
| ||||||||||||||||||||
Comments
For comparison, here are the results of 2007 KDnuggets Poll: Largest Data Size Data-Mined.
The median DB size in this poll was around 10 GB, smaller than 30-60 GB range in 2007 poll. One explanation is that fewer people participated in 2008 poll (perhaps Yahoo data miners who mine some of the largest data anywhere were distracted by the Microsoft takeover bid and did not take part in this poll).
The following chart shows the breakdown of the largest DB size (estimated median value) by region. The values in US/CA/Au, W. Europe, and Asia regions are close to what we expected. We note the unusually large DB size reported two regions: Latin America, and Africa and Middle East, but these are probably not representative for these regions because of the small number of responses.
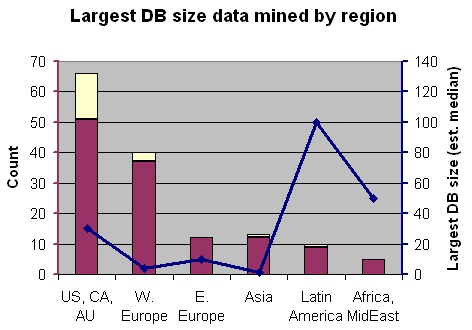
Largest DB size by region. Yellow bar shows responses over 1 TB
| Region | Count | Largest DB Size (est. median value) | Pct with largest DB size > 1 TB |
|---|---|---|---|
| US, Canada, Australia/Pacific | 51 | 30 GB | 29% |
| W. Europe | 37 | 4 GB | 8.1% |
| E. Europe | 12 | 10 GB | 0 |
| Asia | 12 | 1 GB | 8.3% |
| Latin America | 9 | 100 GB | 11.1% |
| Africa, Middle East | 5 | 50 GB | 0 |
TimManns, Size of data in bytes or rows?
I am usually fairly ignorant of the size in bytes of the data. I know how many rows and columns I process (and that the size of our entire Teradata data warehouse exceeds many terabytes).
I'd guess that most analysts can report rows and columns easier than bytes. Here's mine;
My largest queries access data from multiple tables, with -more than- 2 billion rows within the largest single table (and I create approx 30 byteint columns from that table). This transactional level data is summarised to single row per customer, therefore the end result set is much smaller.
To be practical, processing time for any analyis can never exceed a few hours.
Rafal Latkowski, What was the largest dataset?
I'm assumming that we are talking about size without compression. Some database/datamining suites have very efficient compression especially for de-normalized data (in range about 1:5-1:20), but all algorithms are processing uncompressed data.