A Guide to Hiring Data Scientists
This article provides a short overview of emerging data scientist types and their unique skillsets, as well as a guide for HR professionals and analytics managers who are looking to hire their first data scientists or build a data science team. Included are an overview of skills for each type and specific questions that can be asked to assess candidates.
Data science is an emerging field, and roles, as well as qualifications, aren’t clear-cut at the moment. Given the murkiness surrounding the field and the potential lack of analytics expertise at companies seeking to hire a data scientist or team of data scientists, the task of building an analytics team or hiring a company’s first data scientist can be daunting. However, with a brief overview of data scientist types and example questions to assess each type, hiring managers can provide recruiters with a more tailored profile and better assess candidates on skills likely needed to fill the role.
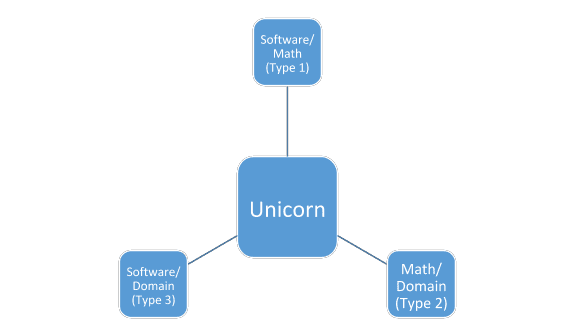
Data scientists typically have skills in 3 main areas: mathematics/statistics/machine learning, coding/software engineering, and expertise in the industry in which they seek employment (see chart below). Most mature data scientists have a strong skills in 2 of these 3 areas, yielding software/math folks (who are typically found in tech companies or production roles), math/domain folks (more of a traditional statistician or scientific researcher), or software/domain (less common but often involved in data pipelines and business intelligence roles). Someone with strong skills in all 3 areas are the so-called “unicorns,” and they are typically late career folks or consultants by the time they develop expertise in all 3 areas. In addition to these skills, a solid data science candidate should have knowledge of scientific research processes and solid communication skills to turn results into possible business solutions.
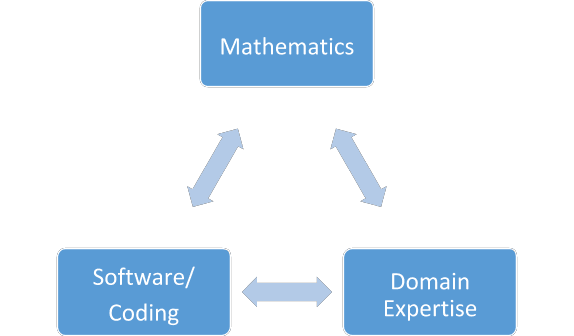
Hiring the right candidate for the role he/she will play within the company can be simplified by pigeonholing the role as 1 of the 3 mature data scientist types, and subsequent job descriptions/interview questions can be tailored to that type of role. By pairing 2 or 3 data scientists with complimentary skills, one can build an effective data science team without needing a large budget.
Math/software strengths (Type 1) are common in tech companies or positions in which new algorithms or data frameworks can be productionalized without respect to nuances of the industry, data types, or regulations of the industry (such as those in education, healthcare, finance, and biotech/pharma). These folks might create a new version of PageRank, develop a new app for the company, or productionalize new algorithms and BI findings. Skills include a mix of several programming languages (Python, R, maybe even C++ or Java), big data frameworks (Hadoop, Spark, NoSQL…), algorithm design and software development (computer science coursework or degree, agile/waterfall software lifecycles), and some advanced training in mathematics or machine learning (possibly a degree in this field). Education-wise, Type 1 data scientists most likely to enter data science with a Bachelor’s or Master’s degree, likely focused on computer science or software engineering.
Questions to assess a Type 1 candidate might touch upon distributed computing frameworks (steps of MapReduce for algorithm design, knowing which algorithms work well in distributed computing), database design (relational vs. non-relational vs. Neo4j, real-time capture and deployment of models, automated table updates), creation of analytics pipelines (particularly in Python these days), and depth of machine learning knowledge (mathematical concepts used to create a random forest model, mathematical differences and implementation considerations of random forest vs. boosted regression, knowledge of differences between deep learning frameworks…).
Math/domain data scientists (Type 2) typically work within a specialized industry like education, biotechnology/genomics, healthcare, insurance… where industries are regulated and knowledge of biology, psychology, actuarial science, and others can help frame relevant questions and inform analytics practices within the company, particularly with respect to federal guidelines and best research practices. Type 2 data scientists are also found in large companies to assist in marketing, sales, finance, and other business-related problems. Skills include deep mathematical and machine learning expertise (typically graduate-level knowledge/education), study design/research practices (sampling practices, power analysis, dependent variable types, scientific publications…), domain expertise (either a degree in that field or industry experience), and substantial knowledge of the software utilized by that industry (SAS, R, Python, Matlab…). These folks are most likely to have a PhD (and may be a career switcher from academia) or hold a Master’s degree in math/statistics with substantial published research.
Some of the questions to assess Type 2 candidates will be field-specific (genomics questions/PLINK coding exercise for a genomics company, for instance), and others will focus on research design (bias, A/B testing or control/experiment design, power analysis and consequences of overpowered samples…), statistical analysis (Bayesian probability, generalized linear modeling and dependent variables, time-series forecasting), and machine learning (explain the mathematics of different ensemble techniques the way you would to a grade-schooler, explain penalized regression models and when they are useful, explain how sample size influences algorithm choice and performance…).
Software/domain folks (Type 3) are useful in positions where the data scientist is driving data collection, data management, and app development within a specialized field. They typically have experience within their industry and may or may not have a degree related to that industry with substantial coding expertise. In the business world, Type 3 folks tend to have a technical background combined with an MBA and often end up leading a tech team or managing an analytics department. Skills include database design/data capture (SQL, Hadoop, design principles), software development (scrum, agile/waterfall lifecycles), programming (SAS, Python, Java, C++ common), and domain knowledge (regulations for biotech, development/documentation requirements for industry).
Questions to assess Type 3 candidates might range from principles of database design (foreign keys, executables...), industry-specific questions (integrating PLINK with the rest of a pipeline in genomics or working with an ontology structure, for instance), and MapReduce/distributed computing systems (relevance to app design or pipeline bottlenecks…).
All candidates should show a competence and comfort with analyzing data and presenting results to other analytics folks or leadership without an analytics background, as this is an essential function of data scientists, and data science candidates should be knowledgeable enough in software or mathematics to collaborate with those who compliment their particular skillset, as most companies these days assemble a small analytics team with varied expertise to cover the full range of data science.
As a final thought and resource guide, I’m providing a question bank including a few of my favorites for assessing potential data scientists (which cover a variety of data scientist types):
- Explain the mathematical foundations of random forest and boosted regression, comparing and contrasting their formulation as well as computational implementation concerns.
- Ask something related to conditional probability and Bayes' theorem.
- Discuss the last machine learning/computer science paper you read and how you would explain it to your five-year-old niece.
- Give a hypothetical dataset (related to a previous project at your own company) and ask for potential ways to analyze it (or give them the data and a few days to analyze).
- Ask about MapReduce or relevant computing frameworks (R, Python, Hadoop...) they will likely use in the position.
- Explain a p-value.
- Explain how diversity reduces error and bias in ensemble methods.
- Name and explain 3 different dimensionality reduction strategies.
- If network analysis will be used in the position: explain the math behind PageRank and how linear algebra in general can be used on graph/network problems.
- How would you explain (machine learning algorithm or software design) to a kindergartener using the objects in this room?
- Explain one contribution of topology/geometry to the field of statistics and machine learning in detail.
- Include a critical thinking/IQ-related item or two (particularly from this question bank: http://www.iflscience.com/brain/prove-your-smarts-with-the-worlds-shortest-iq-test).
- Explain your preference for software development lifecycles and give an example of best practices you have learned from previous positions.
- How would you go about setting up an A/B test? How would you control for bias? Why is a control group necessary for testing?
- Ask something industry-specific (regulations, data types, domain knowledge).
Bio: Colleen M. Farrelly is an R&D data scientist whose areas of expertise includes topology/topological data analysis, ensemble learning, nonparametric statistics, manifold learning, and explaining mathematics to lay audiences (www.quora.com/profile/Colleen-Farrelly-1). She has been through the interview process several times and has written several posts and articles about hiring practices in data science (mostly on Quora and LinkedIn). When she isn’t doing data science, she is a poet and author (www.amazon.com/Colleen-Farrelly/e/B07832WQG7).
Related: