The Evolution of Apache Druid
And so true to the origins of its name, Apache Druid is shapeshifting - with the addition of a new multi-stage query engine.
For several years now, software developers at 1000s of companies including Netflix, Confluent, Target, and Salesforce have turned to Apache Druid to power their analytics applications. Druid has been the database-of-choice for its ability to deliver an interactive data experience without any limitations to data volume or concurrency requirements.
Apache Druid excels at interactive slice-and-dice on multi-dimensional, high-cardinality data at any scale. It is designed to support fast moving, high volume data for any number of users and can scale from a single node to thousands easily in a flexible, distributed architecture. The largest Druid installations scale to petabytes of data served by thousands of data servers, and are able to return queries on billions and billions of rows in less than a second.
But my experience is that while Druid is ideal for interactive slice-and-dice, this is not the full story for a modern analytics application. Increasingly there are other user-facing features that analytics apps need, like data exports and reports, that rely on much longer-running or more complex queries that aren’t ideal for Druid. Today, developers handle these workloads by using other systems alongside Druid. But this adds cost and complexity: the same data must be loaded up twice and two separate data pipelines must be managed.
And so true to the origins of its name, Apache Druid is shapeshifting - with the addition of a new multi-stage query engine. But before diving into the new engine, let’s look at how Druid’s core query engine executes queries to compare the difference.
Druid Query Execution Today
Performance is the key to interactivity, and in Druid, “don’t do it” is the key to performance. It means focusing on efficiency and minimizing the work the computer has to do.
Druid is great at this because it is designed from the ground up to be efficient. Druid has a tightly integrated query engine and storage format, designed in tandem to minimize the amount of work that each data server has to do.
Druid's query engine executes queries with a “scatter/gather” technique: it quickly identifies which segments are relevant to a query, pushes the computation down to individual data servers, then gathers filtered and aggregated results from each server via what we call a Broker, which then performs a final merge and returns results to the user.
Each data server may be processing billions of rows, but the partial result set returned to the Broker is much smaller due to pushed-down filters, aggregations, and limits. So, Brokers normally deal with relatively small amounts of data. This design means a single Broker can handle a query that spans thousands of data servers and trillions of rows.
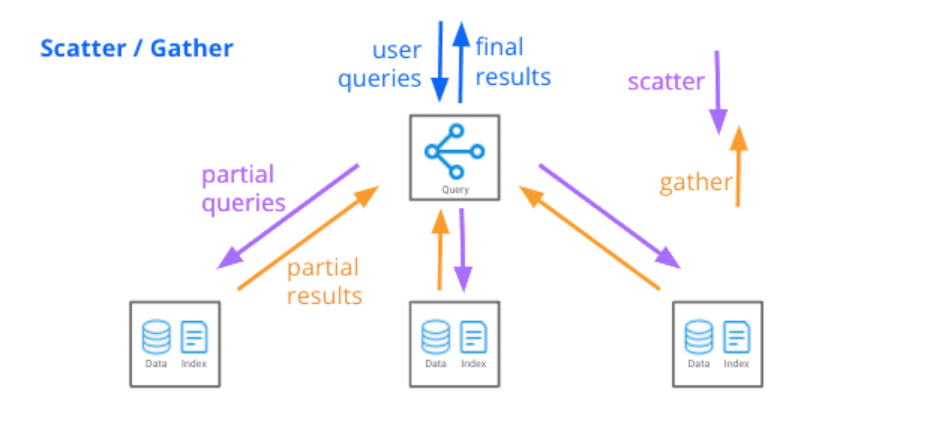
Scatter/gather is very efficient and performant for the types of queries used in analytics applications. But the technique has one Achilles’ heel: the Broker can turn into a bottleneck when query results are very large, or when a query is structured in such a way that multiple passes over the data are required.
A New Multi-Stage Query Engine
When we set out to rethink how long-running queries could work in Druid, we knew that it was important to keep all the good aspects: namely, very tight integration with the storage format, and excellent data server performance. We also knew we needed to retain the ability to use a lightweight, high-concurrency scatter/gather approach for queries where the bulk of processing can be done on the data servers. But we would have to also support exchanging data between data servers, instead of requiring that every query use scatter/gather.
To accomplish this, we’re building a multi-stage query engine that hooks into the existing data processing routines from Druid’s standard query engine, so it will have all the same query capabilities and data server performance. But on top of that, we’re adding a system that splits queries into stages and enables data to be exchanged in a shuffle mesh between stages. Each stage is parallelized to run across many data servers at once. There isn’t any need for tuning: Druid will be able to run this process automatically using skew-resistant shuffling and cooperative scheduling.
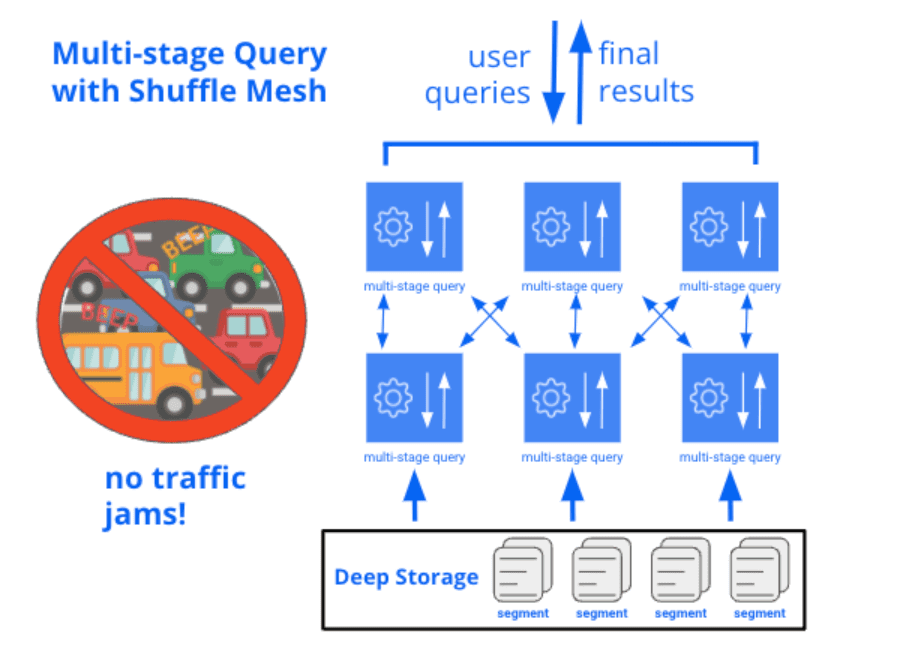
By allowing each stage of a multi-stage query to run distributed across the entire cluster, we can efficiently carry any amount of data through all stages of the query, instead of requiring that the bulk of data is processed at the bottom layer.
A New Standard for Analytics Databases
Once we started thinking it through, we realized that we could do much more than just handle complex queries. We could open up the ability to run queries and ingestion using a single system and a single SQL language. We could move past the need to have separate operational models for ingestion and query execution. We could enable querying external data, and enable deployment modes with separated storage and compute.
With this effort, we're building a platform for blending the performance of real-time analytical databases with the power and capabilities associated with traditional SQL RDBMS. I'm really excited about this direction for the project. Today, Druid is the most compelling database for real-time analytics at scale. As Druid gains this new functionality over time, it will become the most compelling analytics database period.
Gian Merlino is a co-author of the open source Apache Druid project and co-founder and CTO at Imply. Gian is also the Apache Druid Committee (PMC) Chair. Previously, Gian led the data ingestion team at Metamarkets and held senior engineering positions at Yahoo. He holds a B.S. in Computer Science from Caltech.