Ethics in Machine Learning – Summary
Still worried about the AI apocalypse? Here we are discussion about the constraints and ethics for the machine learning algorithms to prevent it.
By Courtney Burton, MLconf
Thanks Akash! That’s what we were aiming for! For the first time, In Seattle, on May 20th, we decided to host a series of talks on the subject of Ethics in Machine Learning. As we mentioned in a KD Nuggets post last month, we’ve recently asked ourselves this: Can AI really ever be safe if it learns from us? Following our Quora question: “What constraints to AI and machine learning algorithms are needed to prevent AI from becoming a dystopian threat to humanity?“ The winner of the contest, Igor Markov, went on to present his answer and plan at MLconf Seattle on 05/20.
Markov quoted Baidu Research’s Andrew Ng, when he said “Worrying about AI today is like worrying about overpopulation on Mars.” Markov went on to explore several science fiction films, and how the machines rose to power, societal fears around this happening in reality, and then reminded us of how humanity survived in past eras and how we can use this knowledge in a time of “the rise of the machines”. In his plan, Markov suggested that when designing an AI system, you want to introduce and keep boundaries between different levels of intelligence & trust. His key points were that:
- Agents should have key weaknesses
- Self-replication of software & hardware should be limited
- Self-repair and self-improvement should be limited
- Access to energy should be limited
The slide below points to the constraints on AI to intercept dystopian threats:

Markov’s full slide deck can be found on the MLconf slideshare account, here.
Following Markov, was Even Estola, Lead Machine Learning Engineer at Meetup. In a pre-event interview, Estola participated in the conversation about ethics in ML.. His response: “Because the easiest way to build machine learning skills is practicing on canned data sets, it’s easy to run into problems with real data. It turns out that wild data are messy, incomplete, and sometimes even racist, sexist, and immoral. We need to acknowledge that the real world can be garbage at times, and consequently we should be building systems that combat this, instead of succumbing to it. It won’t be easy, and it will likely cost us some points on our traditional performance metrics, but machine learning as we know it can really only infer the status quo, and we need to be better than that. We all know racist computers are a bad idea. Don’t let your company build racist computers.” In his talk, Estola urged us to spread awareness about the issue and urged to use solutions such as using simple solutions, even if they have a small concession in performance. He also suggested using ensemble modeling and designing test data sets for capturing unintended bias.
Estola’s full slide deck can be found on the MLconf Slideshare account, here.
Following Estola was Florian Tramèr, who presented an example of unfair associations & consequences in data-driven applications and how such errors have the ability to offend the masses. Tramèr went on to explain preventative measures, but also their limitations. His solution? FairTest, which finds context specific associations between protected variables and application outputs. FairTest can be used to understand and evaluate potential association bugs.
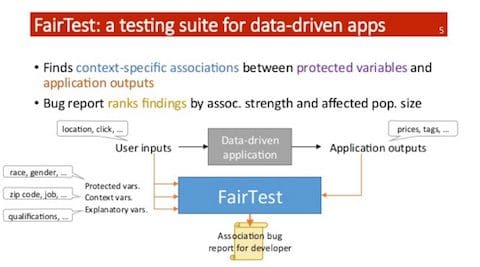
*Slide 5/10, Tramer’s slides on MLconf Slideshare account.
The conversation of ethics in machine learning is far from over. We’re hoping that by providing a platform for these ideas to be expressed, we can keep the momentum going on thwarting off any potential threat to society from the machines we build. Thankfully, the community does not deal with this potential problem on a conceptual and philosophical level. There is an increase in research activity seeking solutions to these potential threats. We aim to shed light on this work, as we see the value.
There were 12 other talented speakers at MLconf Seattle, who should not go unacknowledged, who presented on a variety of topics such as the future of ML, NLP, Probabilistic Programming, Multi-Algorithm Ensembles, Neuroscience as it relates to Deep Learning, Recommender Systems, and more! We’ll be covering these and additional topics in machine learning in our series of events this fall. Mention “Ethics18” and save 18% on any of our upcoming events this fall!
Related: