Attention and Memory in Deep Learning and NLP
An overview of attention mechanisms and memory in deep neural networks and why they work, including some specific applications in natural language processing and beyond.
The Cost of Attention
If we a bit more look closely at the equation for attention we can see that attention comes at a cost. We need to calculate an attention value for each combination of input and output word. If you have a 50-word input sequence and generate a 50-word output sequence that would be 2500 attention values. That's not too bad, but if you do character-level computations and deal with sequences consisting of hundreds of tokens the above attention mechanisms can become prohibitively expensive.
Actually, that’s quite counterintuitive. Human attention is something that's supposed to save computational resources. By focusing on one thing, we can neglect many other things. But that’s not really what we’re doing in the above model. We’re essentially looking at everything in detail before deciding what to focus on. Intuitively that’s equivalent outputting a translated word, and then going back through all of your internal memory of the text in order to decide what which word to produce next. That seems like a waste, and not at all what humans are doing. In fact, it’s more akin to memory access, not attention, which in my opinion is somewhat of a misnomer (more on that below). Still, that hasn't stopped attention mechanisms from becoming quite popular and performing well on many tasks.
An alternative approach to attention is to use Reinforcement Learning to predict an approximate location to focus to. That sounds a lot more like human attention, and that’s what’s done in Recurrent Models of Visual Attention. However, Reinforcement Learning models cannot be trained end-to-end using backpropagation, so they are not as commonly applied to problems in NLP.
Attention beyond Machine Translation
So far we've looked at attention applied to Machine Translation. But the same attention mechanism from above can be applied to any recurrent model. So let’s look at a few more examples.
In Show, Attend and Tell the authors apply attention mechanisms to the problem of generating image descriptions. They use a Convolutional Neural Network to “encode” the image, and a Recurrent Neural Network with attention mechanisms to generate a description. By visualizing the attention weights (just like in the translation example), we interpret what the model is looking at while generating a word:

In Grammar as a Foreign Language, the authors use a Recurrent Neural Network with attention mechanism to generate sentence parse trees. The visualized attention matrix gives insight into how the network generates those trees:
In Teaching Machines to Read and Comprehend, the authors use a RNN to read a text, read a (synthetically generated) question, and then produce an answer. By visualizing the attention matrix we can see where the networks “looks” while it tries to find the answer to the question:
Attention = (Fuzzy) Memory?
The basic problem that the attention mechanism solves is that it allows the network to refer back to the input sequence, instead of forcing it to encode all information into one fixed-length vector. As I mentioned above, I think that attention is somewhat of a misnomer. Interpreted another way, the attention mechanism is simply giving the network access to its internal memory, which is the hidden state of the encoder. In this interpretation, instead of choosing what to “attend” to, the network chooses what to retrieve from memory. Unlike typical memory, the memory access mechanism here is soft, which means that the network retrieves a weighted combination of all memory locations, not a value from a single discrete location. Making the memory access soft has the benefit that we can easily train the network end-to-end using backpropagation (though there have been non-fuzzy approaches where the gradients are calculated using sampling methods instead of backpropagation).
Memory Mechanisms themselves have a much longer history. The hidden state of a standard Recurrent Neural Network is itself a type of internal memory. RNNs suffer from the vanishing gradient problem that prevents them from learning long-range dependencies. LSTMs improved upon this by using a gating mechanism that allows for explicit memory deletes and updates.
The trend towards more complex memory structures is now continuing. End-to-End Memory Networks allow the network to read same input sequence multiple times before making an output, updating the memory contents at each step. For example, answering a question by making multiple reasoning steps over an input story. However, when the networks parameter weights are tied in a certain way, the memory mechanism in End-to-End Memory Networks identical to the attention mechanism presented here, only that it makes multiple hops over the memory (because it tries to integrate information from multiple sentences).
Neural Turing Machines use a similar form of memory mechanism, but with a more sophisticated type of addressing that using both content-based (like here) and location-based addressing, allowing the network to learn addressing pattern to execute simple computer programs, like sorting algorithms.
It’s likely that in the future we will see a clearer distinction between memory and attention mechanisms, perhaps along the lines of Reinforcement Learning Neural Turing Machines, which try to learn access patterns to deal with external interfaces.
Original. Republished with permission.
Bio: Denny Britz studied Computer Science at Stanford University and UC Berkeley, and started WildML as a way to share his excitement about Machine Learning. He writes posts and tutorials to deepen his own understanding, and is currently excited about Deep Learning, NLP and Reinforcement Learning.
Related:
If we a bit more look closely at the equation for attention we can see that attention comes at a cost. We need to calculate an attention value for each combination of input and output word. If you have a 50-word input sequence and generate a 50-word output sequence that would be 2500 attention values. That's not too bad, but if you do character-level computations and deal with sequences consisting of hundreds of tokens the above attention mechanisms can become prohibitively expensive.
Actually, that’s quite counterintuitive. Human attention is something that's supposed to save computational resources. By focusing on one thing, we can neglect many other things. But that’s not really what we’re doing in the above model. We’re essentially looking at everything in detail before deciding what to focus on. Intuitively that’s equivalent outputting a translated word, and then going back through all of your internal memory of the text in order to decide what which word to produce next. That seems like a waste, and not at all what humans are doing. In fact, it’s more akin to memory access, not attention, which in my opinion is somewhat of a misnomer (more on that below). Still, that hasn't stopped attention mechanisms from becoming quite popular and performing well on many tasks.
An alternative approach to attention is to use Reinforcement Learning to predict an approximate location to focus to. That sounds a lot more like human attention, and that’s what’s done in Recurrent Models of Visual Attention. However, Reinforcement Learning models cannot be trained end-to-end using backpropagation, so they are not as commonly applied to problems in NLP.
Attention beyond Machine Translation
So far we've looked at attention applied to Machine Translation. But the same attention mechanism from above can be applied to any recurrent model. So let’s look at a few more examples.
In Show, Attend and Tell the authors apply attention mechanisms to the problem of generating image descriptions. They use a Convolutional Neural Network to “encode” the image, and a Recurrent Neural Network with attention mechanisms to generate a description. By visualizing the attention weights (just like in the translation example), we interpret what the model is looking at while generating a word:

