Introduction to Multi-Armed Bandit Problems
Delve deeper into the concept of multi-armed bandits, reinforcement learning, and exploration vs. exploitation dilemma.
A multi-armed bandit (MAB) is a machine learning framework that uses complex algorithms to dynamically allocate resources when presented with multiple choices. In other words, it’s an advanced form of A/B testing that’s most commonly used by data analysts, medicine researchers, and marketing specialists.
Before we delve deeper into the concept of multi-armed bandits, we need to discuss reinforcement learning, as well as the exploration vs. exploitation dilemma. Then, we can focus on various bandit solutions and practical applications.
What is Reinforcement Learning?
Alongside supervised and unsupervised learning, reinforcement learning is one of the basic three paradigms of machine learning. Unlike the first two archetypes we mentioned, reinforcement learning focuses on rewards and punishments for the agent whenever it interacts with the environment.

Real life examples of reinforcement learning are available to us on a daily basis. For instance, if your puppy chews through your computer cables, you may scold him and express your dissatisfaction at its actions. By doing so, you will teach your dog that destroying cables around the house is not a good thing to do. This is negative reinforcement.
Likewise, when your dog performs a trick it learned, you will give it a treat. In this case, you’re encouraging its behavior using positive reinforcement.
Multi-armed bandits learn the same way.
Exploration vs. Exploitation
This almost philosophical dilemma exists in all aspects of our life. Should you get your coffee from that place you visited on countless occasions after work, or should you try the new coffee shop that just opened across the street?
If you choose to explore, your daily cup of coffee may turn out to be an unpleasant experience. However, if you go ahead and exploit what you already know and visit the familiar place, you might miss out on the best coffee you would have ever tasted.
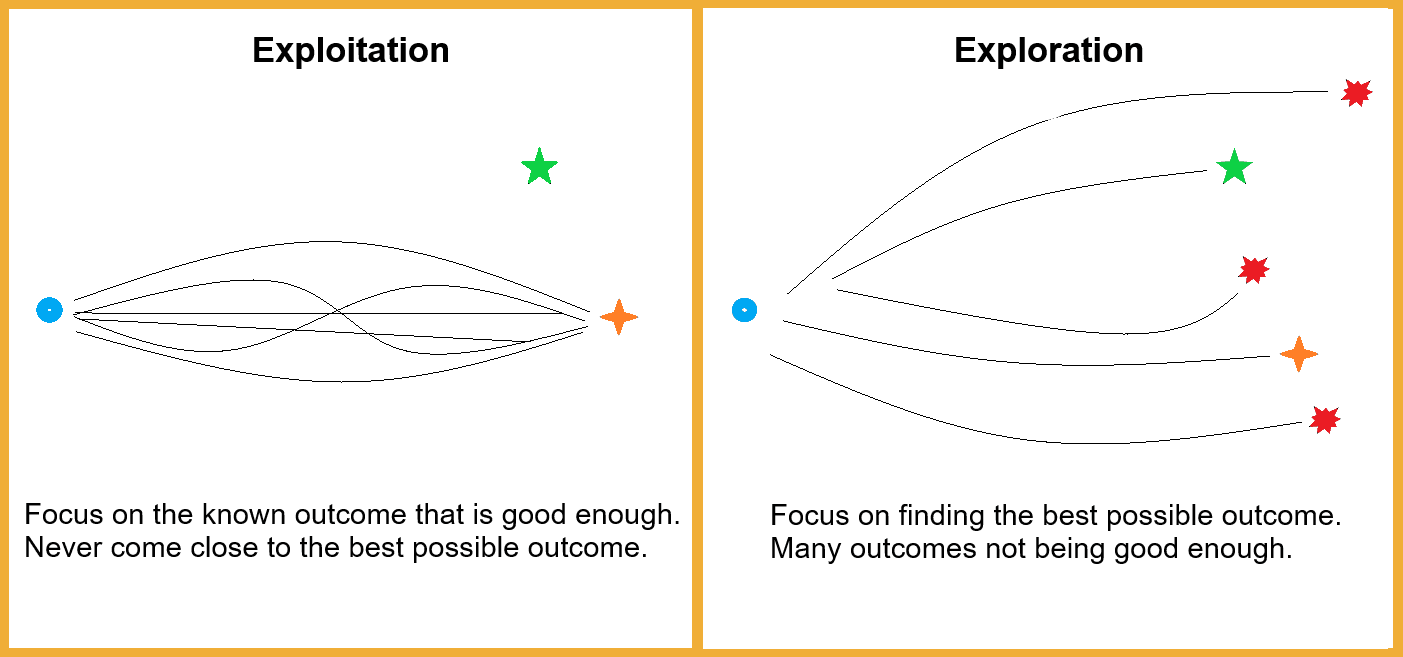
Multi-armed bandits tackle these issues in various fields of work and help data analysts determine the right course of action.
