Ensemble Learning with Examples
Learn various algorithms to improve the robustness and performance of machine learning applications. Furthermore, it will help you build a more generalized and stable model.

Image by Author
What is Ensemble Learning?
Ensemble learning combines multiple models to obtain better model performance. It helps you improve robustness and provide a generalized model. In short, it combines different decisions from the model to improve performance.
In this tutorial, we will learn about various ensemble methods with examples. We will be using the Heart Attack Analysis & Prediction dataset from Kaggle. Our focus is to find the patents with higher and lower chances of heart attack using various features.
Output :
- 0 = less chance of heart attack
- 1 = more chance of heart attack
Averaging
We will start by importing the required utility and machine learning packages.
Simple Average
We will take a simple average by adding all of the models' output and dividing it by the total number of models.
- Loaded the heart.csv file using pandas.
- The target is the “output” feature.
- Drop “output” to create training features.
- Scaled the features using StandardScaler()
- Split the data into train and test sets.
- Build all three model objects. We are using RandomForestClassifier, LogisticRegression, and SGDClassifier.
- Training the model on a train set and predicting the output using a test set.
- Using the average formula and rounding the output to show only 1s and 0s.
- Displaying accuracy and AUC metrics.
Our model has performed well on default hyperparameters.
Accuracy: 85.246% AUC score: 0.847
Weighted Average
In the weighted average, we give the highest weight to best-performing models and the lowest weight to lower-performing models while taking an average.
| model_1 | model_2 | model_3 | |
| Weightage | 30% | 60% | 10% |
The code below shows that by giving more weightage to model_2, we have achieved better performance.
Note: while giving weightage, make sure they all add up to 1. For example, 0.3 + 0.6 + 0.1 = 1
Accuracy: 90.164% AUC score: 0.89
Max Voting
Max Voting is generally used for classification problems. In this method, each model makes a prediction and votes for each sample. From the sample class, only the highest-voted class is included in the final predictive class.
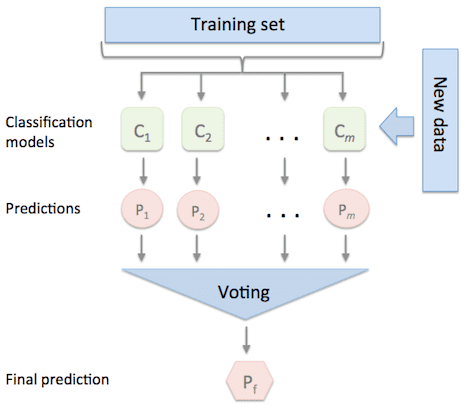
Image from rasbt.github.io
In the example below, I have added a fourth model KNeighborsClassifier. We will use Scikit-Learn’s VotingClassifier and add three classifiers: RandomForestClassifier, LogisticRegression, and KNeighborsClassifier.
As we can see, we got better results than the simple average.
Accuracy: 90.164% AUC score: 0.89
Stacking
Stacking combines multiple base models via meta-model (meta-classifier or meta-regression). The base models are trained on a full dataset. The meta-model is trained on the features from base models(outputs). The base models and the meta-model are generally different. In short, meta-models help base models to find useful features to achieve high performance.
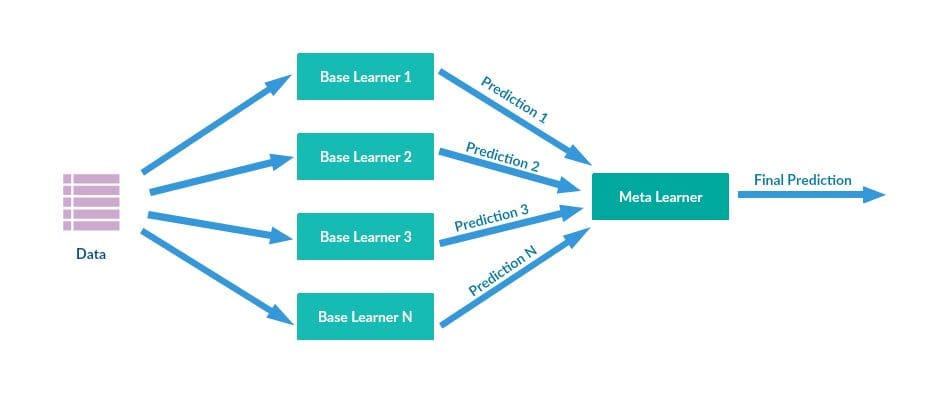
Image from opengenus.org
In the example, we are going to use Random forest, Logistic regression, and AdaBoost classifier for base models (estimators) and GradientBoosting classifier as meta-model (final_estimator).
