Can Data Science Be Agile? Implementing Best Agile Practices to Your Data Science Process
Agile is not reserved for software developers only -- that's a myth. While these effective strategies are not commonly used by data scientists today and some aspects of data science make Agile a bit tricky, the methodology offers plenty of benefits to data science projects that can increase the effectiveness of your process and bring more success to your outcomes.
By Jerzy Kowalski, Python Developer at STX Next.
I’ve often seen the opinion that Agile and Data Science don’t go well together. If that’s true, then it would mean Agile is unpopular among Data Scientists.
Since I prefer proper analysis over anecdotal evidence, I set out to verify this claim and learn whether Data Scientists use Agile. I found that they do, but also that they could certainly be using it more.
That inspired me to make a case for implementing Agile to your Data Science projects. The result is this article.
Read on to find out:
- How popular is Agile with Data Scientists?
- What can you do to boost your Data Science process with Agile?
- Which best Agile practices should you apply to Data Science and why?
- Are there any downsides to implementing Agile in Data Science?
What is the percentage of Data Scientists using Agile?
One possible way to answer this question was to use the results from the Stack Overflow Survey. If you want to see the tech details of my analysis, I’ve made a jupyter notebook available for you.
Unfortunately, there was no question like “Do you use Agile?” there, so I picked the one about collaboration tools used instead. I’d assumed that if I found “Jira” as the answer, then there was a high chance the respondent was working in an Agile environment.
Don’t get me wrong. I don’t think you need to use Jira for Agile—there are tons of other tools for that out there. It’s also not a 100% guarantee that you’re working in Agile if you’re using Jira. I simply made the assumption that I considered to be the best possible approximation of “Do you use Agile?”
Answering the question of “Who uses Agile?” was much easier. “Which of the following describe you?” was just what I’d been looking for since one of the possible answers was “Data Scientist or Machine Learning specialist.”
Okay, enough theory. Let’s see some visuals now!

Clearly, Data Scientists are not industry leaders in this area since only 54.9% use Agile. The results get worse with similar roles, except for Data Engineers, who aren’t far from the best here. Also, there’s a positive correlation in terms of “engineeringness” between Data Scientists and the percentage of Agile users within that group.
Based on my findings, we can’t say that Data Scientists know nothing about Agile. But there’s definitely room for improvement, so let’s take a look at some of the possible ways to incorporate Agile into your Data Science projects.
How to make your Data Science efforts more Agile
There are plenty of ways to boost your Data Science process with Agile. Let’s dive into two best practices I think are extremely valuable, whether you’re a Data Engineer, Data Scientist, or Software Engineer.
1. Divide and conquer
TL;DR: it’s easier to solve and manage smaller problems than to try to do everything at once.
I’m assuming that you have at least some basic system of defining tasks in your project. Perhaps you use tools like Jira or Trello for it or a to-do list in a dedicated document somewhere. The tool doesn’t really matter.
Now step back and think about the tasks that you or anybody else from your team failed to deliver on time. I’m pretty positive that among such tasks were the ones that were too big to be completed in a given timebox.
Why do we create monstrous tasks? First of all: there’s often a huge temptation to start coding as fast as possible. When new, exciting stuff is waiting around the corner, a thorough discussion on what actually needs to be done may seem boring. Beware, it’s a trap! Unless you talk the task through, you miss obstacles and risk underestimating it.
Let’s consider the following scenario: you’re working on a system to recognize hot dogs and were given a massive collection of pictures you can use to train your model. An impatient voice in your head tells you to quickly create a new item in your to-do list, call it “Improve model accuracy,” and… start coding. Then, you’re asked how long it will take, and you quickly respond, “three days.”
After two weeks of uneven war with sausages, you find yourself explaining to your unhappy stakeholder that it was harder than you’d initially assumed since many of the pictures tagged “hot dog” were actually pictures of… bananas.
If you had given yourself the time to think through what needs to be done, then you would’ve likely split it into smaller chunks. Perhaps you would’ve held off your three-day estimate until the initial dataset analysis was done.
When splitting a task, remember to do it so that each chunk will actually bring some value. The “vague deliverables” section below contains more detailed guidelines on that.
Last but not least: smaller tasks often mean earlier feedback. If, after one day of dataset analysis, you had informed your stakeholder that it’s messy, then they may have decided to skip it and have you work on a more relevant task instead.
2. Retrospectives
Scrum is an Agile framework to help you organize the process of delivering a product. One of the components of Scrum is a set of events that are designed to address most of the problems that might occur during the development of the project.
It’s hard to pick the most valuable one since they all complement each other. But if I had to convince a Scrum skeptic to start using Scrum events, I would start with retrospectives.
