Recurrent Neural Networks Tutorial, Introduction
Recurrent Neural Networks (RNNs) are popular models that have shown great promise in NLP and many other Machine Learning tasks. Here is a much-needed guide to key RNN models and a few brilliant research papers.
Machine Translation
Machine Translation is similar to language modeling in that our input is a sequence of words in our source language (e.g. German). We want to output a sequence of words in our target language (e.g. English). A key difference is that our output only starts after we have seen the complete input, because the first word of our translated sentences may require information captured from the complete input sequence. 
Fig. 2 RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
Research papers about Machine Translation:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
Speech Recognition
Given an input sequence of acoustic signals from a sound wave, we can predict a sequence of phonetic segments together with their probabilities. Research papers about Speech Recognition:
Generating Image Descriptions
Together with convolutional Neural Networks, RNNs have been used as part of a model to generate descriptions for unlabeled images. It’s quite amazing how well this seems to work. The combined model even aligns the generated words with features found in the images. 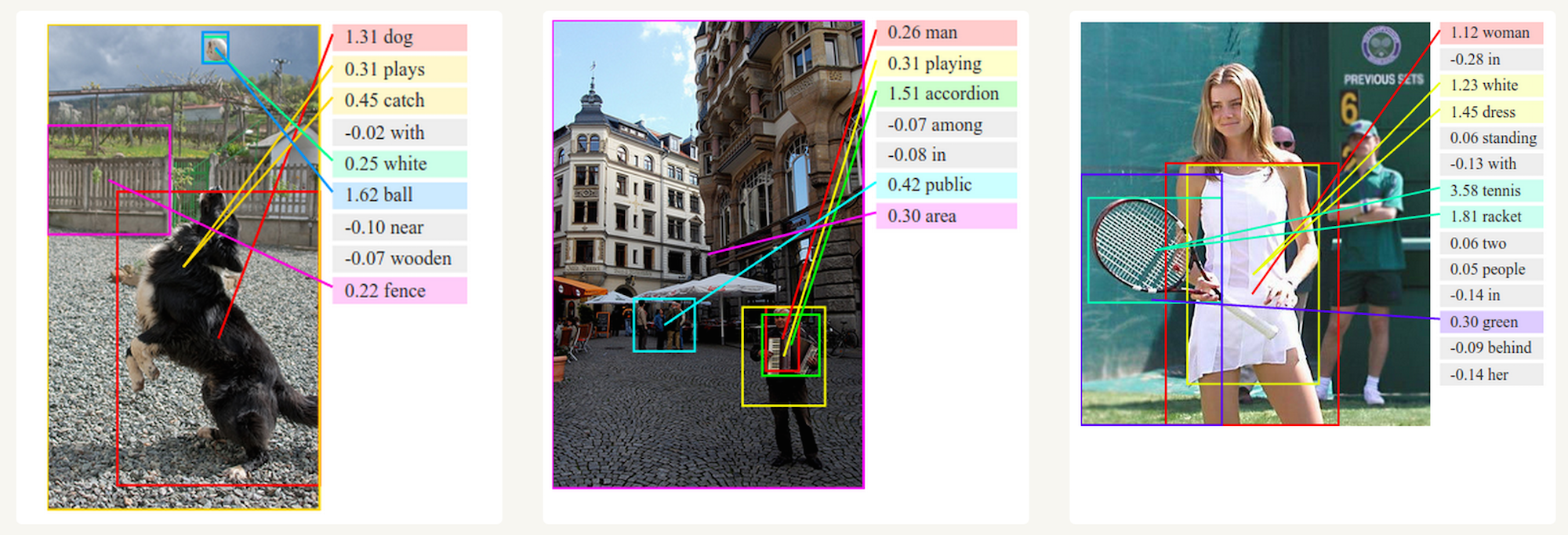
Fig. 3 Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
Training RNNs
Training a RNN is similar to training a traditional Neural Network. We also use the backpropagation algorithm, but with a little twist. Because the parameters are shared by all time steps in the network, the gradient at each output depends not only on the calculations of the current time step, but also the previous time steps. For example, in order to calculate the gradient at  we would need to backpropagate 3 steps and sum up the gradients. This is called Backpropagation Through Time (BPTT). If this doesn’t make a whole lot of sense yet, don’t worry, we’ll have a whole post on the gory details. For now, just be aware of the fact that vanilla RNNs trained with BPTT have difficulties learning long-term dependencies (e.g. dependencies between steps that are far apart) due to what is called the vanishing/exploding gradient problem. There exists some machinery to deal with these problems, and certain types of RNNs (like LSTMs) were specifically designed to get around them.
we would need to backpropagate 3 steps and sum up the gradients. This is called Backpropagation Through Time (BPTT). If this doesn’t make a whole lot of sense yet, don’t worry, we’ll have a whole post on the gory details. For now, just be aware of the fact that vanilla RNNs trained with BPTT have difficulties learning long-term dependencies (e.g. dependencies between steps that are far apart) due to what is called the vanishing/exploding gradient problem. There exists some machinery to deal with these problems, and certain types of RNNs (like LSTMs) were specifically designed to get around them.
