
Kaggle.com, by Chris Raimondi on August 9, 2010
Initial Strategy
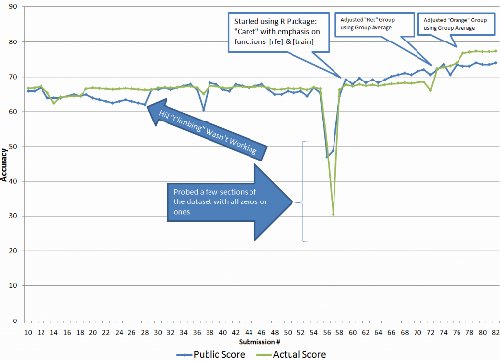
The graph shows both my public and private scores (which were obtained after the contest). As you can see from the graph, my initial attempts were not very successful. The training data contained 206 responders and 794 non- responders. The test data was known to contain 346 of each. I tried two separate to segmenting my training dataset:
1. To make my training set closely match the overall population (32.6 % Responders) in order to accurately reflect the entire dataset.
2. To make my training set closely match the test data in order to have a population similar to the test set.
I identified certain areas of the dataset that didn't appear to be randomly partitioned. In order to do machine learning correctly, it is important to have your training data closely match the test dataset. I identified five separate groups in the data which I began to treat separately.
Originally I set up a different model for each group, but that became a pain and I found better results by simply estimating the overall group response and adjusting the predictions in each group to match the predicted group mean response.
Read more.