quality 3D pose annotations. - To detect the 2D keypoints and then transform them into 3D.
This approach is the most common because 2D keypoint prediction is well-explored and usage of a pre-trained backbone for 2D predictions increases the overall accuracy of the system. Moreover, many existing models provide decent accuracy and real-time inference speed (for example, PoseNet, HRNet, Mask R-CNN, Cascaded Pyramid Network).
Regardless of the approach (image →2D →3D or image → 3D), 3D keypoints are typically inferred using single-view images. Alternatively, it’s possible to exploit multi-view image data where every frame is captured from several cameras focused on the target scene from different angles.

The multi-view technique allows for improved depth perception and helps in those cases when some parts of the body are occluded in the image. As a result, predictions of models become more accurate.
Normally this method requires cameras to be synchronized. However, some authors demonstrate that even the video stream from multiple unsynchronized and uncalibrated cameras can be used to estimate 3D joint positions. For example, in the Human Pose as Calibration Pattern paper is described that the initial detections from uncalibrated cameras can be optimized using the external knowledge on the natural proportions of the human body and relaxed reprojection error to obtain the final 3D prediction.
How Human Pose Estimation Model Detects and Analyze Movements
We took a realistic situation of application development for an AI fitness coach. In this scenario, users should capture themselves while doing an exercise, analyze how correct it is performed by using the app, and review the mistakes made during the exercise performance.
It is the case when complicated multi-camera setup and depth sensors are not available. Thereby, we chose the VideoPose3D model since it works with simple single-view detections. VideoPose3D belongs to a convolutional neural networks (CNNs) family and employs dilated temporal convolutions (see the illustration below).

As an input, this model requires a set of 2D keypoint detections, where the 2D detector is pre-trained on the COCO 2017 dataset. By utilizing the information from multiple frames taken at different periods, VideoPose3D essentially makes a prediction based on the data about the past and the future position of joints, which allows a more accurate prediction of the current joints’ state and partial resolution of the uncertainty issues (for example, when the joint is occluded in one of the frames, the model can “look” at the neighbouring frames to resolve the problem).
In order to explore the capabilities and limitations of the VideoPose3D, we applied it for analysis of powerlifting and martial arts exercises.
Spine Angle Detection
The spine angle is one of the most important things to be analyzed when squatting. Keeping the back straight is important in this exercise since the more you lean forward, the more the center of mass (body + barbell) is shifted forward (it can be a very bad thing since the shifted center of mass causes extra load on the spine).
To measure the angle, we treated the spine (start keypoint 0, end keypoint 8) as a vector and measured the angle between the vector and the XY plane by taking arccos of cosine similarity equation. In the video below, you can see how the model detects the spine angle on an example video. As you can see, when squatting up with incorrect form, the angle can be as small as 28-27°.

https://youtu.be/yZv-qoKfmqk
When looking at the video where the exercise is executed correctly (see the video below), we can say that the angle is not going below ~47°. It means that the selected method can correctly detect the spine angle when squatting.

https://youtu.be/ikQhw9pNMy4
Detection of Exercise Start and End
To be able to automatically analyze only the active phase of the exercise or detect its duration, we investigated the process of automatic detection of the exercise start and end.
Since squatting with a barbell requires the specific positioning of arms, we decided to use their position as a reference for detection. When squatting, both arms are typically bent at an angle < 90°, and hands are positioned near shoulders (by height). By using some arbitrary thresholds (in our case, we chose angle < 78° and distance < 10% from max z-axis value), we can detect this condition as shown below.

https://youtu.be/KjtXIoX-KSo
In order to see if the condition and thresholds are held up during the exercise, we analyzed another video from a different perspective and reviewed how the system may work during the exercise when the detection is already started. It turned out that the observed parameters remained far below the selected thresholds.

We also checked how the condition works when the person finishes the exercise and saw that once the barbell is dropped off, the false condition is immediately triggered. And finally, we concluded that this method works well, although it has some nuances (described in the Errors and Possible Solutions in Human Pose Estimation Technology section).

Detection of Knee Caving
Knee valgus or knee caving is a common mistake in squatting. This problem is often encountered in squatting when an athlete reaches the bottom point and begins squatting up. The incorrect technique may cause severe wear of knee joints and lead to snapped tendons or replacement of knee cups.
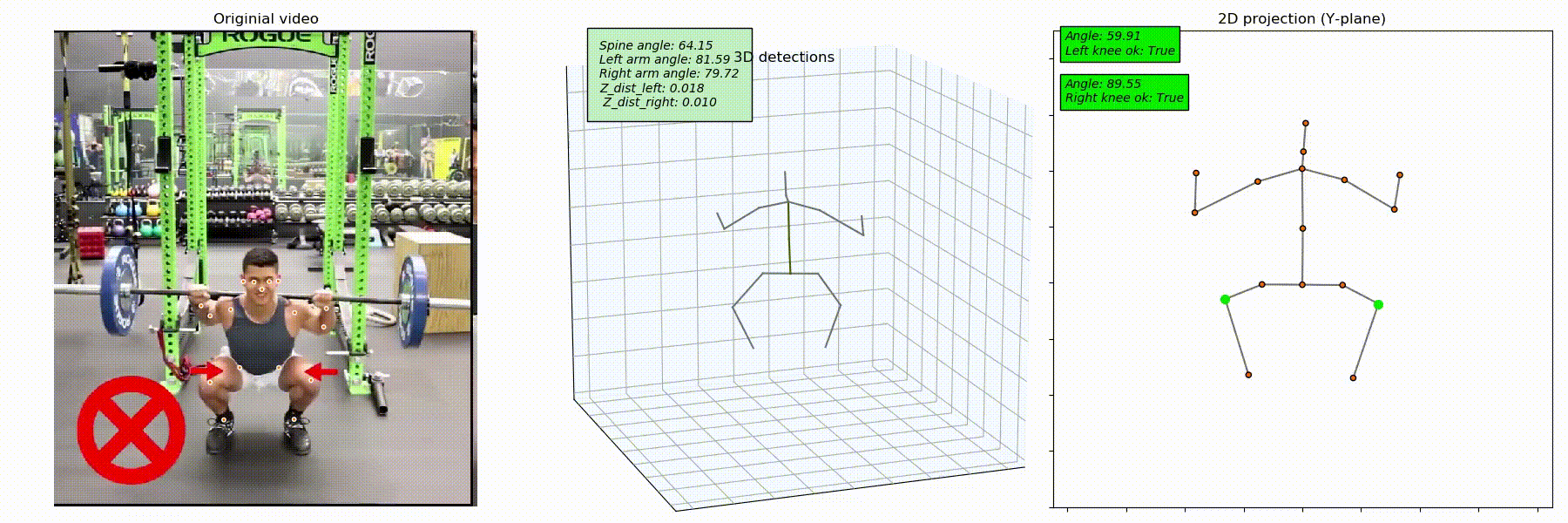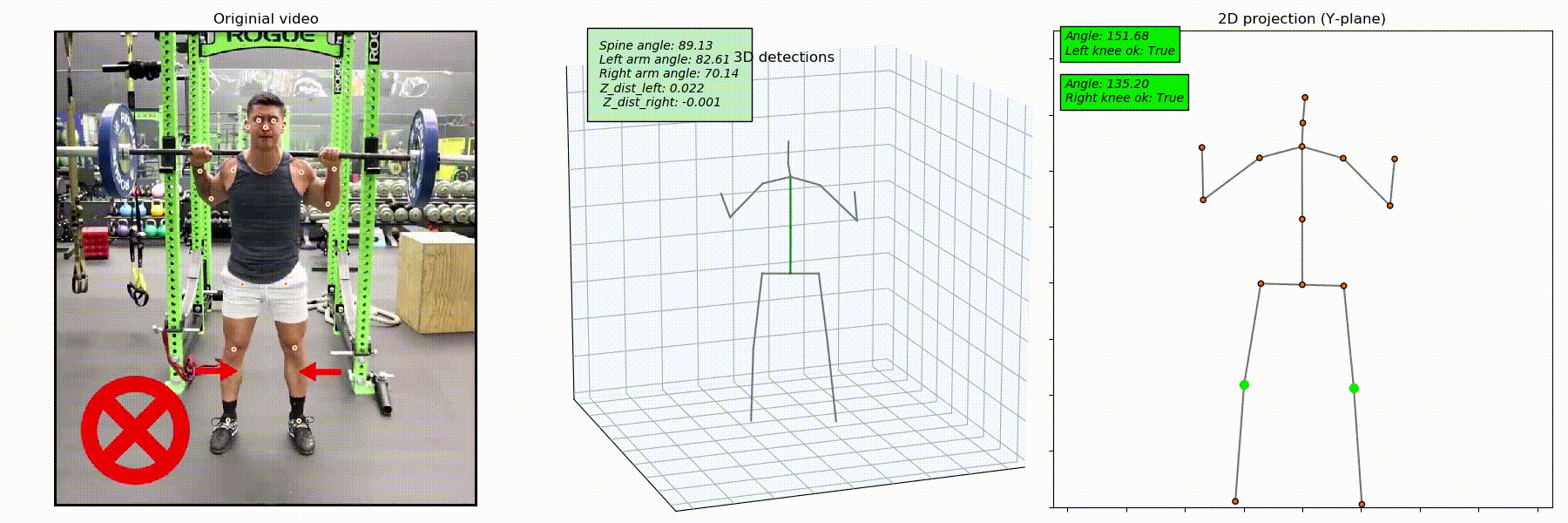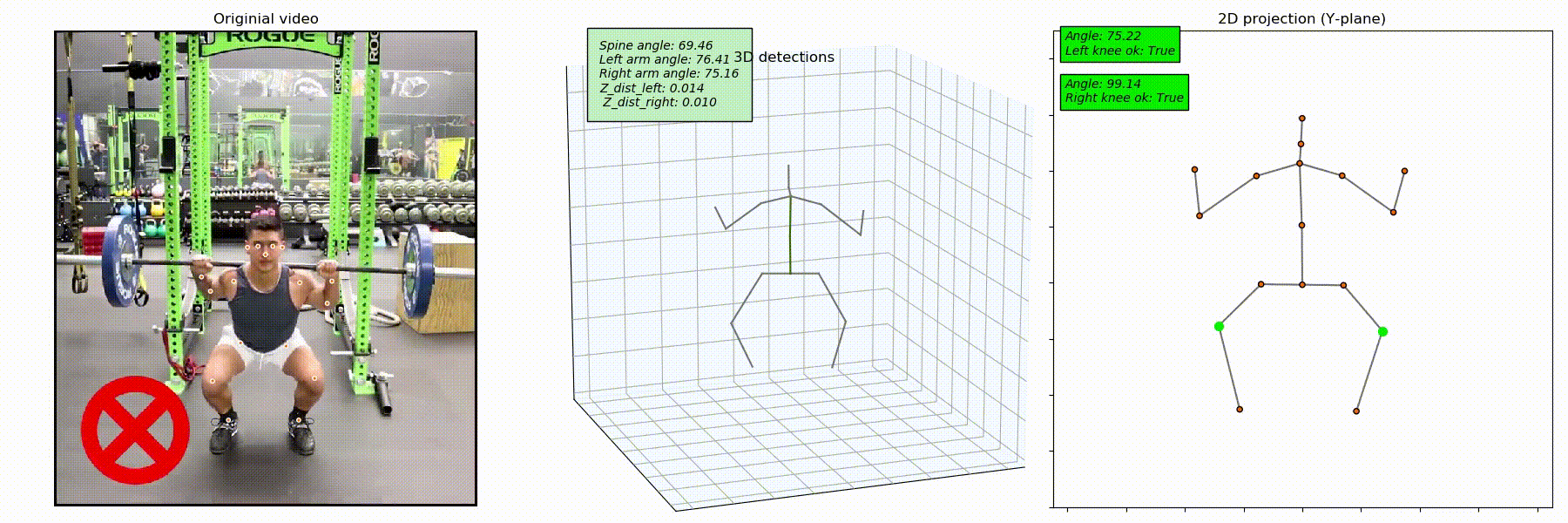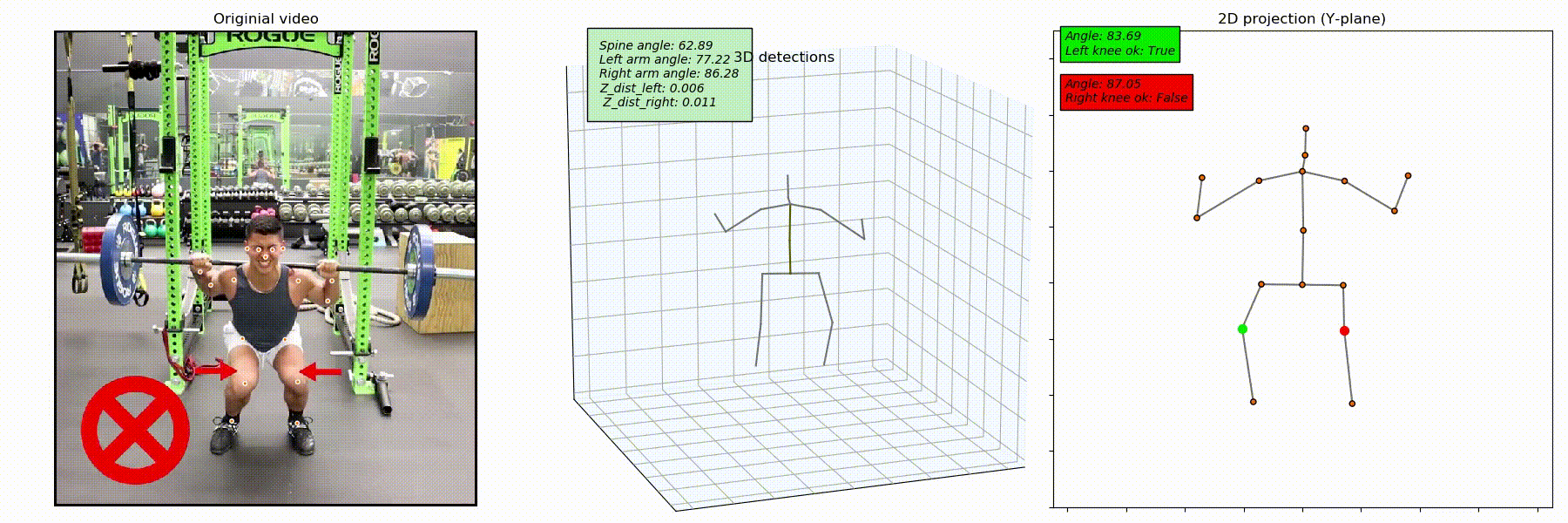
To see how the model detects the knee caving mistake, we captured the joints' 3D position. Since the resulting skeleton (see the image below) can be positioned randomly, we rotated it along the Z-axis to align it with one of the planes.

After that, we projected the 3D keypoint onto the plane and started tracking the position of knees as to the position of feet. The goal was to detect situations when legs are bent, and knees are closer to the center torso than feet.
From the image below, you can see that the incorrect position of knees is well-detected, meaning that this method works well.
Comparison of Two Athletes in Powerlifting and Snatch
Another interesting application of 3D human pose estimation technology is the comparison between the movements of two people. Having the goal to improve an exercise technique, athletes may use the human pose estimation-based app to compare themselves with more experienced athletes. In order to do so, it is required to have a “gold standard” video with a record of a particular movement, and use it to evaluate similarities and differences based on body parts localization.
For such comparison, we took the video of the athlete performing the snatch with start and end tags. The goal was to speed it up or slow down for synchronization with the beginning and the end of the target (“gold standard”) video. The process looked as follows:
- Detection of the 3D keypoints position for both videos
- Aligning of keypoints so that “skeletons” have the same center point and being rotated similarly
- Analysis of distances between different joints frame by frame

https://youtu.be/34z5FI5ldyE
As a result, we discovered that the accurate detection of a human pose during the fast and abrupt movement stretches the limits of a single-view detection method. The network predicts the move better when more frames are available, which is not the case with ~2-sec move (at least if you have 30 fps video).
Deadlift - Reps Counter
If you were wondering if 3d human pose estimation could be used to count repetitions in an exercise, we have prepared an example based on the deadlift exercise showing how you can determine the number of repetitions and also exercise phase (going up or going down) in an automatic manner. In the image below you can see that we can detect when the person is going up as well as quite reliably count the number of repetitions.

https://youtu.be/zX51qbBCiLM
We achieved that by, first of all, considering how we can define one repetition. Basically, one repetition in deadlifting is when the initially bent forward person begins ascending, reaches a vertical position, and begins to descend again. Therefore we need to look for a spot in time when a group of consecutive “going up” frames is followed by a group of also consecutive “going down” frames. The edge frame between the two groups will be the spot where we can add one repetition to our counter.
In terms of practical implementation, the key to finding going up and down frames is the spine angle, which we already know how to detect. While using it, we can go through all the detected frames and compare the spine angles in the neighboring frames. As a result, we will get a vector of 1s and 0s where continuous stretches of 1s can represent ascent and 0s - descent.

Obviously, these detections will need a small cleanup to remove accidental detections and oscillations. It can be done by going over the data using a sliding window of relatively small-size (4-5) frames and replacing all the values inside the window with a majority value.


After the cleanup is done, we can move on to detecting the actual edge frames where the person finished one repetition. It is surprisingly simple, as we can apply a convolutional filter (kernel) used for edge detection.

As a result, when approaching the edge frame, the values begin to grow and become either positive or negative (depending on the edge type). Since we are looking for going up|going down the edge, we need to find indices of all the frames where the value of the filter is -50 (maximum) and then, we will know when to add repetitions.
Errors and Possible Solutions in Human Pose Estimation
Squatting Start Detection Error
Problem: At first glance, it may seem that squatting start detection works appropriately, however, the arbitrary threshold gives an error when one of the arms’ angles briefly goes above it.

Solution: We could increase the threshold to avoid the error in the particular video, but there is no guarantee that processing other videos won’t result in the same error. It means that it is necessary to test the model by using a number of different examples to establish a proper set of rules.
Frontal Perspective Error
Problem: When processing unusual movements and strictly frontal views, the model tends to produce low-quality results, especially for keypoints on legs. The possible reason for this issue is the fact that the Human3.6M dataset used for training of the VideoPose3D is, despite its size, still limited in terms of poses, moves, and perspectives. As a result, the model does not generalize to the presented data (which falls far out of the learned distribution) accurately. Comparatively, the same movement is predicted better when the view has a non-frontal perspective.

https://youtu.be/Za1GPq6sHUk
Solution: The problem can be solved by fine-tuning the model on the domain-specific data. Alternatively, you can utilize synthetic data for training (such as animated 3D models rendered with realistic render), or encode the external knowledge about the skeletal system into the loss function.
Unusual Movements Error
Problem: When working with 3D human pose estimation, we found out that the 2D detection part may cause a low prediction accuracy.

https://youtu.be/Gu_H3s7eel0
The Keypoint R-CNN model detects the position of quickly moving legs incorrectly, which can be partially attributed to the blurring of leg features caused by the fast transition.
In addition, this kind of limb position is not very similar to what can be found in the COCO 2D keypoint dataset used for pre-training the model. As a result, the 3D model predictions for the lower body part do not correspond to the real movement, while the upper part of the body looks correct since the upper limbs have more degrees of freedom than legs on the images used for model training.
Solution:
- Collecting and labeling of own dataset which would contain images from the target domain. Despite improving the model’s performance on the target domain, this approach may be prohibitively costly to implement.
- Using train-time augmentations to make the model less sensitive to rotations of the human body. This approach requires the application of random rotations to the training images and all the keypoints within. It will definitely help when predicting unusual poses, however, it may not be very helpful when detecting those poses that cannot be obtained by simple rotation like bending over, or high kicks.
- Adoption of rotation-invariant models, capable of inferring the position of keypoints regardless of the rotation degree of the body. It can be done by training an additional rotation network aimed to find the rotation angle needed to transform a given image to a canonical view. Once the network is trained, it can be integrated into the inference pipeline so that the keypoint detection model receives only angle-normalized images.
Occluded Joints Error
Problem: The 2D predictor may return poor results when body parts are occluded with other body parts or objects. When weights on barbells obscure the position of hands in powerlifting, the detector may “misfire,” placing the keypoint far from its true position. It leads to instability of 3D keypoint models’ output and “shaky hands” effect.

https://youtu.be/1rg1lj-eAaw
Solution: It is possible to use multi-view systems to get better accuracy since they can significantly reduce the occlusion problem. There are also 2D keypoint localization models designed specifically to deal with occlusions.
In conclusion, I'd say that based on our practical findings, most weaknesses of the 3D human pose estimation technology are avoidable. The main task is to select the right model architecture and training data. Moreover, the rapid developments in 3D human pose estimation indicate that current obstacles may become less of an issue in the future.
Bio: Maksym Tatariants is a Data Science Engineer at MobiDev. He has a background in Environmental and Mechanical Engineering, Materials Science, and Chemistry, and is keen on gaining new insights and experience in the Data Science and Machine Learning sectors. He is particularly interested in Deep Learning-based technologies and their application to business use cases.
Related:
- A 2019 Guide to Human Pose Estimation
- Metrics to Use to Evaluate Deep Learning Object Detectors
- Are Computer Vision Models Vulnerable to Weight Poisoning Attacks?