RNN Extensions
Over the years researchers have developed more sophisticated types of RNNs to deal with some of the shortcomings of the vanilla RNN model. We will cover them in more detail in a later post, but I want this section to serve as a brief overview so that you are familiar with the taxonomy of models.
Bidirectional RNNs are based on the idea that the output at time  may not only depend on the previous elements in the sequence, but also future elements. For example, to predict a missing word in a sequence you want to look at both the left and the right context. Bidirectional RNNs are quite simple. They are just two RNNs stacked on top of each other. The output is then computed based on the hidden state of both RNNs.
may not only depend on the previous elements in the sequence, but also future elements. For example, to predict a missing word in a sequence you want to look at both the left and the right context. Bidirectional RNNs are quite simple. They are just two RNNs stacked on top of each other. The output is then computed based on the hidden state of both RNNs.
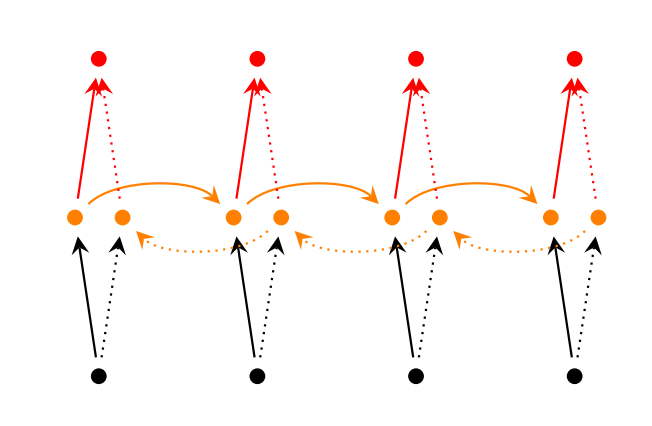
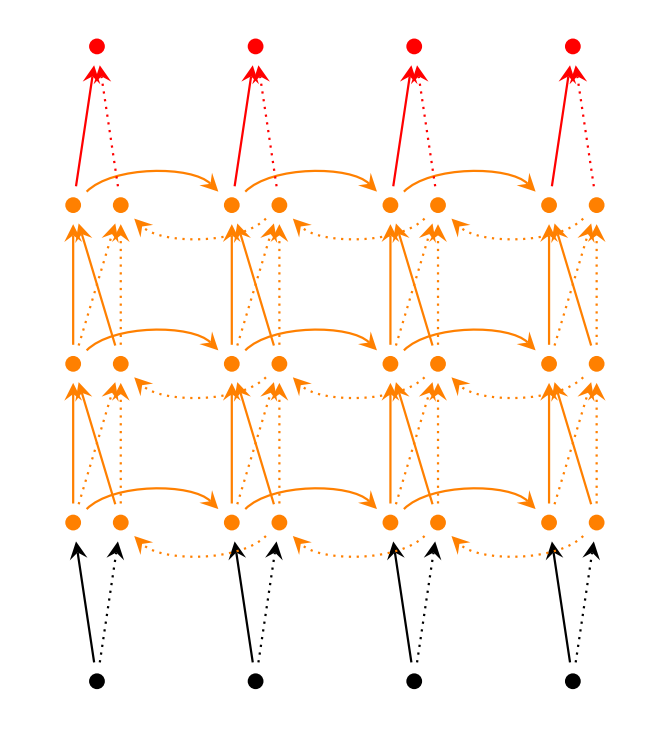
Deep (Bidirectional) RNNs are similar to Bidirectional RNNs, only that we now have multiple layers per time step. In practice this gives us a higher learning capacity (but we also need a lot of training data).
LSTM networks are quite popular these days and we briefly talked about them above. LSTMs don’t have a fundamentally different architecture from RNNs, but they use a different function to compute the hidden state. The memory in LSTMs are called cells and you can think of them as black boxes that take as input the previous state  and current input
and current input  . Internally these cells decide what to keep in (and what to erase from) memory. They then combine the previous state, the current memory, and the input. In turns out that these types of units are very efficient at capturing long-term dependencies. LSTMs can be quite confusing in the beginning but if you’re interested in learning more this post has an excellent explanation.
. Internally these cells decide what to keep in (and what to erase from) memory. They then combine the previous state, the current memory, and the input. In turns out that these types of units are very efficient at capturing long-term dependencies. LSTMs can be quite confusing in the beginning but if you’re interested in learning more this post has an excellent explanation.
Conclusion
So far so good. I hope you’ve gotten a basic understanding of what RNNs are and what they can do. In the next post we’ll implement a first version of our language model RNN using Python and Theano. Please leave questions in the comments!
Related:
- Recycling Deep Learning Models with Transfer Learning
- Deep Learning RNNaissance, an insightful, comprehensive, and entertaining overview
- Top KDnuggets tweets, Jan 14-15: 10 FB likes predicts personality better than a co-worker; A Deep Dive into Recurrent Neural Nets
- Excellent Tutorial on Sequence Learning using Recurrent Neural Networks