A retrospective means time dedicated to stop and reflect on things that are and aren’t going well.
Here’s the nitty-gritty:
- Give your team a couple of minutes to think about the good and the bad things that have happened recently in your project. Have everybody write down the ones they want to talk about.
- Collect all the notes, then try to find and merge duplicates.
- Again, give yourself a couple of minutes to vote for the topics that seem the most relevant to you.
- Now it’s time to have a group discussion, starting with the topics that received the most votes. Try to come up with a plan to improve on the pain points.
Retros can take many different forms, and you’re free to come up with a new one.
Speaking of tools: if you’ve got the luxury of meeting in person, then good old sticky notes will do the trick. If not, then finding an online solution is as easy as googling “retrospective tools.”
Giving yourself space to inspect recent events and activities is never a bad idea. I highly recommend you try it with your team.
Note that Scrum is by and large more than just a fancy meeting or two! The Scrum Guide is undoubtedly one of the best resources to get a broader perspective on what Scrum is. Hopefully, reading it will convince you to try out more, if not all, of its components.
The benefits of best Agile engineering practices: unit testing and test-driven development
Apart from process-level Agile enhancements, there are also many low-level techniques to improve your work. They include code review, pair programming, continuous integration—just to name a few.
I believe all are applicable to the Data Science world, but here I’d like to focus on two: unit testing and test-driven development. Both are prominent examples of Agile applied to software engineering, and each of them ranks in the top 10 Agile engineering practices according to the latest State of Agile Report.
If you’re not writing unit tests, then you’re probably testing your functions within some REPL, or you’re writing temporary scripts to do the job. The problem with such an approach is that your tests are gone as soon as you close the REPL or remove the test script.
Now, imagine that your tests are stored and shared. They are run along with many others cyclically, e.g., before every commit. You’ve just gained a safeguard that will ensure your function behaves as expected. If any change breaks it, you’ll know it immediately.
What’s more, you can think of your test cases as living documentation. You’ll probably agree that “examples” are the hottest part of most docs. And now you’ve got your own “examples” section: your test suite, explaining how to use a function and what the expected outputs are.
Additionally, if you’re writing tests before code—which is basically what TDD is all about—then you gain even more. Since it’s cumbersome to come up with a test that checks multiple things at once, you’re better off keeping it simple and only checking whether the correct output is returned given some input. Therefore, when writing a function, you’ll want to focus only on meeting the defined requirement.
This way, the function will remain a compact, highly specialized tool for a particular task instead of a blob of magic code. I’d argue that smaller functions are usually easier to understand, so it’s fair to say that TDD provides better design and enhanced readability.
Applying unit testing and test-driven development to Data Science
Now, let’s answer the big question: how are unit tests and TDD applicable to the world of Data Science? Well, if your day-to-day job includes data wrangling with libraries like NumPy or Pandas, then it’s perfect for TDD!
Consider the following problem: you were given a Pandas DataFrame that has columns containing string entries with multiple values separated by semicolons:

Your task is to transform the DataFrame so that each row has a single b-column entry. It's similar to Pandas’ explode, but with a semicolon-separated string as the input.

We’ve got the sample input, and we know the desired output. That’s everything you need to know to write a test! Let’s create a test_utils.py file and turn our requirements into code:
import pandas as pd
from utils import explode_str_column
def test_explode_str_column():
input_df = pd.DataFrame(
{
"a": [1, 2],
"b": ["foo;bar", "spam;ham;eggs"]
}
)
column_to_explode = "b"
expected_df = pd.DataFrame(
{
"a": [1, 1, 2, 2, 2],
"b": ["foo", "bar", "spam", "ham", "eggs"]
},
index=[0, 0, 1, 1, 1]
)
actual_df = explode_str_column(input_df, column_to_explode)
If you run the test file with pytest test_utils.py—naturally, you need to have pytest installed for that—it will fail since there is no utils module with the explode_str_column function. That’s all right. When using TDD, you first define your requirements as a failing test, then provide implementation so that your test passes.
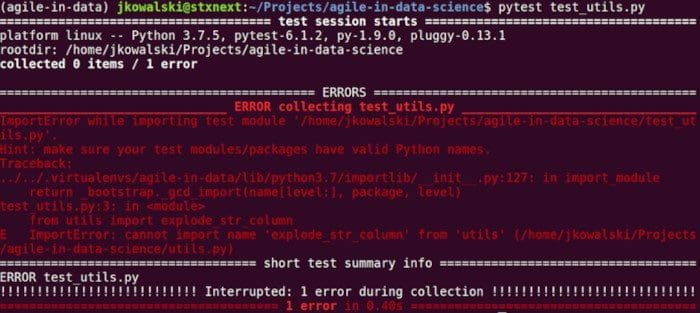
Now, let’s create the explode_str_column function in a new utils module:
def explode_str_column(df, column):
df[column] = df[column].str.split(";")
return df.explode(column)
Rerunning pytest test_utils.py gives you a beautiful green log, meaning that you did a great job!

