The 10 Deep Learning Methods AI Practitioners Need to Apply
Deep learning emerged from that decade’s explosive computational growth as a serious contender in the field, winning many important machine learning competitions. The interest has not cooled as of 2017; today, we see deep learning mentioned in every corner of machine learning.
4 — Dropout
Deep neural nets with a large number of parameters are very powerful machine learning systems. However, overfitting is a serious problem in such networks. Large networks are also slow to use, making it difficult to deal with overfitting by combining the predictions of many different large neural nets at test time. Dropout is a technique for addressing this problem.
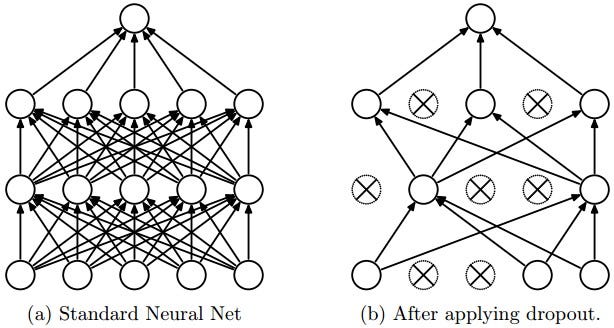
The key idea is to randomly drop units (along with their connections) from the neural network during training. This prevents units from co-adapting too much. During training, dropout samples from an exponential number of different “thinned” networks. At test time, it is easy to approximate the effect of averaging the predictions of all these thinned networks by simply using a single untwined network that has smaller weights. This significantly reduces overfitting and gives major improvements over other regularization methods. Dropout has been shown to improve the performance of neural networks on supervised learning tasks in vision, speech recognition, document classification and computational biology, obtaining state-of-the-art results on many benchmark datasets.
5 — Max Pooling
Max pooling is a sample-based discretization process. The object is to down-sample an input representation (image, hidden-layer output matrix, etc.), reducing its dimensionality and allowing for assumptions to be made about features contained in the sub-regions binned.
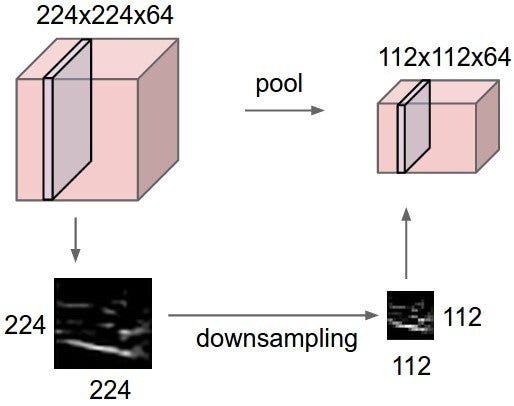
This is done in part to help over-fitting by providing an abstract form of the representation. As well, it reduces the computational cost by reducing the number of parameters to learn and provides basic translation invariance to the internal representation. Max pooling is done by applying a max filter to usually non-overlapping subregions of the initial representation.
6 — Batch Normalization
Naturally, neural networks including deep networks require careful tuning of weight initialization and learning parameters. Batch normalization helps relaxing them a little.
Weights problem:
- Whatever the initialization of weights, be it random or empirically chosen, they are far away from the learned weights. Consider a mini batch, during initial epochs, there will be many outliers in terms of required feature activations.
- The deep neural network by itself is ill-posed, i.e. a small perturbation in the initial layers, leads to a large change in the later layers.
During back-propagation, these phenomena causes distraction to gradients, meaning the gradients have to compensate the outliers, before learning the weights to produce required outputs. This leads to the requirement of extra epochs to converge.

Batch normalization regularizes these gradient from distraction to outliers and flow towards the common goal (by normalizing them) within a range of the mini batch.
Learning rate problem: Generally, learning rates are kept small, such that only a small portion of gradients corrects the weights, the reason is that the gradients for outlier activations should not affect learned activations. By batch normalization, these outlier activations are reduced and hence higher learning rates can be used to accelerate the learning process.
7 — Long Short-Term Memory:
A LSTM network has the following three aspects that differentiate it from an usual neuron in a recurrent neural network:
- It has control on deciding when to let the input enter the neuron.
- It has control on deciding when to remember what was computed in the previous time step.
- It has control on deciding when to let the output pass on to the next time stamp.
The beauty of the LSTM is that it decides all this based on the current input itself. So if you take a look at the following diagram:
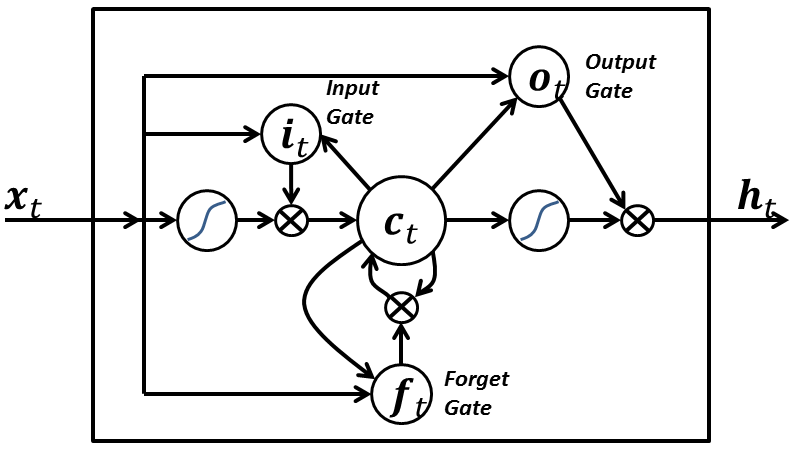
The input signal x(t) at the current time stamp decides all the above 3 points. The input gate takes a decision for point 1. The forget gate takes a decision on point 2 and the output gate takes a decision on point 3. The input alone is capable of taking all these three decisions. This is inspired by how our brains work and can handle sudden context switches based on the input.
