Dealing with Position Bias in Recommendations and Search
People click on top items in search and recommendations more often because they are on top, not because of their relevancy. How can this problem be solved?
People click on top items in search and recommendations more often because they are on top, not because of their relevancy. If you order your search results with an ML model, they may eventually degrade in quality because of such a positive self-reinforcing feedback loop. How can this problem be solved?
Biases in Ranking
Every time you present a list of things, such as search results or recommendations, to a human being, rarely can we fairly evaluate all the items in the list.
Item rankings are all around us.
A cascade click model assumes that people evaluate all the items in the list sequentially before they find the relevant one. But then it means that things on the bottom have a smaller chance to be evaluated at all, hence will organically have fewer clicks:
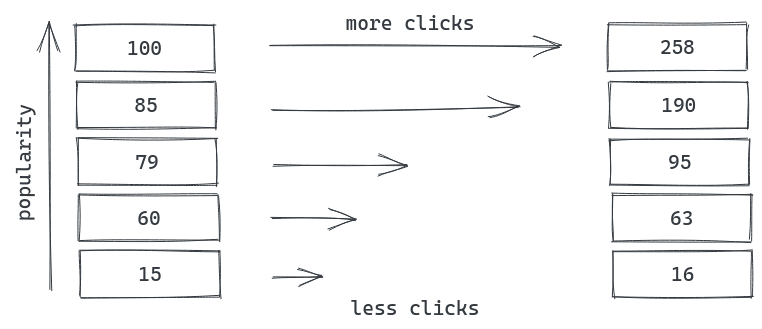
Higher in the list?—?more clicks.
Top items receive more clicks only because of their position?—?this behavior is called position bias. However, the position bias is not the only bias in item lists, there are plenty of other dangerous things to watch out for:
- Presentation bias: for example, due to a 3x3 grid layout, an item on position #4 (right under the #1 top one) may receive more clicks than item #3 in the corner.
- Model bias: when you train an ML model on historical data generated by the same model.
In practice, the position bias is the strongest one?—?and removing it while training may improve your model reliability.
Experiment: Measuring Position Bias
We conducted a small crowd-sourced research about position bias. With a RankLens dataset, we used a Google Keyword Planner tool to generate a set of queries to find each particular movie.
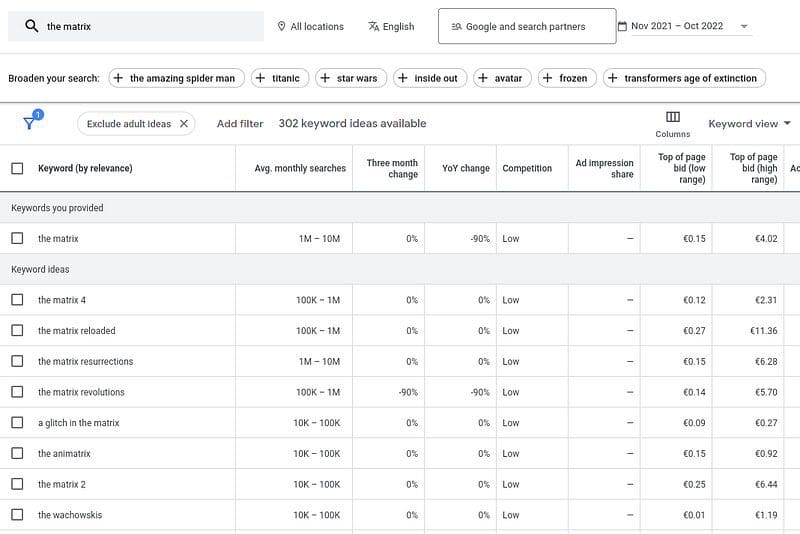
Abusing Google Keyword Planner to get real queries people use for finding movies.
With a set of movies and corresponding actual queries, we have a perfect search evaluation dataset?—?all items are well-known for a wider audience, and we know correct labels in advance.
