
Daniel M. Rice
Rice Analytics, St. Louis, MO (USA), www.riceanalytics.com
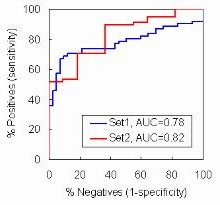 The area under the curve (AUC) that relates the hit rate to the false alarm rate has
become a standard measure in tests of predictive modeling accuracy. The AUC is an
estimate of the probability that a classifier will rank a randomly chosen positive instance
higher than a randomly chosen negative instance. For this reason, the AUC is widely
thought to be a better measure than a classification error rate based upon a single prior
probability or KS statistic threshold.
The area under the curve (AUC) that relates the hit rate to the false alarm rate has
become a standard measure in tests of predictive modeling accuracy. The AUC is an
estimate of the probability that a classifier will rank a randomly chosen positive instance
higher than a randomly chosen negative instance. For this reason, the AUC is widely
thought to be a better measure than a classification error rate based upon a single prior
probability or KS statistic threshold.
When tested in a real world application, many models will still use a single threshold based upon the KS statistic or a prior probability rather than the range of thresholds in the AUC calculation. Hence, the AUC may not reflect the expected classification accuracy at this single threshold when these models are put to real world use. Another external validity problem is that the AUC will not assess the extent to which the model output is well calibrated to the target variable, as the AUC does not estimate the accuracy of the probabilities in the model output. In contrast, average squared error will directly reflect the error of the output probabilities. Indeed, there is a long and successful track record of average squared error to assess probability accuracy in areas of science such as weather forecasting back to Brier (1950). In many applications today, even a 1% reduction in classification error or average squared error would mean tens of millions of dollars or more of ROI. Yet, the AUC may miss these effects because of this lack of external validity.
What may be most troubling is that more published simulation data now show AUC estimates of error are less accurate than straight classification error estimates. The earliest simulations were the Huang and Ling (2005) work based upon up to 20 observations. Huang and Ling did report that AUC had better accuracy than classification rate. However, more recent simulations with much more data come to the opposite conclusion. Hanczar et al. (2010) report simulations at various sample sizes up to 1000 observations. They find that straight classification error is a better measure of actual error because the AUC predicted error can have much greater dispersion and is therefore less precise. These AUC inaccuracies were most apparent in imbalanced samples and smaller samples. Based upon these data, Hanczar et al. (2010) urge caution in the use of AUC measures unless the sample size is very large. Unfortunately, they also point out that while "it would be nice to have a simple rule of thumb to determine if a sample is sufficiently large ... no simple solution is possible" (p. 829).
What does this mean for the everyday practitioner? A more comprehensive study now suggests that the AUC may be noisier than previously thought (Hanczar et al. 2010). Other studies are needed, but this recent evidence does not support the superiority of the AUC as a measure of accuracy. Clearly, another problem is that a valid confidence interval for the AUC is not so simple to compute, so a valid repeated measures statistical test for AUC differences between two models built from the same data also would not be simple. In any event, given the apparently greater noise in the AUC, any practice of simply "eyeballing" AUC results might be equivalent to flipping a coin to determine the reliability of differences between models. In contrast to the AUC, well established and simple repeated measures statistical tests can be used to assess straight classification error rate differences or average squared error differences (see Rice 2008, as an example). Thus, instead of picking a model winner in what could be a random AUC lottery, apparently more accurate measures - straight classification error rate and average squared error - with much better statistical and external validity should probably now be considered.
Read more.