8 — Skip-gram:
The goal of word embedding models is to learn a high-dimensional dense representation for each vocabulary term in which the similarity between embedding vectors shows the semantic or syntactic similarity between the corresponding words. Skip-gram is a model for learning word embedding algorithms.
The main idea behind the skip-gram model (and many other word embedding models) is as follows: Two vocabulary terms are similar, if they share similar context.
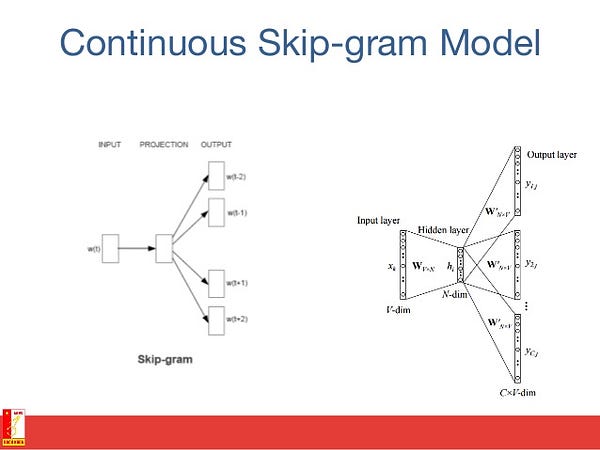
In other words, assume that you have a sentence, like “cats are mammals”. If you use the term “dogs” instead of “cats”, the sentence is still a meaningful sentence. So in this example, “dogs” and “cats” can share the same context (i.e., “are mammals”).
Based on the above hypothesis, you can consider a context window (a window containing k consecutive terms. Then you should skip one of these words and try to learn a neural network that gets all terms except the one skipped and predicts the skipped term. Therefore, if two words repeatedly share similar contexts in a large corpus, the embedding vectors of those terms will have close vectors.
9 — Continuous Bag Of Words:
In natural language processing problems, we want to learn to represent each word in a document as a vector of numbers such that words that appear in similar context have vectors that are close to each other. In continuous bag of words model, the goal is to be able to use the context surrounding a particular word and predict the particular word.

We do this by taking lots and lots of sentences in a large corpus and every time we see a word, we take the surrounding word. Then we input the context words to a neural network and predict the word in the center of this context.
When we have thousands of such context words and the center word, we have one instance of a dataset for the neural network. We train the neural network and finally the encoded hidden layer output represents the embedding for a particular word. It so happens that when we train this over a large number of sentences, words in similar context get similar vectors.
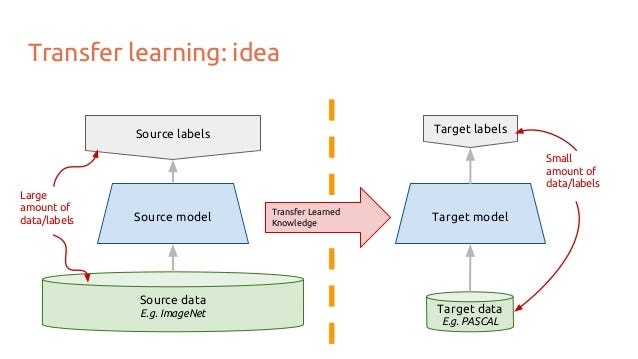
10 — Transfer Learning:
Let’s think about how an image would run through a Convolutional Neural Networks. Say you have an image, you apply convolution to it, and you get combinations of pixels as outputs. Let’s say they’re edges. Now apply convolution again, so now your output is combinations of edges… or lines. Now apply convolution again, so your output is combinations of lines and so on. You can think of it as each layer looking for a specific pattern. The last layer of your neural network tends to get very specialized. Perhaps if you were working on ImageNet, your networks last layer would be looking for children or dogs or airplanes or whatever. A couple layers back you might see the network looking for eyes or ears or mouth or wheels.
Each layer in a deep CNN progressively builds up higher and higher level representations of features. The last couple layers tend to be specialized on whatever data you fed into the model. On the other hand, the early layers are much more generic, there are many simple patterns common among a much larger class of pictures.
Transfer learning is when you take a CNN trained on one dataset, chop off the last layer(s), retrain the models last layer(s) on a different dataset. Intuitively, you’re retraining the model to recognized different higher level features. As a result, training time gets cut down a lot so transfer learning is a helpful tool when you don’t have enough data or if training takes too much resources.
This article only shows the general overview of these methods. I suggest reading the articles below for more detailed explanations:
- Andrew Beam’s “Deep Learning 101”
- Andrey Kurenkov’s “A Brief History of Neural Nets and Deep Learning”
- Adit Deshpande’s “A Beginner’s Guide to Understanding Convolutional Neural Networks”
- Chris Olah’s “Understanding LSTM Networks”
- Algobean’s “Artificial Neural Networks”
- Andrej Karpathy’s “The Unreasonable Effectiveness of Recurrent Neural Networks”
Deep Learning is strongly technique-focused. There are not much concrete explanations for each of the new ideas. Most new ideas came out with experimental results attached to prove that they work. Deep Learning is like playing LEGO. Mastering LEGO is as challenging as any other arts, but getting into it is easier.
Bio: James Le is currently applying for Master of Science Computer Science programs in the US for the Fall 2018 admission. His intended research will focus on Machine Learning and Data Mining. In the mean time, he is working as a freelance full-stack web developer.
Original. Reposted with permission.
Related:
- The 10 Statistical Techniques Data Scientists Need to Master
- The 10 Algorithms Machine Learning Engineers Need to Know
- Top 10 Machine Learning Algorithms for Beginners