All major crowd-sourcing platforms like Amazon Mechanical Turk, Scale.com and Toloka.ai have out-of-the-box templates for typical search evaluation:
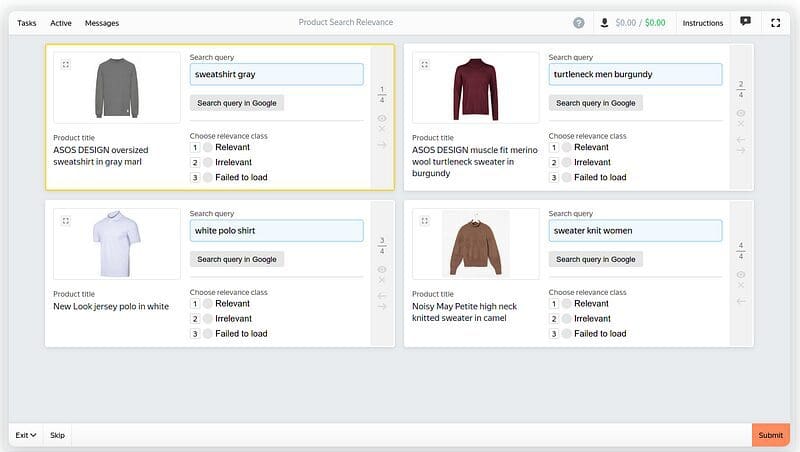
A typical search ranking evaluation template.
But there’s a nice trick in such templates, preventing you from shooting yourself in the foot with position bias: each item must be examined independently. Even if multiple items are present on screen, their ordering is random! But does random item order prevents people from clicking on the first results?
The raw data for the experiment is available on github.com/metarank/msrd, but the main observation is that people still click more on the first position, even on randomly-ranked items!
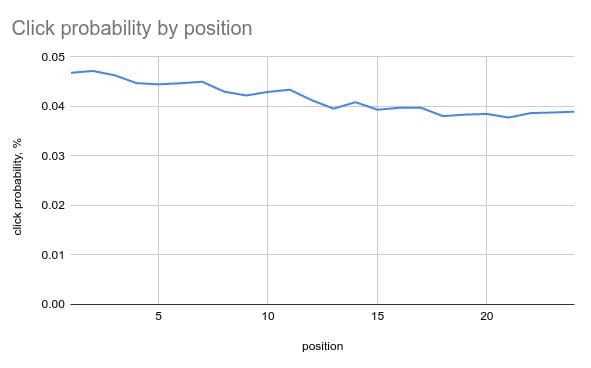
More clicks on first items, even for random ranking.
Inverse Propensity Weighting
But how can you offset the impact of position on implicit feedback you get from clicks? Each time you measure the click probability of an item, you observe the combination of two independent variables:
- Bias: the probability of clicking on a specific position in the list.
- Relevance: the importance of the item within the current context (like BM25 score coming from ElasticSearch, and cosine similarity in recommendations)
In the MSRD dataset mentioned in the previous paragraph, it’s hard to distinguish the impact of position independently from BM25 relevance as you only observe them combined together:
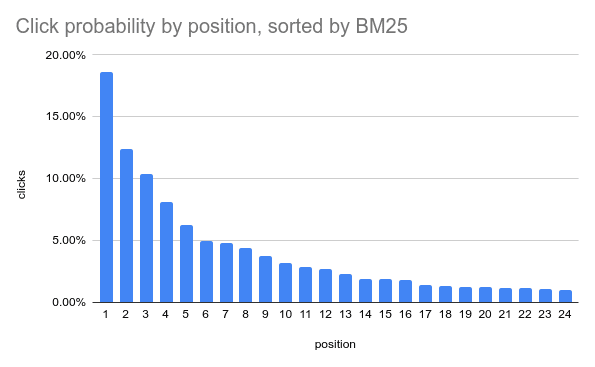
When sorted by BM25, people prefer relevant items.
For example, 18% of clicks are happening on position #1. Does this only happen because we have the most relevant item presented there? Will the same item on position #20 get the same amount of clicks?
The Inverse Propensity Weighting approach suggests that the observed click probability on a position is just a combination of two independent variables:
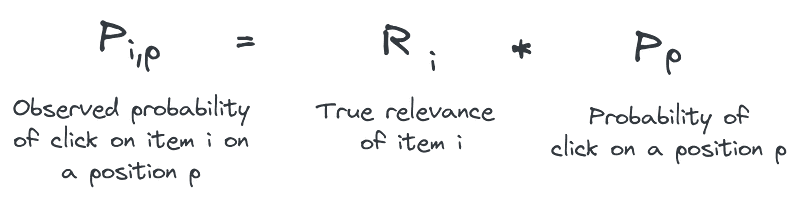
Is true relevance independent from position?
And then, if you estimate the click probability on each position (the propensity), you can weight all your relevance labels with it and get an actual unbiased relevance:
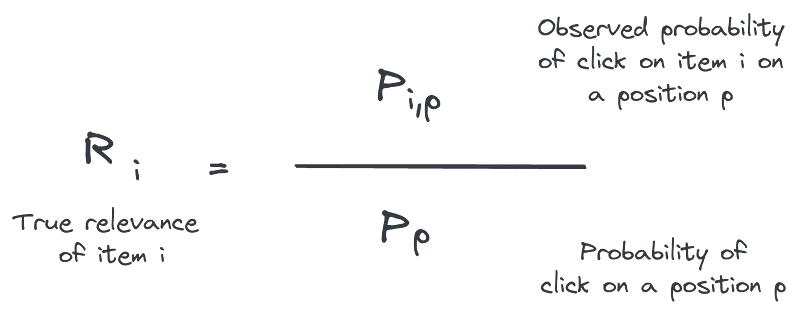
Weighting by propensity
But how can you estimate the propensity in practice? The most common method is introducing a minor shuffling to rankings so that the same items within the same context (e.g., for a search query) will be evaluated on different positions.

Estimating the propensity by shuffling.
But adding extra shuffling will definitely degrade your business metrics like CTR and Conversion Rate. Are there any less invasive alternatives not involving shuffling?

A slide from MICES’19 talk Personalizing Search results in real-time: a 2.8% drop in conversion when shuffling search results!
Position-Aware Learning
A position-aware approach to ranking suggests asking your ML model to optimize both ranking relevancy and position impact at the same time:
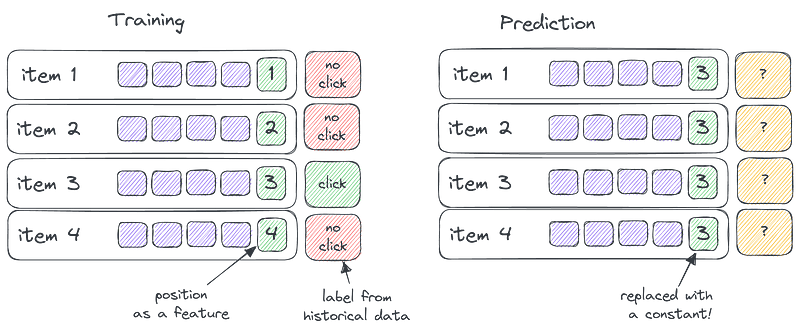
- on training time, you use item position as an input feature,
- In the prediction stage, you replace it with a constant value.

Replacing biased factors with constants during the inference
In other words, you trick your ranking ML model into detecting how position affects relevance during the training but zero out this feature during the prediction: all the items are simultaneously being presented in the same position.
v
But which constant value should you choose? The authors of the PAL paper did a couple of numerical experiments on selecting the optimal value?—?the rule of thumb is not to pick too high positions, as there’s too much noise.
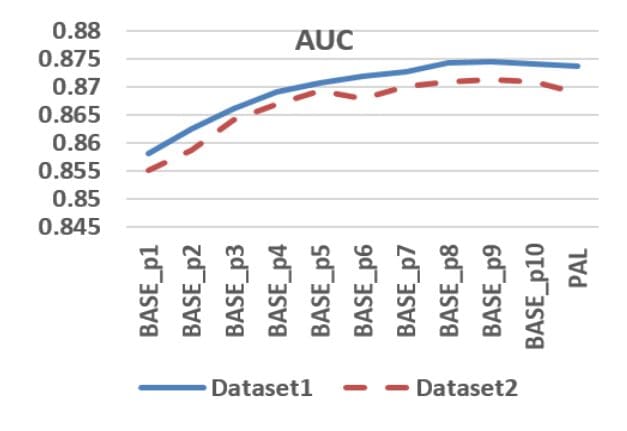
Authors of PAL tested different position constant values
Practical PAL
The PAL approach is already a part of multiple open-source tools for building recommendations and search:
- ToRecSys implements PAL as a bias-elimination approach to train recommender systems on biased data.
- Metarank can use a PAL-driven feature to train an unbiased LambdaMART Learn-to-Rank model.
As the position-aware approach is just a hack around feature engineering, in Metarank, it is only a matter of adding yet another feature definition:
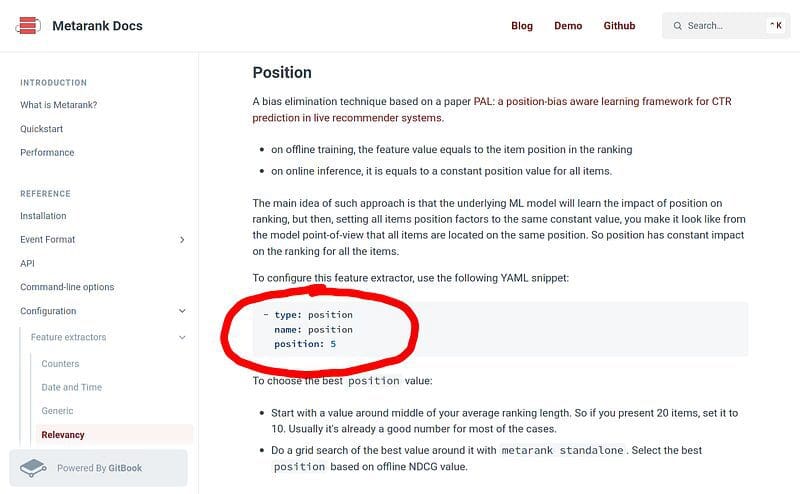
Adding position as a ranking feature for a Learn-to-Rank model
On an MSRD dataset mentioned above, such a PAL-inspired ranking feature has quite a high SHAP importance value compared to other ranking features:
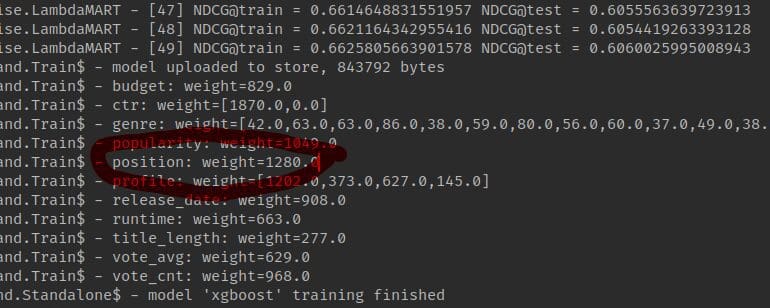
Importance of the position while training the LambdaMART model
Last Words
The position-aware learning approach is not only limited to pure ranking tasks and position de-biasing: you can use this trick to overcome any other type of bias:
- For the presentation bias due to a grid layout, you can introduce a pair of features for an item’s row and column position during the training. But swap them to a constant during the prediction.
- For the model bias, when items presented more often receive more clicks?—?you can introduce a “number of clicks” training feature and replace it with a constant value on prediction time.
The ML model trained with the PAL approach should produce an unbiased prediction.
Roman Grebennikov is a Principal Engineer at Delivery Hero SE, working on search personalization and recommendations. A pragmatic fan of functional programming, learn-to-rank models and performance engineering.