Fine-Tuning BERT for Tweets Classification with HuggingFace
In this blog, we used the Hugging Face library to fine-tune BERT on the classification task. We classified tweets related to COVID.

Bidirectional Encoder Representations from Transformers (BERT) is a state of the art model based on transformers developed by google. It can be pre-trained and later fine-tuned for a specific task. we will see fine-tuning in action in this post.
We will fine-tune BERT on a classification task. The task is to classify the sentiment of COVID related tweets.
Here we are using the HuggingFace library to fine-tune the model. HuggingFace makes the whole process easy from text preprocessing to training.
BERT
BERT was pre-trained on the BooksCorpus dataset and English Wikipedia. It obtained state-of-the-art results on eleven natural language processing tasks.
BERT was trained on two tasks simultaneously
- Masked language modelling (MLM) — 15% of the tokens were masked and was trained to predict the masked word
- Next Sentence Prediction(NSP) — Given two sentences A and B, predict whether B follows A
BERT is designed to pre-train deep bidirectional representations from an unlabeled text by jointly conditioning on both left and right context in all layers.
As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
Dataset
We are using the Coronavirus tweets NLP — Text Classification dataset available on Kaggle.
The dataset has two files Corona_NLP_test.csv (40k entries) and Corona_NLP_test.csv (4k entries).
These are the first five entries of training data:
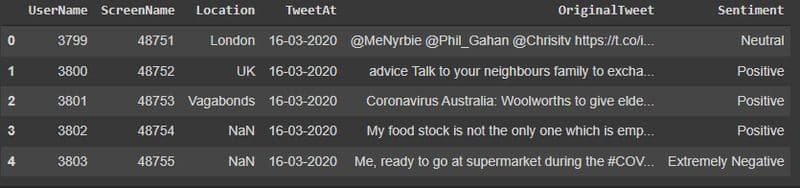
As you can see we have 5 features in our data: UserName, ScreenName Location, TweetAt, OriginalTweet, Sentiment, but we are only interested in 2 i.e OriginalTweet contains the actual tweet and Sentiment which are labels for our Tweet.
These tweets are classified into 5 categories — ‘Neutral’, ‘Positive’, ‘Extremely Negative’, ‘Negative’, ‘Extremely Positive’. Hence the number of labels is 5.
Loading Data and Preprocessing
We will be using the HuggingFace library for this project. we need to install the two modules:
pip install transformerspip install datasets
- transformers: HuggingFace implementation of transformers. We can download a wide range of pre-trained models
- datasets: Loading the dataset and also different datasets can be downloaded that are available of HuggingFace hub
from datasets import load_dataset
Here we are using load_dataset from datasets library. load_dataset can be used to download datasets from the HuggingFace hub or we can load our custom dataset.
We specified the datatype as CSV, passing file names as dictionaries to data_files. we are loading our train and test files into the dataset variable.
Here is the output if we print the dataset variable:
Preprocessing Data
We will keep it simple and only do 2 pre-processing steps i.e tokenization and converting labels into integers.
HuggingFace AutoTokenizertakes care of the tokenization part. we can download the tokenizer corresponding to our model, which is BERT in this case.
BERT tokenizer automatically convert sentences into tokens, numbers and attention_masks in the form which the BERT model expects.
e.g: here is an example sentence that is passed through a tokenizer
>> tokenizer("Attention is all you need")output:
{
'input_ids': [101, 1335, 5208, 2116, 1110, 1155, 1128, 1444, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]
}
Now as part of the preprocessing steps, we will perform two steps:
- Convert Sentiment into an integer
- Tokenize the tweets
We will be using map function of the dataset which is similar to apply function of the pandas data frame. It takes a function as an argument and applies to the entire dataset.
In the above code, we defined a method to convert labels into integers and tokenized the tweets also dropped the unwanted columns.
Now we are all set for the training part.
Training
There are two ways to train the data, either we write our own training loop or we can use trainer from the HuggingFace library.
In this case, we will use trainer from the library. To use trainer, first we need to define the training arguments like name, num_epochs, batch_size etc.
Let’s download the BERT model now, which is very simple using the AutoModelForSequenceClassificatio class.
The classification model downloaded also expects an argument num_labels which is the number of classes in our data. A linear layer is attached at the end of the BERT model to give output equal to the number of classes.
(classifier): Linear(in_features=768, out_features=5, bias=True)
The above linear layer is automatically added as the last layer. Since the BERT output size is 768 and our data has 5 classes so a linear layer with in_features=768 and out_features as 5 is added.
Before starting the training, we will split our training data into train and evaluation sets. We have 40k in training and 1k in eval set.
If we are using a HuggingFace trainer we need to import the module Trainer and pass model, dataset and training arguments to it.
That’s it, now we are all set to start the training. We need to call train method on trainer and training will start
trainer.train()
Training will run for 3 epochs which can be adjusted from the training arguments.
Once training is done we can run trainer.evalute() to check the accuracy, but before that, we need to import metrics.
The datasets library offers a wide range of metrics. We are using accuracy here. On our data, we got an accuracy of 83% by training for only 3 epochs.
Accuracy can be further increased by training for some more time or doing some more pre-processing of data like removing mentions from tweets and unwanted clutter, but that’s for some other time.
Thanks for reading.
Rajan Choudhary is a QA Engineer at Mcafee with 2+ years experience.