Stacking the models did not produce better results.
Accuracy: 81.967% AUC score: 0.818
Bagging
Bagging, also known as Bootstrap Aggregating, is an ensemble method to improve the stability and accuracy of machine learning models. It is used for minimizing variance and overfitting. Generally, it is applied to decision tree methods.
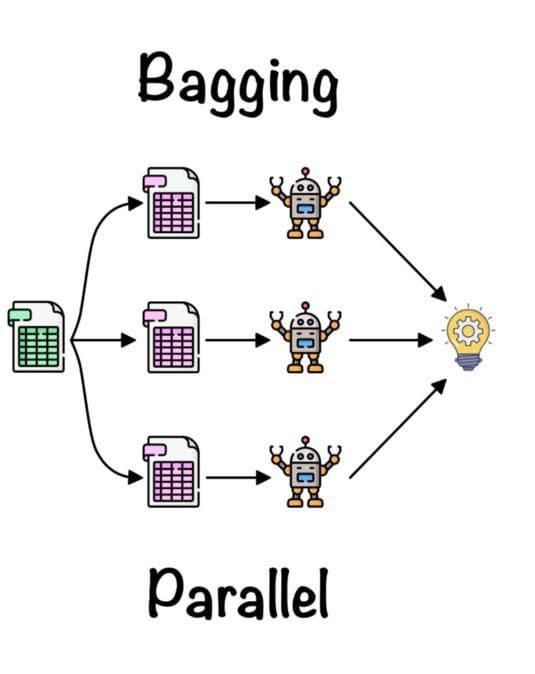
Bagging by Fernando López
Bagging randomly creates a subset of training data to get a fair distribution of the whole dataset and train the models on it. The final output is created by combining all of the output from the base model.
In our case, we will use one type of model and train it on various subsets of training data. A subset is also known as a bag hence the bagging algorithm.
In the example, we are using Scikit-learn's BaggingClassifier and utilizing Logistic regression as the base estimator.
Bagging algorithm has produced the best and reliable result.
Accuracy: 90.164% AUC score: 0.89
Boosting
Boosting combines weak classifiers to create a strong classifier. It reduces biases and improves the single model performance.
You can achieve high performance by training weak classifiers in series. The first model is training on training data, then the second model is trained to correct the error present in the first model. It is an iterative algorithm that adjusts weights based on the previous model.
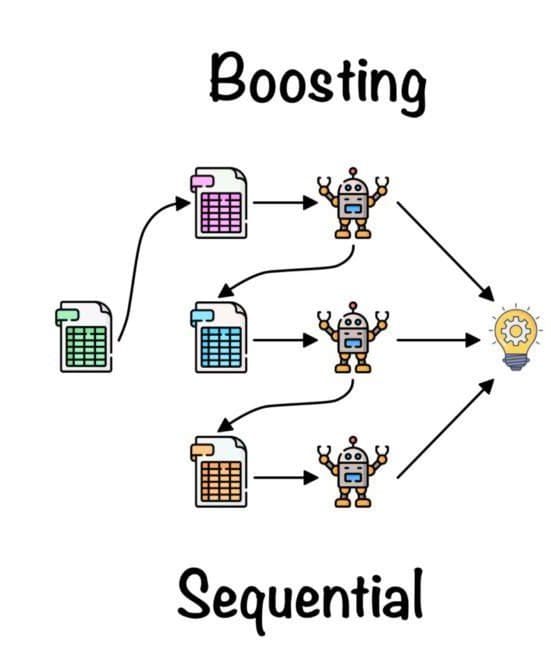
Boosting by Fernando López
The boosting algorithm gives more weightage to the observations that previous models have predicted accurately. This process continues until all training data sets are predicted correctly or it has reached the maximum number of models.
In the example, we will be using the AdaBoost classifier. The adaptive boosting algorithm (AdaBoost) is the OG technique of combining weak classifiers into a single powerful classifier.
Accuracy: 80.328% AUC score: 0.804
Conclusion
Even though ensemble learning should be applied to all machine learning applications, in the case of large neural networks, you need to consider throughput, computation, and cost of operation to decide whether to train and serve multiple models or not.
In this tutorial, we have learned the importance of ensemble learning. Furthermore, we have learned about averaging, max voting, stacking, bagging, and boosting with code examples.
I hope you like the tutorial, and if you have any questions regarding the best possible technique, do comment in the section below.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.