An Intuitive Guide to Deep Network Architectures
How and why do different Deep Learning models work? We provide an intuitive explanation for 3 very popular DL models: Resnet, Inception, and Xception.
Let’s say there are M input maps. One additional filter means convolving over M more maps; N additional filters means convolving over N*M more maps. In other words, as the authors note, “any uniform increase in the number of [filters] results in a quadratic increase of computation.” Our naive Inception module just tripled or quadrupled the number of filters. Computationally speaking, this is a Big Bad Thing.
This leads to insight #2: using 1×1 convolutions to perform dimensionality reduction. In order to solve the computational bottleneck, the authors of Inception used 1×1 convolutions to “filter” the depth of the outputs. A 1×1 convolution only looks at one value at a time, but across multiple channels, it can extract spatial information and compress it down to a lower dimension. For example, using 20 1×1 filters, an input of size 64x64x100 (with 100 feature maps) can be compressed down to 64x64x20. By reducing the number of input maps, the authors of Inception were able to stack different layer transformations in parallel, resulting in nets that were simultaneously deep (many layers) and “wide” (many parallel operations).

How well did this work? The first version of Inception, dubbed “GoogLeNet,” was the 22-layer winner of the ILSVRC 2014 competition I mentioned earlier. Inception v2 and v3 were developed in a second paper a year later, and improved on the original in several ways — most notably by refactoring larger convolutions into consecutive smaller ones that were easier to learn. In v3, for example, the 5×5 convolution was replaced with 2 consecutive 3×3 convolutions.
Inception rapidly became a defining model architecture. The latest version of Inception, v4, even threw in residual connections within each module, creating an Inception-ResNet hybrid. Most importantly, however, Inception demonstrated the power of well-designed “network-in-network” architectures, adding yet another step to the representational power of neural networks.
Fun facts:
- The original Inception paper literally cites the “we need to go deeper” internet meme as an inspiration for its name. This must be the first time knowyourmeme.com got listed as the first reference of a Google paper.
- The second Inception paper (with v2 and v3) was released just one day after the original ResNet paper. December 2015 was a good time for deep learning.
Xception
Xception stands for “extreme inception.” Rather like our previous two architectures, it reframes the way we look at neural nets — conv nets in particular. And, as the name suggests, it takes the principles of Inception to an extreme.
Here’s the hypothesis: “cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly.”
What does this mean? Well, in a traditional conv net, convolutional layers seek out correlations across both space and depth. Let’s take another look at our standard convolutional layer:
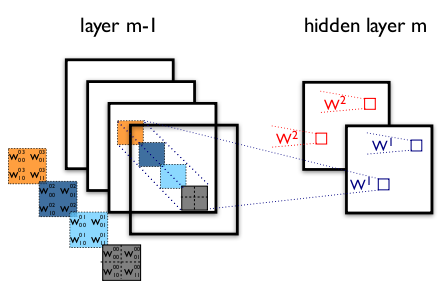
In the image above, the filter simultaneously considers a spatial dimension (each 2×2 colored square) and a cross-channel or “depth” dimension (the stack of four squares). At the input layer of an image, this is equivalent to a convolutional filter looking at a 2×2 patch of pixels across all three RGB channels. Here’s the question: is there any reason we need to consider both the image region and the channels at the same time?
In Inception, we began separating the two slightly. We used 1×1 convolutions to project the original input into several separate, smaller input spaces, and from each of those input spaces we used a different type of filter to transform those smaller 3D blocks of data. Xception takes this one step further. Instead of partitioning input data into several compressed chunks, it maps the spatial correlations for each output channel separately, and then performs a 1×1 depthwise convolution to capture cross-channel correlation.
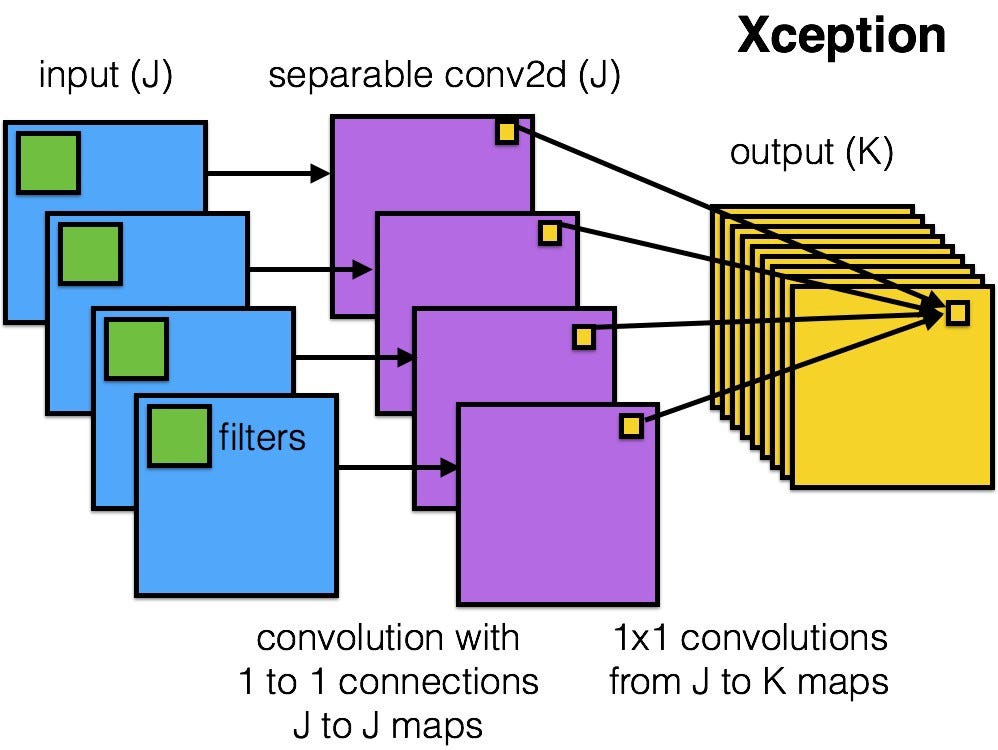
The author notes that this is essentially equivalent to an existing operation known as a “depthwise separable convolution,” which consists of a depthwise convolution (a spatial convolution performed independently for each channel) followed by a pointwise convolution (a 1×1 convolution across channels). We can think of this as looking for correlations across a 2D space first, followed by looking for correlations across a 1D space. Intuitively, this 2D + 1D mapping is easier to learn than a full 3D mapping.
And it works! Xception slightly outperforms Inception v3 on the ImageNet dataset, and vastly outperforms it on a larger image classification dataset with 17,000 classes. Most importantly, it has the same number of model parameters as Inception, implying a greater computational efficiency. Xception is much newer (it came out in April 2017), but as mentioned above, its architecture is already powering Google’s mobile vision applications through MobileNet.
Fun facts:
- The author of Xception is also the author of Keras. Francois Chollet is a living god.
Moving forward
That’s it for ResNet, Inception, and Xception! I firmly believe in having a strong intuitive understanding of these networks, because they are becoming ubiquitous in research and industry alike. We can even use them in our own applications with something called transfer learning.
Transfer learning is a technique in machine learning in which we apply knowledge from a source domain (e.g. ImageNet) to a target domain that may have significantly fewer data points. In practice, this generally involves initializing a model with pre-trained weights from ResNet, Inception, etc. and either using it as a feature extractor, or fine-tuning the last few layers on a new dataset. With transfer learning, these models can be re-purposed for any related task we want, from object detection for self-driving vehicles to generating captions for video clips.
To get started with transfer learning, Keras has a wonderful guide to fine-tuning models here. If it sounds interesting to you, check it out — and happy hacking!
Original. Reposted with permission.
Bio: Joyce Xu is a student at Stanford. She worked on natural language processing, computer vision, and Deep learning at @ThinkTopic, and @joinvolley.
Related: