 Top 20 Python Libraries for Data Science in 2018
Top 20 Python Libraries for Data Science in 2018
 Top 20 Python Libraries for Data Science in 2018
Top 20 Python Libraries for Data Science in 2018Our selection actually contains more than 20 libraries, as some of them are alternatives to each other and solve the same problem. Therefore we have grouped them as it's difficult to distinguish one particular leader at the moment.
Machine Learning
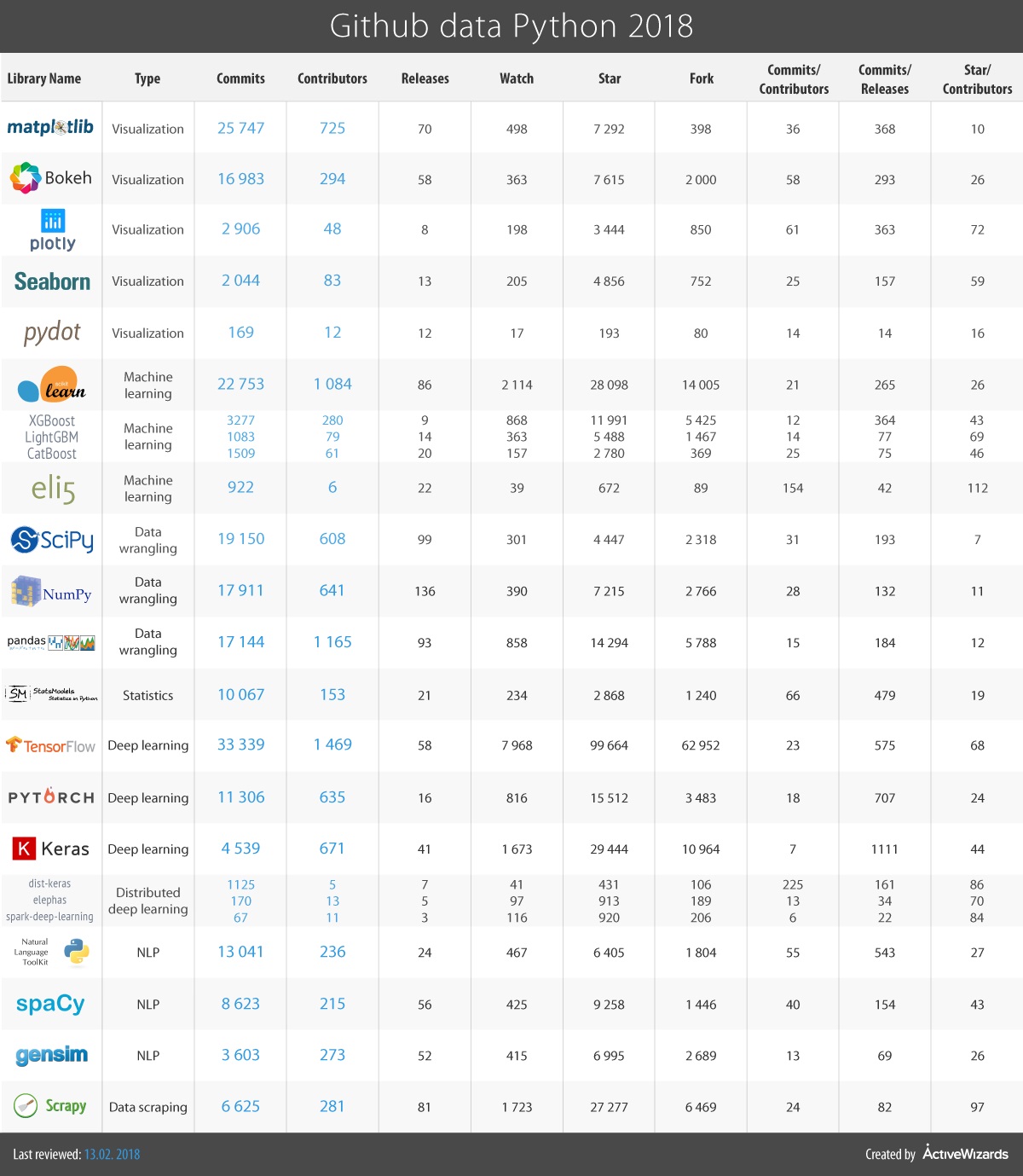
10. Scikit-learn (Commits: 22753, Contributors: 1084)
This Python module based on NumPy and SciPy is one of the best libraries for working with data. It provides algorithms for many standard machine learning and data mining tasks such as clustering, regression, classification, dimensionality reduction, and model selection.
There is a number of enhancements made to the library. The cross validation has been modified, providing an ability to use more than one metric. Several training methods like nearest neighbors and logistic regressions faced some minor improvements. Finally, one of the major updates is the accomplishment of the Glossary of Common Terms and API Elements which acquaints with the terminology and conventions used in Scikit-learn.
11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
Gradient boosting is one of the most popular machine learning algorithms, which lies in building an ensemble of successively refined elementary models, namely decision trees. Therefore, there are special libraries designed for fast and convenient implementation of this method. Namely, we think that XGBoost, LightGBM, and CatBoost deserve special attention. They are all competitors that solve a common problem and are used in almost the same way. These libraries provide highly optimized, scalable and fast implementations of gradient boosting, which makes them extremely popular among data scientists and Kaggle competitors, as many contests were won with the help of these algorithms.
12. Eli5 (Commits: 922, Contributors: 6)
Often the results of machine learning models predictions are not entirely clear, and this is the challenge that eli5 library helps to deal with. It is a package for visualization and debugging machine learning models and tracking the work of an algorithm step by step. It provides support for scikit-learn, XGBoost, LightGBM, lightning, and sklearn-crfsuite libraries and performs the different tasks for each of them.
Deep Learning
13. TensorFlow (Commits: 33339, Contributors: 1469)
TensorFlow is a popular framework for deep and machine learning, developed in Google Brain. It provides abilities to work with artificial neural networks with multiple data sets. Among the most popular TensorFlow applications are object identification, speech recognition, and more. There are also different layer-helpers on top of regular TensorFlow, such as tflearn, tf-slim, skflow, etc.
This library is quick in new releases, introducing new and new features. Among the latest are fixes in potential security vulnerability and improved TensorFlow and GPU integration, such as you can run an Estimator model on multiple GPUs on one machine.
14. PyTorch (Commits: 11306, Contributors: 635)
PyTorch is a large framework that allows you to perform tensor computations with GPU acceleration, create dynamic computational graphs and automatically calculate gradients. Above this, PyTorch offers a rich API for solving applications related to neural networks.
The library is based on Torch, which is an open source deep learning library implemented in C with a wrapper in Lua. The Python API was introduced in 2017 and from that point on, the framework is gaining popularity and attracting an increasing number of data scientists.
15. Keras (Commits: 4539, Contributors: 671)
Keras is a high-level library for working with neural networks, running on top of TensorFlow, Theano, and now as a result of the new releases, it is also possible to use CNTK and MxNet as the backends. It simplifies many specific tasks and greatly reduces the amount of monotonous code. However, it may not be suitable for some complicated things.
This library faced performance, usability, documentation, and API improvements. Some of the new features are Conv3DTranspose layer, new MobileNet application, and self-normalizing networks.
Distributed Deep Learning
16. Dist-keras / elephas / spark-deep-learning (Commits: 1125 / 170 / 67, Contributors: 5 / 13 / 11)
Deep learning problems are becoming crucial nowadays since more and more use cases require considerable effort and time. However, processing such an amount of data is much easier with the use of distributed computing systems like Apache Spark which again expands the possibilities for deep learning. Therefore, dist-keras, elephas, and spark-deep-learning are gaining popularity and developing rapidly, and it is very difficult to single out one of the libraries since they are all designed to solve a common task. These packages allow you to train neural networks based on the Keras library directly with the help of Apache Spark. Spark-deep-learning also provides tools to create a pipeline with Python neural networks.
Natural Language Processing
17. NLTK (Commits: 13041, Contributors: 236)
NLTK is a set of libraries, a whole platform for natural language processing. With the help of NLTK, you can process and analyze text in a variety of ways, tokenize and tag it, extract information, etc. NLTK is also used for prototyping and building research systems.
The enchantments to this library cover minor changes in APIs and compatibility and a new interface to CoreNLP.
18. SpaCy (Commits: 8623, Contributors: 215)
SpaCy is a natural language processing library with excellent examples, API documentation, and demo applications. The library is written in the Cython language which is C extension of Python. It supports almost 30 languages, provides easy deep learning integration and promises robustness and high accuracy. Another great feature of spaCy is an architecture designed for entire documents processing, without breaking the document into phrases.
19. Gensim (Commits: 3603, Contributors: 273)
Gensim is a Python library for robust semantic analysis, topic modeling and vector-space modeling, and is built upon Numpy and Scipy. It provides an implementation of popular NLP algorithms, such as word2vec. Although gensim has its own models.wrappers.fasttext implementation, the fasttext library can also be used for efficient learning of word representations.
Data Scraping
20. Scrapy (Commits: 6625, Contributors: 281)
Scrapy is a library used to create spiders bots that scan website pages and collect structured data. In addition, Scrapy can extract data from the API. The library happens to be very handy due to its extensibility and portability.
Among the advances made through the year are several upgrades in proxy servers and improved system of errors notification and problems identification. There are also new possibilities in metadata settings using scrapy parse.
Conclusion
This is our enriched collection of Python libraries for data science in 2018. Comparing to the previous year, some new modern libraries are gaining popularity while the ones that have become classical for data scientific tasks are continuously improving.
Again, there is a table that shows detailed statistics of github activities.
Even though we have extended our list this year, it still may not cover some other great and useful libraries that deserve to be looked at. So, share your favorites in the comment section below, as well as any ideas about the packages that we mentioned.
Thank you for your attention!
ActiveWizards is a team of data scientists and engineers, focused exclusively on data projects (big data, data science, machine learning, data visualizations). Areas of core expertise include data science (research, machine learning algorithms, visualizations and engineering), data visualizations ( d3.js, Tableau and other), big data engineering (Hadoop, Spark, Kafka, Cassandra, HBase, MongoDB and other), and data intensive web applications development (RESTful APIs, Flask, Django, Meteor).
Original. Reposted with permission.
Related:
- Top 20 R Libraries for Data Science in 2018
- Top 15 Scala Libraries for Data Science in 2018
- Top 15 Python Libraries for Data Science in 2017