How to Generate Synthetic Tabular Dataset
Check out this article on using CTGANs to create synthetic datasets for reducing privacy risks, training and testing machine learning models, and developing data-centric AI products.

Image by author
Companies often come across the problem where they don't have enough real-life data or they cannot use actual data due to privacy concerns. This is where synthetic data generation comes to the rescue. Researchers and data scientists are using synthetic data to build new products, improve the performance of machine learning models, replace sensitive data, and save costs in acquiring the data. Read more at The Ultimate Guide to Synthetic Data.
The synthetic data is used in the healthcare sector, self-driving cars, financial sectors, maintaining a high level of privacy, and for research purposes - Towards Data Science. Last year the entire Kaggle’s Tabular Playground Series dataset was developed using CTGANs. The Kaggle team has used the old datasets from various competitions to generate artificial datasets. It was a genius move by Kaggle as it made cheating hard. In this blog, we are going to learn about various methods to generate tabular data using SDV’s Python library.
CTGANs
CTGAN uses several GAN-based methods to learn from original data and generate highly realistic tabular data. To produce synthetic tabular data, we will use conditional generative adversarial networks from open-source Python libraries called CTGAN and Synthetic Data Vault (SDV). The SDV allows data scientists to learn and generate data sets from single tables, relational data, and time series. It is the one-stop solution for all kinds of tabular data.
With a few lines of code, our deep learning model can learn and generate sample tabular data. In the example below, we have initialized the model, trained it on real data, saved the model, and then generated 200 samples. This is just a start, we will also learn various ways to generate artificial data and then evaluate the results.
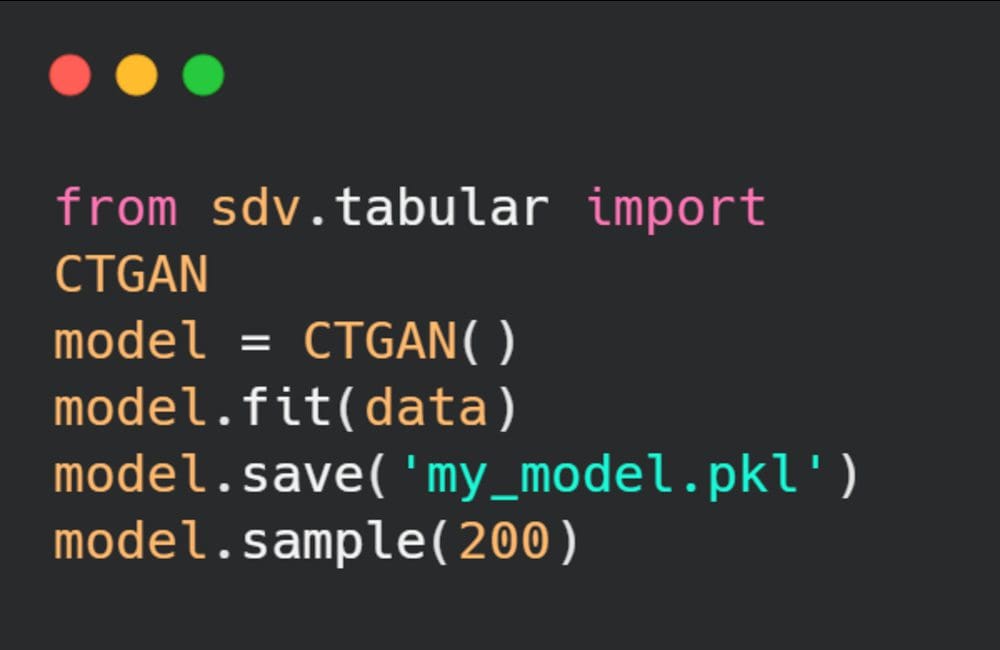
Image by author
Tutorial
In this tutorial, we are going to use the Food Demand Forecasting | Kaggle (under DbCL license) dataset to create a synthetic dataset. We will experiment with a vanilla model, custom model and finally evaluate results. The results will help us determine the quality of generated data. We will be using a Deepnote cloud notebook for generating the results.
CTGANSynthesizer
First, we need to install the CTGAN library by using ` pip install ctgan` and then load our dataset using Pandas. We are shuffling the dataset to get truly randomized two thousand samples. We are using a lower number of samples to reduce training duration.
from ctgan import CTGANSynthesizer
import pandas as pd
data = pd.read_csv("/work/food-demand-forecasting/train.csv")\
.sample(frac=1).reset_index(drop=True)[0:2000]
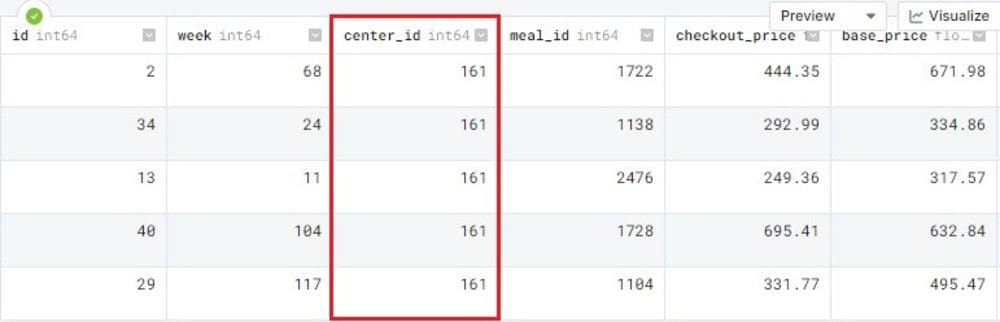
Before we start model training let's observe our actual dataset so that we can see the difference between real and artificial.
data.head()
In order to train our CTGAN model, we need to provide a list of discrete columns, batch size, and the number of epochs. The API is similar to Scikit-learn where we initialize the model with hyperparameters and then train the model using `.fit()`. After successfully training the model, we are going to save our model to reproduce similar results. With `ctgan.sample(2000)` we are going to generate 2k samples.
discrete_columns = ['week',
'Center_id',
'Meal_id',
'Emailer_for_promotion',
'homepage_featured']
ctgan = CTGANSynthesizer(batch_size=50,epochs=5,verbose=False)
ctgan.fit(data,discrete_columns)
ctgan.save('ctgan-food-demand.pkl')
samples = ctgan.sample(2000)
samples.head()
As we can observe, the output is quite similar to the original data. The results are acceptable.
SDV
In this part, we are going to use the SDV library to generate data. SDV provides us with multiple single table models and also provides more features to run data generation experiments.
First, we are going to initialize the model by providing a primary key and decimal places for floating features. Then, we are going to train our model and generate 200 samples.
from sdv.tabular import CTGAN
model = CTGAN(primary_key='id',rounding=2)
model.fit(data)
model.save("sdv-ctgan-food-demand.pkl")
new_data = model.sample(200)
new_data.head()
As we can see, the id column started with 0 and the overall data looks clean. To fully understand our synthetic data, we need to evaluate the dataset using similarity metrics and comparing the data distribution.
Evaluation
We will be using the SDV evaluate function to analyze the similarity between real and fake datasets. This function displays aggregated results of all of the similarity metrics from 0 to 1, where 0 begins worst and 1 is ideal. In our case, the similarity metric is (0.34) which is bad and we need to work more on hyperparameter optimization to get better results.
from sdv.evaluation import evaluate evaluate(new_data, data) >>>> 0.34091406940696406
TableEvaluator is used to evaluate the similarity between a synthesized and a real dataset. It was exclusively built for analyzing the performance of GAN-based tabular models. By writing a few lines of code, we can compare both datasets on the absolute log mean, distribution of all features, correlation matrix, and first two components of PCA.
from table_evaluator import load_data, TableEvaluator table_evaluator = TableEvaluator(data, new_data) table_evaluator.visual_evaluation()
By observing all the visualizing, we can conclude that the data features distribution is somehow similar but principal component analysis distribution is completely different from real data.
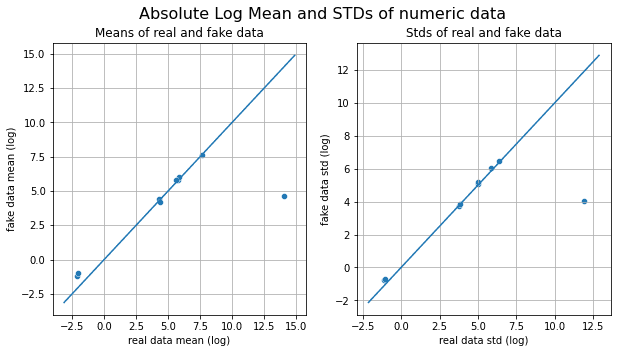
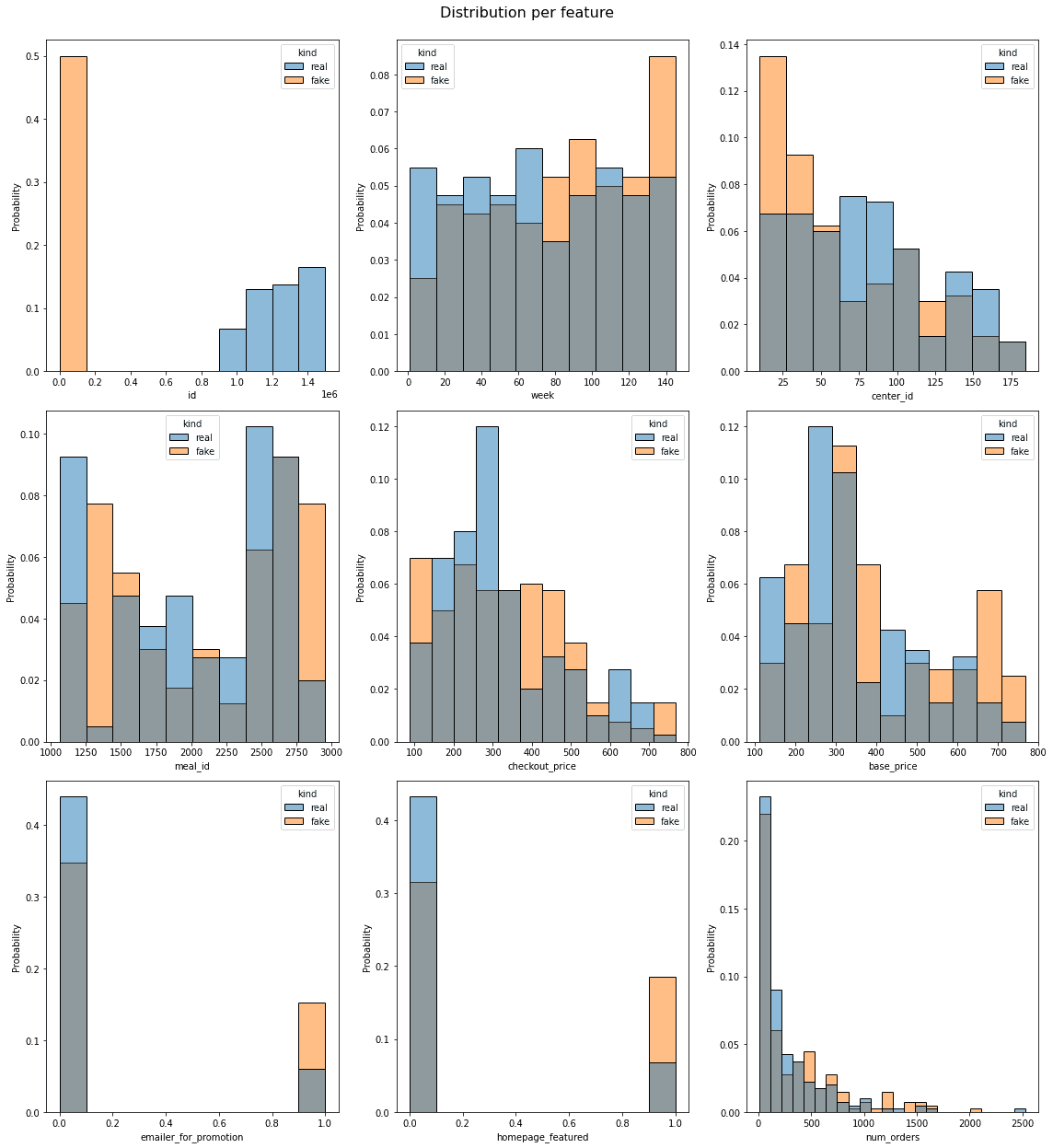
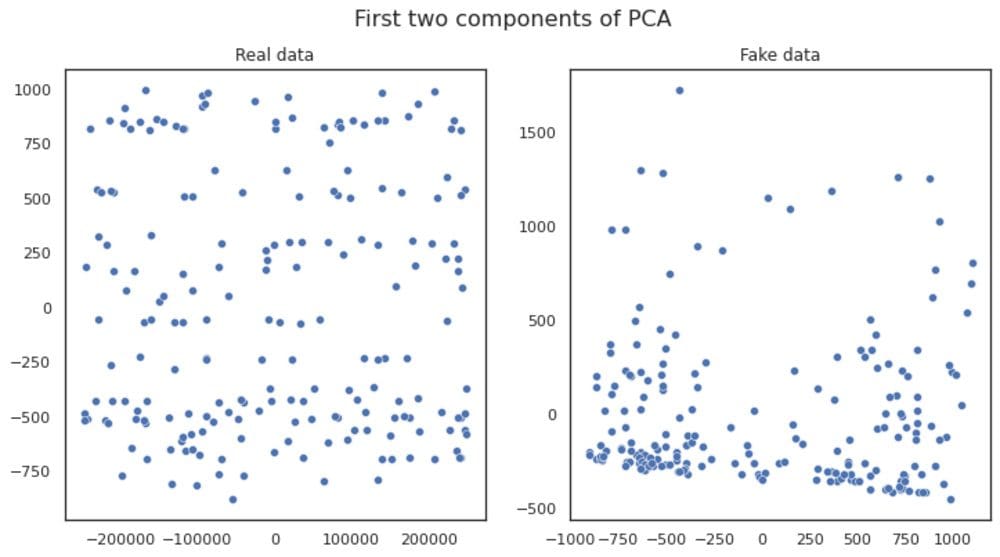
Custom Model
Let’s create a customized model to improve the similarity metric by changing, number of epochs, bach_size, generator dimensions, and discriminator dimensions.
model = CTGAN(
epochs=500,
batch_size=100,
generator_dim=(256, 256, 256),
discriminator_dim=(256, 256, 256)
)
model.fit(data)
model.save("manual-CTGAN.pkl")
We can also customize the generated dataset by creating constants. Let's say we want to generate data for center_id 161. We will first create a dictionary of "conditions" and pass it to a sample function as shown below.
conditions = {"center_id": 161}
model.sample(5, conditions=conditions)
With light hyper-parameter optimization we have achieved a better similarity score (0.53) as shown below. If your generated dataset is soaring between 0.6 to 0.7 then your dataset is ready for production.
new_data = model.sample(2000) evaluate(new_data, data) >>>> 0.517249739944206
SDV for Relational and Time Series
We can also use the SDV library to generate relational dataset using `sdv.relational.HMA1` and time series data using `sdv.timeseries.PAR`. The API works similar CTGAN model, we just need to train the model and then generate N numbers of samples.
Relational Data
Hierarchical Modeling Algorithm is an algorithm that allows one to recursively walk through a relational dataset and apply tabular models across all the tables. In this way, models learn how all the fields from all the tables are related.
Time Series
Probabilistic AutoRegressive allows learning multi-type, multivariate time series data and later on generates new synthetic data that has the same format and properties as the learned one.
Conclusion
I use CTGANs to improve my machine learning model performance and assess model accuracy on the unseen dataset. It has also helped me with an unbalanced class dataset. If you have limited training data and you want to develop an AI product without investing a lot of money in occurring data then you should consider generating synthetic datasets. The synthetic dataset is not limited to tabular as we can now use GANs to generate images, audio, and text dataset. Creating artificial data is an ever-growing field. In the future, it will surpass the real dataset.
In this blog, we have learned about CTGANs and how to use the SDV library to generate the tabular dataset. We have also learned that we can generate relation and times series data with a similar API. I hope you enjoyed the short tutorial and if you have any questions about debugging the code, comment below.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.