Interesting Social Media Datasets
Learn about some of the many interesting social media datasets available to you, some of which are quite new, and the different features and challenges they offer you for your next big data science project.
By Grant Marshall, Aug 2014
Before conducting any major data science project or knowledge discovery research, a good first step is to acquire a robust dataset to work with. One of the benefits of the social media explosion that has taken place in recent years is that with it has come a profusion of large, free, open data sets, often accompanied by graph/network information and large amounts of metadata. If you’re interested in text analytics, graphical models, computer vision, or just need a huge amount of data to stress test your new algorithm/procedure, social media data can be a great resource.

Another important criterion to remember is the specific constraints placed on the data based on the particular social media site in question. For example, Twitter artificially imposes a 140 character limit on tweets that can make tasks like sentiment analysis and parts of speech tagging challenging, though there are some tools designed specifically for these challenges. Just make sure to keep these restrictions in mind before committing to a dataset.
Now where would you get such datasets? There are a couple of sources that contain a variety of datasets to experiment with:
There are many more specific datasets available as well:

Grant Marshall, is a Research Assistant at Arizona State University, working on Data Mining and Machine Learning projects. He won ASU President's Award for Innovation for his work on the TweetTracker system.
Related:
Before conducting any major data science project or knowledge discovery research, a good first step is to acquire a robust dataset to work with. One of the benefits of the social media explosion that has taken place in recent years is that with it has come a profusion of large, free, open data sets, often accompanied by graph/network information and large amounts of metadata. If you’re interested in text analytics, graphical models, computer vision, or just need a huge amount of data to stress test your new algorithm/procedure, social media data can be a great resource.

Word cloud of the monthly hashtag dataset from the Infochimps Twitter Census
Not all social media data is created equal, however. Whether a particular dataset is a good match for your project depends on what kind of relationships you want to model. Probably the most obvious differentiator between social networks is whether their relationships are directed (think follower/followee on Twitter) or undirected (think friends on Facebook). Depending on the type of model you want to use, and the question you want to ask, this can be relevant and you should consider this when choosing a dataset.Another important criterion to remember is the specific constraints placed on the data based on the particular social media site in question. For example, Twitter artificially imposes a 140 character limit on tweets that can make tasks like sentiment analysis and parts of speech tagging challenging, though there are some tools designed specifically for these challenges. Just make sure to keep these restrictions in mind before committing to a dataset.
Now where would you get such datasets? There are a couple of sources that contain a variety of datasets to experiment with:
- The Stanford Large Network Dataset Collection (SNAP) is an excellent resource because not only does it have a wide range of datasets from different sources, but it also has datasets of varying size, which can be useful depending on your applications. SNAP is also a library that allows for easy integration and analysis of large networks in general, including the SNAP datasets.
- The Social Computing Data Repository is a similar resource to SNAP, providing a large variety of datasets from multiple sources and of varying sizes. Between this and SNAP, many will find their data needs satisfied.
- For any kind of Twitter data, Infochimps has a fantastic “Twitter Census” that provides almost a number of useful datasets derived from 35 million tweets. Infochimps also have other social media datasets available under a variety of different licenses.
There are many more specific datasets available as well:
- If you have a computer vision project in mind, take a look at Yahoo Labs’s One Hundred Million Creative Commons Flickr Images for Research dataset. Another benefit of this dataset is that many of the images are geotagged, enabling some interesting explorations of the intersection of geographical and image features.
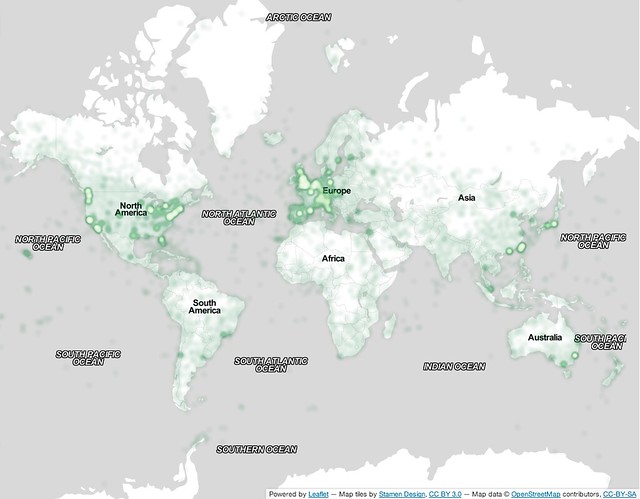
Visualization of 1 million out of 48 million geotagged photos from the Yahoo Labs Flickr dataset. Credit David Shamma
- For any network topology research, why not give the Social Computing Research @ MPI-SWS datasets a shot? They have been used successfully before for exactly that purpose.
- The Yelp Dataset Challenge, a social review dataset including a nearly 1 million edge social graph. Also part of the currently ongoing Yelp Dataset Challenge, which may be of interest to you.
- The Wikipedia Data Dump, which provides a huge mass of text data and linked articles that could be useful for text analytics on highly-curated text with multiple languages available from the same source.
Grant Marshall, is a Research Assistant at Arizona State University, working on Data Mining and Machine Learning projects. He won ASU President's Award for Innovation for his work on the TweetTracker system.
Related:
- Top KDnuggets tweets, May 30 – Jun 1: Guide to Setting Up an R-Hadoop ; 100+ Interesting Data Sets
- US Open Data Action Plan and Datasets
- Top KDnuggets tweets, Mar 21-23: Machine Learning in Parallel with SVM; Good Data Sets for Data Science Practice
- Data for Good: data-driven projects for social good