10 Data Acquisition Strategies for Startups
An interesting discussion of the myriad methods in which startups may choose to acquire data, often the most overlooked and important aspect of a startup's success (or failure).
Strategy #6: Data trap
Another approach to gather useful data exhaust is to build what Matt Turck has called a “data trap” (Leo Polovets has given this strategy the rather uncharming title “Trojan Horse to collect data”). The goal is to create something that is valuable even without machine learning, and then sell it at a cost to gather data (even if the margin is tiny). In contrast to the previous strategy, building a data trap is a core part of a startup’s business model (not merely a side business).

A case in point is Recombine, a clinical genetic testing company that sells fertility tests to gather DNA data that can then be analyzed with machine learning. Another example is BillGuard (acquired by Prosper in 2015), a startup that offers a mobile app to help credit card users catch and dispute “grey charges.” The app helped BillGuard crowdsource a large amount of fraud data that could then be used for other purposes. One could even argue that Tesla is pursuing this strategy. With over 100,000 (sensor-equipped) vehicles on the road, Tesla is currently building the largest training datasets for self-driving cars (gathering more autopilot miles every day than Google).
Interesting for: Vertically integrated businesses
Examples:
Strategy #7: Publicly available datasets
A strategy that many startups have tried — with varying degrees of success — is mining data from publicly available sources. Web archives like The Common Crawl contain petabytes of free raw data collected over years of web crawling. In addition, companies like Yahoo or Criteo have released huge datasets to the research community (Yahoo released a whopping 13.5 TB of uncompressed data!). And with the recent proliferation of publicly available government datasets (spearheaded by the Obama administration), more and more data sources are becoming freely available.

Several machine learning startups have taken advantage of public data. When Oren Etzioni started Farecast (acquired by Microsoft in 2008), he used a sample of 12,000 price observations that he obtained by scraping information from a travel website. Similarly, SwiftKey (acquired by Microsoft in 2016) collected and analyzed terabytes of web-crawled data in the early days to create its language models.
Interesting for: Startups that can identify a relevant public dataset
Examples:
- Farecast (first version scraped information from a travel website)
- SwiftKey (crawled web text to create language models)
- The Echo Nest (crawled millions of music-related websites every day)
- Jetpac (used public Instagram data for its mobile application)
Strategy #8: License third-party data
Another way to access third-party data is to license it, either through an API that is provided by an external data provider, or by implementing SDKs in third-party mobile apps to capture data (ideally with end user consent). In both cases, startups pay an external party for access to data that was generated for one purpose, and then apply machine learning to extract new value from that data.
Farecast and Decide.com (both founded by Oren Etzioni) have successfully pursued this strategy. Open data platforms like Clearbit or Factual are examples of external data providers. Among the companies that use third-party data to mine predictive insights are also several hedge funds and algo-trading firms (which are using non-traditional datasets like satellite data from startups like Orbital Insight or Rezatec).
Interesting for: Startups that rely on third-party data (e.g. industry data)
Examples:
- Farecast (licensed airline data to generate airfare predictions)
- Decide.com (licensed e-commerce data to generate price predictions)
- Building Radar (uses ESA satellite images to monitor construction projects)
Strategy #9: Collaboration with large corporation
For enterprise startups, the data provider can be a large customer that provides access to relevant data. In this setup, the startup sells the customer a solution to a problem (such as reducing fraud) and trains its learning algorithms using the customer’s data. Ideally, the data learnings from one customer or instance can then be transferred to all other customers. Examples in the field of fraud detection are Sift Science and SentinelOne.
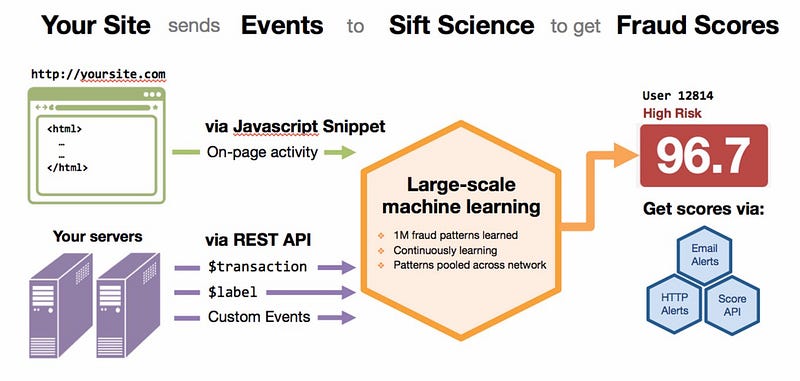
The challenge with this approach is to negotiate upfront that the data learnings will be owned by the startup while the data itself remains property of the customer. This can be problematic given that large corporations often have stringent compliance rules and are very sensitive of sharing proprietary data.
Interesting for: Enterprise startups
Examples:
- Sift Science (uses company-specific data to find unique fraud signals)
- SentinelOne (cybersecurity startup that sells endpoint protection software)
- Skytree (develops machine learning software for enterprise use)
Strategy #10: Small acquisitions
Matt Turck lists small acquisitions of companies as a way to get access to particularly relevant datasets (akin to acquisitions of valuable patent portfolios). IBM Watson, for example, has made four data-related acquisitions in 2015, transforming its health unit into one of the world’s largest and most diverse repositories of health-related data.

Since this approach requires the means to fund the acquisition, it might only be viable for startups with substantial funding.
Interesting for: (Later-stage) startups with enough funding
Examples: Hard to pinpoint (data is rarely the only reason for acquisitions)
There are quite possibly other data acquisition strategies which are not mentioned here (if so, please drop me a line). There are also several algorithmic tricks that startups can employ to work around the data problem (such as transfer learning, a technique used by MetaMind for instance).
Whatever strategy you pursue, the key message is: Accessing and owning a large, domain-specific dataset to build high accuracy models can be the single hardest problem that founders need to solve in the beginning. In some cases, it involves finding a quick-fix solution that does not scale, like employing humans pretending to be machines pretending to be humans (as done by many chatbot startups). In other cases, it requires to significantly delay the move from free, limited beta to public release until the benefits of machine learning kick in and customers are willing to pay for the product.
The strategies and examples were drawn from conversations with entrepreneurs as well as several blog posts, including from Nathan Benaich (here), Chris Dixon (here), Florian Douetteau (here), Leo Polovets (here), Matt Turck (here) and Boris Wertz (here).
Bio: Moritz Mueller-Freitag graduated from HEC Paris and the University of Munich. Currently he is a Data Scientist at Eleven Strategy in Paris.
Original. Reposted with permission.
Related:
- Where are the Opportunities for Machine Learning Startups?
- Intel’s Investments in Cognitive Tech: Impact and New Opportunities
- Microsoft is Becoming M(ai)crosoft