What questions can data science answer?
There are only five questions machine learning can answer: Is this A or B? Is this weird? How much/how many? How is it organized? What should I do next? We examine these questions in detail and what it implies for data science.
How Much / How Many?
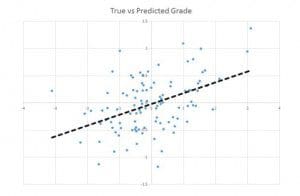 When you are looking for a number instead of a class or category, the algorithm family to use is regression.
When you are looking for a number instead of a class or category, the algorithm family to use is regression.
- What will the temperature be next Tuesday?
- What will my fourth quarter sales in Portugal be?
- How many kilowatts will be demanded from my wind farm 30 minutes from now?
- How many new followers will I get next week?
- Out of a thousand units, how many of this model of bearings will survive 10,000 hours of use?
Usually, regression algorithms give a real-valued answer; the answers can have lots of decimal places or even be negative. For some questions, especially questions beginning “How many…”, negative answers may have to be re-interpreted as zero and fractional values re-interpreted as the nearest whole number.
Multi-Class Classification as Regression
Sometimes questions that look like multi-value classification questions are actually better suited to regression. For instance, “Which news story is the most interesting to this reader?” appears to ask for a category—a single item from the list of news stories. However, you can reformulate it to “How interesting is each story on this list to this reader?” and give each article a numerical score. Then it is a simple thing to identify the highest-scoring article. Questions of this type often occur as rankings or comparisons.
- “Which van in my fleet needs servicing the most?” can be rephrased as “How badly does each van in my fleet need servicing?”
- “Which 5% of my customers will leave my business for a competitor in the next year?” can be rephrased as “How likely is each of my customers to leave my business for a competitor in the next year?”
Two-Class Classification as Regression
It may not come as a surprise that binary classification problems can also be reformulated as regression. (In fact, under the hood some algorithms reformulate every binary classification as regression.) This is especially helpful when an example can belong part A and part B, or have a chance of going either way. When an answer can be partly yes and no, probably on but possibly off, then regression can reflect that. Questions of this type often begin “How likely…” or “What fraction…”
- How likely is this user to click on my ad?
- What fraction of pulls on this slot machine result in payout?
- How likely is this employee to be an insider security threat?
- What fraction of today’s flights will depart on time?
As you may have gathered, the families of two-class classification, multi-class classification, anomaly detection, and regression are all closely related. They all belong to the same extended family, supervised learning. They have a lot in common, and often questions can be modified and posed in more than one of them. What they all share is that they are built using a set labeled examples (a process called training), after which they can assign a value or category to unlabeled examples (a process called scoring).
Entirely different sets of data science questions belong in the extended algorithm families of unsupervised and reinforcement learning.
How is this Data Organized?
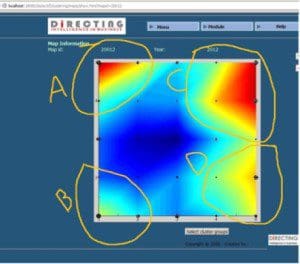 Questions about how data is organized belong to unsupervised learning. There are a wide variety of techniques that try to tease out the structure of data. One family of these perform clustering, a.k.a. chunking, grouping, bunching, or segmentation. They seek to separate out a data set into intuitive chunks. What makes clustering different from supervised learning is that there is no number or name that tells you what group each point belongs to, what the groups represent, or even how many groups there should be. If supervised learning is picking out planets from among the stars in the night sky, then clustering is inventing constellations. Clustering tries to separate out data into natural “clumps,” so that a human analyst can more easily interpret it and explain it to others.
Questions about how data is organized belong to unsupervised learning. There are a wide variety of techniques that try to tease out the structure of data. One family of these perform clustering, a.k.a. chunking, grouping, bunching, or segmentation. They seek to separate out a data set into intuitive chunks. What makes clustering different from supervised learning is that there is no number or name that tells you what group each point belongs to, what the groups represent, or even how many groups there should be. If supervised learning is picking out planets from among the stars in the night sky, then clustering is inventing constellations. Clustering tries to separate out data into natural “clumps,” so that a human analyst can more easily interpret it and explain it to others.