And that’s it! Wasn’t hard or scary, was it? Now, as homework of sorts, you may enhance the function so that it meets additional requirements, like handling different separators or avoiding mutation of the input DataFrame.
Remember to start with a failing test checking the new requirement, then write a solution. Make sure the previous tests aren’t failing! You can additionally refactor your code so that your solution is cleaner and/or better performing. If you’re done with the requirement, you should repeat the process for a new one.
Now you know how to make your development process more Agile with unit tests and TDD. Using such techniques allows you to tackle data manipulation problems and gives you more reliable, readable, and better-designed solutions.
I’m certain that shortly after you incorporate them into your daily routine, you’ll start seeing more and more use cases!
What are the challenges and risks in implementing Agile?
1. Vague deliverables
The main challenge for Data Scientists when working in Agile is that the output of their work is often vague.
Let’s compare that to web developers. Most of the time, they have very concrete tasks, like tweaking a form or adding a new filter. The outputs of such tasks are rather tangible. Users can click on the new interface items, and the value provided is fairly easy to recognize.
Now, think about standard Data Science tasks, such as raw data cleanup, initial data analysis, or improving a prediction model. The hard part is to organize your work so that the output is presentable and ideally usable to end-users.
It may not be straightforward, but answering the following questions before hopping onto the task should make it easier:
- Who is your end-user?
Don’t think about the end-user only as a client. It’s great if you have those, but you should consider everyone who will use your software.
- Why do you need “X”?
Try to understand the reasoning behind what you’re doing. Ask as many questions as possible to detect risks early.
- How will “X” be used?
Avoid writing scripts that just fill the void. Create something that is actually valuable for your end-user. Perhaps that’s a CLI tool, a jupyter notebook with some informative analysis, or a tiny library. Preparing a Definition of Done document for your project will help clarify what can be treated as a deliverable.
Now, write down your answers in the description of your user story.
Finally, don’t forget to apply the “divide and conquer” approach I mentioned before. Try to identify the smallest valuable deliverables. Remember: the outcome of your work should not be murky just because there’s no clickable interface!
2. Research and prototyping
Prototyping is all about validating whether the further journey down the rabbit hole makes any sense. Fast.
At first, Agile engineering practices may seem to slow you down. Pair programming requires two engineers: couldn’t they implement twice as much code at the same time? Also, why should you care about tests? It’s just more code to write and maintain—and it takes time! Believe it or not, I’ve actually heard such arguments from managers…
The sad fact is that most prototype code ends up in the trash. There’s no denying it. So is it worth it to care about the quality of such code? I’d argue it is.
Prototypes often end up being forgotten scripts living in some ancient repositories. But from time to time, somebody (including you!) may want to give them a second life. If the code is a total mess, the resurrection won’t happen, or it will be a painful one.
And what if your prototype is successful? I bet that as soon as you show promising results to the broader public, there will be people who will want to use it... right now. But if you create a Frankenstein’s monster, you’ll be the one dealing with it. Respecting good practices pays dividends at such moments.
To sum up: when you’re implementing a prototype, focus on delivering working software relatively fast. But don’t treat it as a green light for gigantic functions or any other lousy stuff. Perhaps refactor your code less frequently and don’t aim for 100% test coverage. Allow yourself to be less rigorous, but try to find a balance.
Final thoughts
When all is said and done, it’s plain to see that Agile is not reserved for software developers only. The numbers prove that it’s absolutely also used in other areas of IT.
There are plenty of Agile practices that are effectively applicable to a wide array of problems, such as unit testing and test-driven development.
However, there are aspects of the Data Science world that make it harder to go Agile. I’d argue that the more engineering responsibilities you have, the more Agile practices it’ll be easy for you to apply with success. On the flip side, Agile for analytics and research often requires a substantial change of perspective.
All in all, I strongly believe that regardless of the nature of your project, you will benefit from incorporating Agile into your process. I hope that these guidelines will help you take your first steps in this direction.
Bio: Jerzy Kowalski is a Python aficionado using his favourite language to solve machine learning and web development problems. Propagating functional programming and TDD practices where possible, Jerzy applies Agile to improve the software development process.
Related: