
Roberto Zicari, ODBMS Industry Watch, Nov 16, 2011
 I wanted to know more about Vertica Analytics Platform for Big Data. I have interviewed Shilpa Lawande, VP of Engineering at Vertica.
Vertica
was acquired by HP early this year. RVZ
I wanted to know more about Vertica Analytics Platform for Big Data. I have interviewed Shilpa Lawande, VP of Engineering at Vertica.
Vertica
was acquired by HP early this year. RVZ
Q1. What are the main technical challenges for big data analytics?
 Shilpa Lawande:
Big data problems have several characteristics that make them technically challenging. First is the volume of data, especially machine-generated data, and how fast that data is growing every year, with new sources of data that are emerging. It is expected there will be 6 billion mobile phones by the end of 2011, and there are currently over 300 Twitter accounts and 500K Facebook status updates created every minute. And, there is now a $2 billion a year market for virtual goods!
Shilpa Lawande:
Big data problems have several characteristics that make them technically challenging. First is the volume of data, especially machine-generated data, and how fast that data is growing every year, with new sources of data that are emerging. It is expected there will be 6 billion mobile phones by the end of 2011, and there are currently over 300 Twitter accounts and 500K Facebook status updates created every minute. And, there is now a $2 billion a year market for virtual goods!
A lot of insights are contained in unstructured or semi-structured data from these types of applications, and the problem is analyzing this data at scale. Equally challenging is the problem of 'how to analyze.' It can take significant exploration to find the right model for analysis, and the ability to iterate very quickly and "fail fast" through many (possible throwaway) models - at scale - is critical.
Second, as businesses get more value out of analytics, it creates a success problem - they want the data available faster, or in other words, want real-time analytics. And they want more people to have access to it, or in other words, high user volumes.
One of Vertica's early customers is a Telco that started using Vertica as a 'data mart' because they couldn't get resources from their enterprise data warehouse. Today, they have over a petabyte of data in Vertica, several orders of magnitude bigger than their enterprise data warehouse.
Techniques like social graph analysis, for instance leveraging the influencers in a social network to create better user experience are hard problems to solve at scale. All of these problems combined create a perfect storm of challenges and opportunities to create faster, cheaper and better solutions for big data analytics than traditional approaches can solve.
Q2. How Vertica helps solving such challenges?
Shilpa Lawande: Vertica was designed from the ground up for analytics. We did not try to retrofit 30-year old RDBMS technology to build the Vertica Analytics Platform. Instead, Vertica built a true columnar database engine including sorted columnar storage, a query optimizer and an execution engine.
With sorted columnar storage, there are two methods that drastically reduce the I/O bandwidth requirements for such big data analytics workloads. The first is that Vertica only reads the columns that queries need.
Second, Vertica compresses the data significantly better than anyone else.
Vertica's execution engine is optimized for modern multi-core processors and we ensure that data stays compressed as much as possible through the query execution, thereby reducing the CPU cycles to process the query. Additionally, we have a scale-out MPP architecture, which means you can add more nodes to Vertica.
...
Q6. Vertica vs. Apache Hadoop: what are the similarities and what are the differences?
Shilpa Lawande: Vertica and Hadoop are both systems that can store and analyze large amounts of data on commodity hardware. The main differences are how the data gets in and out, how fast the system can perform, and what transaction guarantees are provided. Also, from the standpoint of data access, Vertica's interface is SQL and data must be designed and loaded into a SQL schema for analysis.
With Hadoop, data is loaded AS IS into a distributed file system and accessed programmatically by writing Map-Reduce programs. By not requiring a schema first, Hadoop provides a great tool for exploratory analysis of the data, as long as you have the software development expertise to write Map Reduce programs. Hadoop assumes that the workload it runs will be long running, so it makes heavy use of checkpointing at intermediate stages.
This means parts of a job can fail, be restarted and eventually complete successfully. There are no transactional guarantees.
Vertica, on the other hand, is optimized for performance by careful layout of data and pipelined operations that minimize saving intermediate state. Vertica gets queries to run sub-second and if a query fails, you just run it again. Vertica provides standard ACID transaction semantics on loads and queries.
We recently did a comparison between Hadoop, Pig, and Vertica for a graph problem (see
post on our blog)
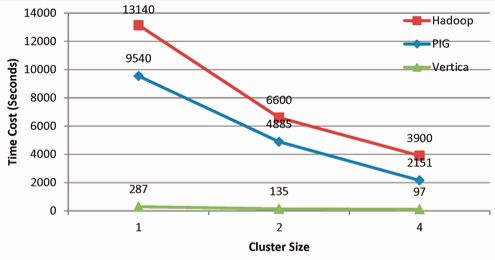
and when it comes to performance, the choice is clearly in favor of Vertica. But we believe in using the right tool for the job and have over 30 customers using both the systems together. Hadoop is a great tool for the early exploration phase, where you need to determine what value there is in the data, what the best schema is, or to transform the source data before loading into Vertica. Once the data models have been identified, use Vertica to get fast responses to queries over the data.
Read more.