Database Key Terms, Explained
Interested in a survey of important database concepts and terminology? This post concisely defines 16 essential database key terms.
Data has value. Actually, data is value. Data has proven to be the most important commodity in the digital economy. Data's actual value continues to grow, and the limits of its prospective value are pushed every day. Data is the new everything.
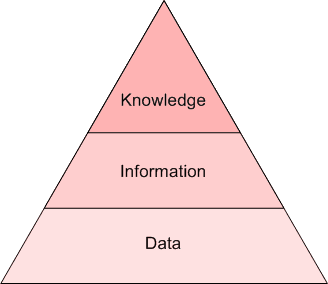
Data needs to be curated, coddled, and cared for. It needs to be stored and processed, so that it may be transformed into information, and further refined into knowledge. The mechanism for storing data, subsequently facilitating these transformations, is, clearly, the database.
This post presents 16 key database concepts and their corresponding concise, straightforward definitions.
The selection of terms for this topic is especially difficult, so a whole host of reasons. Suffice it to say that these 16 concepts do not adequately represent all important terminology related to databases. I hope that they do, however, provide a jumping off point for those interested in learning more about databases, and their design and management.
1. Relational Database
A relational database is one which employs the relational model, in which the raw data is organized into sets of tuples, and the tuples organized into relations. This relational model imposes structure on its contents, in contrast to unstructured or semi-structured data of the various NoSQL architectures.
2. Database Management System (DBMS)
A database management system is a software system which facilitates the organization of housed data into a particular database architecture, be it relational (Relational Database Management System, or RDBMS), document store, key-value store, column-oriented, graph, or other. Popular DBMSs include MongoDB, Cassandra, Redis, MySQL, Microsoft SQL Server, SQLite, and Oracle, among many, many, many others.
3. Primary Key
In the relational model, a primary key is a single attribute, or combination of attributes, which can be used to uniquely identify a row of data in a givn table. Common primary keys include vendor ID, user ID, email address, or combination of attributes considered together such as first name, last name, and city of residence, all considered together as a single entity. It should be noted that what is an acceptable primary key in one situation may not uniquely identify data instances in another.
4. Foreign Key
Again in the relational model, a foreign key is an attribute or collection of attributes from one relational table whose values must match another relational table's primary key. A common use for such an organizational scheme would be to link a street address in one table to a city in another, and perhaps to a country in a third. This eliminates repetitive data input, and reduces the possibility of error, increasing data accuracy.
5. Structured Query Language (SQL)
SQL is a relational database query and manipulation language. Its power and flexibility allows for the creation of databases and tables, and the manipulation and query of data. More recently, the term has become conflated with relational databases, relational database management systems, and the relational model, at least as a term used in contrast to the term "NoSQL."
6. NoSQL
NoSQL is an umbrella term, one which encompasses a number of different technologies. These different technologies aren't even necessarily related in any way beyond the single defining characteristic of NoSQL: they are not relational in nature. This lack of relational structure results in unstructured or semi-structured data in storage; there may be structure, but it is loose in nature, lax in enforcement.
Often, NoSQL is used to mean "not only SQL," meaning that these solutions are more flexible and less rigid in nature. I'm sure there are die-hards in this argument of terminology ownership, but just be aware of the potential difference in definition.
7. Metadata
This is the data about the data. Metadata describes data relationships and characteristics, and is often referred to as a data dictionary, though that seems to be a term more prevalent in the relational world (though not exclusive to it by any means).
8. Consistency
A database is consistent when all of its imposed integrity constraints have been satisfied. Consistency can only be ensured if each database transaction, or data access request, begins in a known consistent state; otherwise, guarantees of consistency cannot be made. A database containing data that cannot be verified as consistent is problematic, especially to the extent to which its inconsistency is not known.
9. Data Redundancy
Data redundancy is a situation in a database in which copies of a given piece of data are housed in 2 different places. This redundancy can be achieved if data is held in multiple places in the same database, in multiple databases on the same computer, or in multiple databases across multiple computers, perhaps even using different database management server software. This redundancy can be leveraged for both data access and permanence.
10. ACID
ACID is an acronym referring to a set of database transaction properties, namely Atomicity, Consistency, Isolation, and Durability. A single database operation, or transaction, must be atomic, consistent, isolated, and durable in order to be valid. In other words, the set of steps which make up a transaction must either be completed in full or rolled back (atomic), consistent (see above definition), must be isolated from other potential transactions, and must be permanent (durable).
11. CAP Theorem
The CAP Theorem concludes that it is not possible for a distributed computer system (including distributed database management software and their housed data) to provide all of the following guarantees at the same time: Consistency, which states that each computer node contain all of the same data at the same time; availability, which states that each database request is responded to as either successful or failure; and partition tolerance, which states that the database system continues operating even when not all nodes are connected to one another and suffer communication issues. At best, only 2 of these guarantees can be made concurrently.
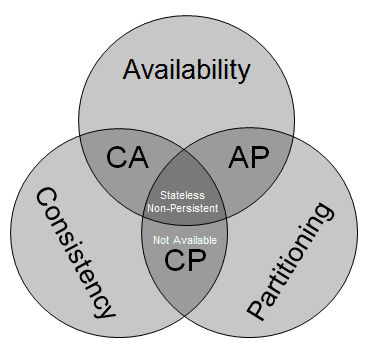
12. Sharding
Sharding is a technique for partitioning data. A database shard is a horizontal (think rows, not columns) partition of data within a database, with each partition being referred to as a shard. These shards are then spread across computer nodes, in order to balance the load. Data may then be included in one or more of these shards.
13. Key-value Store
Key-value stores are one of the predominant NoSQL architectures. Key-value stores are simple paradigms at a high-level: assign values to keys to facilitate the access and storage of these values, which are always found via their keys. Data values are added to the database with a identifying keys; the same data values are later accessed with the same key. If you have an understanding of hash maps then you are a step ahead (dictionaries in Python). Redis is an example of a key-value store.
14. Document Store
A document store is another NoSQL database architecture. As is the requirement for NoSQL engines, MongoDB does not use a relational schema; instead, document stores use JSON-like "documents" to store data. The document is akin to a record, housing fields and values. MongoDB is a free and open source exemplar.

15. Column-oriented Database
Another NoSQL architecture, column-oriented databases' rows actually contain what we most usually think of as vertical data, or what is traditionally held in relational columns (Rows contains columns? Huh?). The advantage of column-oriented database design is that some types of data lookups can become very fast, given that the desired data could be stored consecutively in a single row (compare this with having to search and read from multiple, nonconsecutive rows to attain the same field value in row-oriented database). Cassandra is a popular example of a column-oriented database.
16. Graph Database
The graph database is premised on edges acting as relationships, directly relating data instances to one another. Graph databases have advantages in some use cases, including potentially in certain data mining and pattern recognition scenarios, given that associations between data instances are explicitly stated. Neo4j is the most widely-used graph database available.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.