New York Times, By PATRICIA COHEN, December 16, 2010
With little fanfare, Google has made a mammoth database culled from nearly 5.2 million digitized books available to the public for free downloads and online searches, opening a new landscape of possibilities for research and education in the humanities.
The digital storehouse, which comprises words and short phrases as well as a year-by-year count of how often they appear, represents the first time a data set of this magnitude and searching tools are at the disposal of Ph.D.'s, middle school students and anyone else who likes to spend time in front of a small screen. It consists of the 500 billion words contained in books published between 1500 and 2008 in English, French, Spanish, German, Chinese and Russian.
The intended audience is scholarly, but a simple online tool (ngrams.googlelabs.com/) allows anyone with a computer to plug in a string of up to five words and see a graph that charts the phrase's use over time - a diversion that can quickly become as addictive as the habit-forming game Angry Birds.
With a click you can see that "women," in comparison with "men," is rarely mentioned until the early 1970s, when feminism gained a foothold. The lines eventually cross paths about 1986.
Read more.
Gregory Piatetsky-Shapiro:
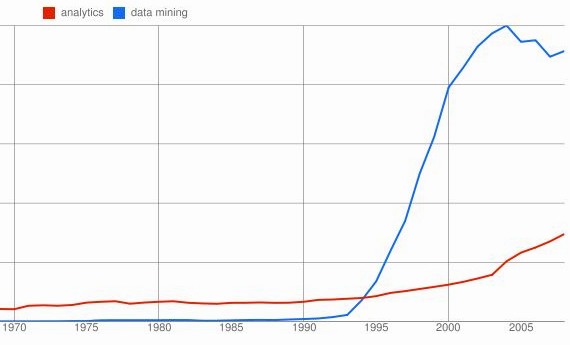
Here is a comparison of data mining vs analytics, from 1970 to 2008. We see that analytics was rarely, but steadily used (actually deeper analysis surprisingly shows that "analytics" was used at the same frequency since 1900). The use of data mining shot up around 1992 (soon after the first book and first 2 workshops on Knowledge Discovery and Data Mining) and started to decline around 2003, perhaps after a backlash against Pentagon Total Information Awareneess program, which created a perception of data mining as a tool for an invasion of privacy. Analytics starts to shoot up in around 2003, same time that data mining popularity begins to decline.