
The recently released Million Song Dataset (MSD), a collaborative project between The Echo Nest and Columbia's LabROSA is a fantastic resource for music researchers. It contains detailed acoustic and contextual data for a million songs. However, getting started with the dataset can be a bit daunting. First of all, the dataset is huge (around 300 gb) which is more than most people want to download. Second, it is such a big dataset that processing it in a traditional fashion, one track at a time, is going to take a long time. Even if you can process a track in 100 milliseconds, it is still going to take over a day to process all of the tracks in the dataset. Luckily there are some techniques such as Map/Reduce that make processing big data scalable over multiple CPUs. In this post I shall describe how we can use Amazon's Elastic Map Reduce to easily process the million song dataset.
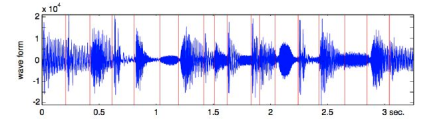
For this first experiment in processing the million song data set I want to do something fairly simple and yet still interesting. One easy calculation is to determine each song's density - where the density is defined as the average number of notes or atomic sounds (called segments) per second in a song. To calculate the density we just divide the number of segments in a song by the song's duration. The set of segments for a track is already calculated in the MSD. An onset detector is used to identify atomic units of sound such as individual notes, chords, drum sounds, etc. Each segment represents a rich and complex and usually short polyphonic sound. In the above graph the audio signal (in blue) is divided into about 18 segments (marked by the red lines). The resulting segments vary in duration. We should expect that high density songs will have lots of activity (as an Emperor once said "too many notes"), while low density songs won't have very much going on. For this experiment I'll calculate the density of all 1 million songs and find the most dense and the least dense songs.
Read more.