Clustering always relies on a definition of closeness or similarity, called a distance metric. The distance metric can be any measurable quantity, such as difference in IQ, number of shared genetic base pairs, or miles-as-the-crow-flies. Clustering questions all try to break data into more nearly uniform groups.
- Which shoppers have similar tastes in produce?
- Which viewers like the same kind of movies?
- Which printer models fail the same way?
- During which days of the week does this electrical substation have similar electrical power demands?
- What is a natural way to break these documents into five topic groups?
Another family of unsupervised learning algorithms are called dimensionality reduction techniques. Dimensionality reduction is another way to simplify the data, to make it both easier to communicate, faster to compute with, and easier to store.
At its core, dimensionality reduction is all about creating a shorthand for describing data points. A simple example is GPA. A college student’s academic strength is measured in dozens of classes by hundreds of exams and thousands of assignments. Each assignment says something about how well that student understands the course material, but a full listing of them would be way too much for any recruiter to digest. Luckily, you can create a shorthand just by averaging all the scores together. You can get away with this massive simplification because students who do very well on one assignment or in one class typically do well in others. By using GPA rather than the full portfolio, you do lose richness. For instance, you wouldn’t know it if the student is stronger in math than English, or if she scored better on take-home programming assignments than on in-class quizzes. But what you gain is simplicity, which makes it a lot easier to talk about and compare students’ strength.
Dimensionality reduction-related questions are usually about factors that tend to vary together.
- Which groups of sensors in this jet engine tend to vary with (and against) each other?
- What leadership practices do successful CEOs have in common?
- What are the most common patterns in gasoline price changes across the US?
- What groups of words tend to occur together in this set of documents? (What are the topics they cover?)
If your goal is to summarize, simplify, condense, or distill a collection of data, dimensionality reduction and clustering are your tools of choice.
What Should I Do Now?
A third extended family of ML algorithms focuses on taking actions. These are called reinforcement learning(RL) algorithms. They are little different than the supervised and unsupervised learning algorithms. A regression algorithm might predict that the high temperature will be 98 degrees tomorrow, but it doesn’t decide what to do about it. A RL algorithm goes the next step and chooses an action, such as pre-refrigerating the upper floors of the office building while the day is still cool.
RL algorithms were originally inspired by how the brains of rats and humans respond to punishment and rewards. They choose actions, trying very hard to choose the action that will earn the greatest reward. You have to provide them with a set of possible actions, and they need to get feedback after each action on whether it was good, neutral, or a huge mistake.
Typically RL algorithms are a good fit for automated systems that have to make a lot of small decisions without a human’s guidance. Elevators, heating, cooling, and lighting systems are excellent candidates. RL was originally developed to control robots, so anything that moves on its own, from inspection drones to vacuum cleaners, is fair game. Questions that RL answers are always about what action should be taken, although the action is usually taken by machine.
- Where should I place this ad on the webpage so that the viewer is most likely to click it?
- Should I adjust the temperature higher, lower, or leave it where it is?
- Should I vacuum the living room again or stay plugged in to my charging station?
- How many shares of this stock should I buy right now?
- Should I continue driving at the same speed, brake, or accelerate in response to that yellow light?
RL usually requires more effort to get working than other algorithm types because it’s so tightly integrated with the rest of the system. The upside is that most RL algorithms can start working without any data. They gather data as they go, learning from trial and error.
The first post in this series covered the basic ingredients for doing good data science. The next and final post will give lots of specific examples of sharp data science questions and the algorithm family best suited to each. Stay tuned.
Bio: Brandon Rohrer is a Senior Data Scientist at Microsoft.
This post was originally published on Microsoft's TechNet Machine Learning Blog.