What are Multi-Armed Bandits?
A one-armed bandit is another name for a slot machine. There is no need to explain the meaning behind the nickname.
Multi-armed bandit problems were named after the infamous one-armed bandits. However, the acknowledgment was not on the basis of bandits and robbery, but the predetermined chances of getting a winning result in the long term when using slot machines.
To better understand how this works, let’s use another real life example. This time, you’re deciding where to buy your vegetables. There are three choices available. The supermarket, local grocery store, and the nearby farmers market. Each has different factors to consider, such as pricing and whether the food is organic, but we’ll focus solely on food quality for this example.
Let’s assume you purchased your groceries ten times from each location and you were most often satisfied with the vegetables from the farmers market. At some point, you will make a conscious decision to purchase your greens exclusively from the said market.

On rare occasions when the market is closed you may be forced to try the store or the supermarket again and the outcome might make you change your mind. The best bandit agents are programmed to do the same thing and try the less-rewarding options again from time to time and reinforce the data they already have.
The bandit learns in real time and adjusts its parameters accordingly. Compared to A/B testing, multi-armed bandits allow you to gather advanced information based on an extended period of time rather than making a choice after only a brief period of testing.
Multi-Armed Bandit Builds & Solutions
There are infinite ways to build multi-armed bandit agents. Pure-exploration agents are completely random. They focus on exploration and never exploit any of the data they have gathered.
As the name suggests, pure-exploitation agents would always choose the best possible solution since they already have all the data to exploit. Being paradoxical by nature, this makes them possible in theory only and equally bad as the random agents.
Thus, we’ll focus on explaining the three most popular MAB agents that are neither completely random nor impossible to deploy in practice.
Epsilon-greedy
Epsilon-greedy multi-armed bandits take care of the balance between exploration and exploitation by adding the exploration value (epsilon) to the formula. In case epsilon equals 0.3, the agent will explore random possibilities 30% of the time and focus on exploiting the best average outcome the other 70% of time.
A decay parameter is also included and it reduces epsilon over time. When constructing the agent, you may decide to remove epsilon from the equation after a certain amount of time or actions taken. This will cause the agent to focus solely on exploitation of the data it already gathered and remove random tests from the equation.
Upper confidence bound
These multi-armed bandits are quite similar to the epsilon-greedy agents. However, the key difference between the two is an additional parameter included when building upper confidence bound bandits.
A variable is included in the equation that forces the bandit to focus on the least-explored possibilities from time to time. For example, if you have options A, B, C, and D, and option D has only been chosen ten times, while the rest have been selected hundreds of times, the bandit will purposefully select D to explore the outcomes.
In essence, upper confidence bound agents sacrifice some of the resources to avoid a huge yet quite improbable mistake of never exploring the best possible outcome.
Thompson Sampling (Bayesian)
This agent is built quite disparately from the two we explored above. Being by far the most advanced bandit solution on the list, an essay-length article would be required to explain how it works with sufficient detail. However, we can opt for a less intricate analysis instead.
The Thompson bandit is able to trust certain choices more or less based on how often they were picked in the past. For example, we have option A that the agent chose a hundred times with an average reward ratio of 0.71. We also have option B that was chosen a total of twenty times with the same average reward radio as option A.
In this case, the Thompson sampling agent would go for option A a bit more often. This is because a higher frequency of choosing a path tends to yield lower average rewards. The agent assumes option A is more trustworthy and option B would have lower average outcomes if it was chosen more frequently.
Multi-Armed Bandit Applications in Real Life
Perhaps the most popular example we can mention here is Google Analytics. As part of their official documentation they explained how they used multi-armed bandits to explore the viability of different search results and how often these should be displayed to various visitors.
In 2018, Netflix held a presentation at Data Council talking about how they applied multi-armed bandits to determine which of their titles should be displayed more often to audiences. Marketers may find the demonstration quite interesting, as it explains how different factors such as how often titles were replayed or even paused by those watching affected multi-armed bandit solutions.
Perhaps the most important use of multi-armed bandits for humankind is related to healthcare. To this day, medical experts use various MAB builds to determine the optimal treatment for patients. Bandits also see various applications in clinical trials and the exploration of novel treatments.
Key Takeaways
Multi-armed bandits have been applied successfully in multiple fields of work, including marketing, finance, and even health. However, much like reinforcement learning itself, they are severely limited by changing environments. If the circumstances tend to vary, MABS have to start “learning” all over again every time and become a less useful tool.
Alex Popovic is an engineering manager and a writer with a decade of experience as a team leader in tech and finance. He now spends time running his own consultancy agency while simultaneously exploring topics that he has grown to love, such as data science, AI, and high fantasy. You can reach Alex at hello@writeralex.com.