Big Idea To Avoid Overfitting: Reusable Holdout to Preserve Validity in Adaptive Data Analysis
Big Data makes it all too easy find spurious "patterns" in data. A new approach helps avoid overfitting by using 2 key ideas: validation should not reveal any information about the holdout data, and adding of a small amount of noise to any validation result.
First, the validation should not reveal any information about the holdout dataset if the analyst does not overfit to the training set.
Second, an addition of a small amount of noise to any validation result can prevent the analyst from overfitting to the holdout set.
To illustrate the benefits of using our approach, we showed how it prevents overfitting in a setting inspired by Freedman’s paradox. In this experiment, the analyst wants to build an algorithm that can accurately classify data points into two classes, given a dataset of correctly labeled points. The analyst first finds a set of variables that have the largest correlation with the class. However, to avoid spurious correlations, the analyst validates the correlations on the holdout set and uses only those variables whose correlation agrees with the correlation on the training set. The analyst then creates a simple linear threshold classifier on the selected variables.
We tested this procedure on a dataset of 20,000 points in which the values of 10,000 attributes are drawn independently from the normal distribution, and the class is chosen uniformly at random. There is no correlation between the data point and its class label and no classifier can achieve true accuracy better than 50%. Nevertheless, reusing a standard holdout leads to reported accuracy of over 63±0.4% (when selecting 500 out of 10,000 variables) on both the training set and the holdout set.
We then executed the same algorithm with our Thresholdout algorithm for holdout reuse. Thresholdout prevents the algorithm from overfitting to the holdout set and gives a valid close to 50% estimate of classifier accuracy. In the plot below we show the accuracy on the training set and the holdout set (the green line) obtained for various numbers of selected variables averaged over 100 independent executions. For comparison the plot also includes the accuracy of the classifier on another fresh data set of 10,000 points which serves as the gold standard for validation.
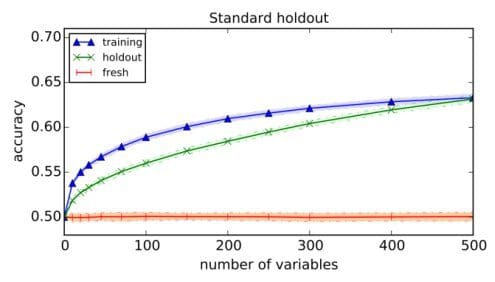
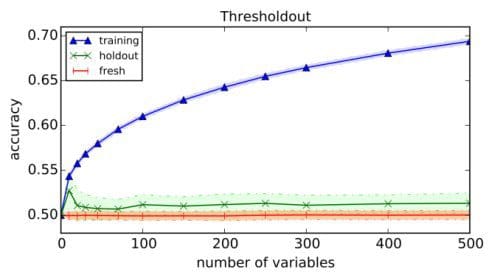
Beyond this illustration, the reusable holdout gives the analyst a simple, general and principled method to perform multiple validation steps where previously the only known safe approach was to collect a fresh holdout set each time a function depends on the outcomes of previous validations. We are now looking forward to exploring the practical applications of this technique.
Bio:  Vitaly Feldman is a Research scientist at IBM Almaden Research Center, San Jose, CA. Before joining IBM he spent 5 very enjoyable years at Harvard University as a PhD student advised by Leslie Valiant and as a postdoc. He received BA and MS in Computer Science from Technion and worked at IBM Research in Haifa.
Vitaly Feldman is a Research scientist at IBM Almaden Research Center, San Jose, CA. Before joining IBM he spent 5 very enjoyable years at Harvard University as a PhD student advised by Leslie Valiant and as a postdoc. He received BA and MS in Computer Science from Technion and worked at IBM Research in Haifa.
- How to Lead a Data Science Contest without Reading the Data
- Overcoming Overfitting with the reusable holdout: Preserving validity in adaptive data analysis
- Data Science 101: Preventing Overfitting in Neural Networks
- 11 Clever Methods of Overfitting and how to avoid them