In Grammar as a Foreign Language, the authors use a Recurrent Neural Network with attention mechanism to generate sentence parse trees. The visualized attention matrix gives insight into how the network generates those trees:
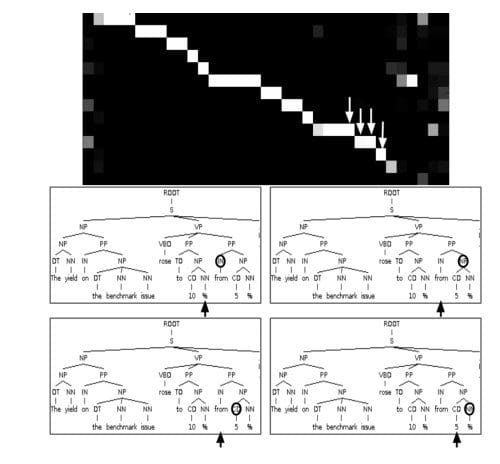
In Teaching Machines to Read and Comprehend, the authors use a RNN to read a text, read a (synthetically generated) question, and then produce an answer. By visualizing the attention matrix we can see where the networks “looks” while it tries to find the answer to the question:

Attention = (Fuzzy) Memory?
The basic problem that the attention mechanism solves is that it allows the network to refer back to the input sequence, instead of forcing it to encode all information into one fixed-length vector. As I mentioned above, I think that attention is somewhat of a misnomer. Interpreted another way, the attention mechanism is simply giving the network access to its internal memory, which is the hidden state of the encoder. In this interpretation, instead of choosing what to “attend” to, the network chooses what to retrieve from memory. Unlike typical memory, the memory access mechanism here is soft, which means that the network retrieves a weighted combination of all memory locations, not a value from a single discrete location. Making the memory access soft has the benefit that we can easily train the network end-to-end using backpropagation (though there have been non-fuzzy approaches where the gradients are calculated using sampling methods instead of backpropagation).
Memory Mechanisms themselves have a much longer history. The hidden state of a standard Recurrent Neural Network is itself a type of internal memory. RNNs suffer from the vanishing gradient problem that prevents them from learning long-range dependencies. LSTMs improved upon this by using a gating mechanism that allows for explicit memory deletes and updates.
The trend towards more complex memory structures is now continuing. End-to-End Memory Networks allow the network to read same input sequence multiple times before making an output, updating the memory contents at each step. For example, answering a question by making multiple reasoning steps over an input story. However, when the networks parameter weights are tied in a certain way, the memory mechanism in End-to-End Memory Networks identical to the attention mechanism presented here, only that it makes multiple hops over the memory (because it tries to integrate information from multiple sentences).
Neural Turing Machines use a similar form of memory mechanism, but with a more sophisticated type of addressing that using both content-based (like here) and location-based addressing, allowing the network to learn addressing pattern to execute simple computer programs, like sorting algorithms.
It’s likely that in the future we will see a clearer distinction between memory and attention mechanisms, perhaps along the lines of Reinforcement Learning Neural Turing Machines, which try to learn access patterns to deal with external interfaces.
Original. Republished with permission.
Bio: Denny Britz studied Computer Science at Stanford University and UC Berkeley, and started WildML as a way to share his excitement about Machine Learning. He writes posts and tutorials to deepen his own understanding, and is currently excited about Deep Learning, NLP and Reinforcement Learning.
Related: