Top New Features in Orange 3 Data Mining Platform
The main technical advantage of Orange 3 is its integration with NumPy and SciPy libraries. Other improvements include reading online data, working through queries for SQL and pre-processing.
By Ajda Pretnar
With 18 years of age, Orange data mining software has gone through a lot of changes. One of the major ones is a recent transition to Python 3, obliterating the C++ components and instead using core Python libraries such as NumPy, SciPy and scikit-learn. Orange 3 has thus become the official distribution, with improved visualizations and additional functionalities.
Orange data mining software has gone through a lot of changes. One of the major ones is a recent transition to Python 3, obliterating the C++ components and instead using core Python libraries such as NumPy, SciPy and scikit-learn. Orange 3 has thus become the official distribution, with improved visualizations and additional functionalities.
 1. Orange reads Google Sheets. A great new feature in Orange is a chance to work with online data through URLs. With the increasing use of cloud services such as Google Drive, Orange can now work with Google Sheets. This is super efficient for sharing data sets and comparing results without having to send files through email or having to download them to your device.
1. Orange reads Google Sheets. A great new feature in Orange is a chance to work with online data through URLs. With the increasing use of cloud services such as Google Drive, Orange can now work with Google Sheets. This is super efficient for sharing data sets and comparing results without having to send files through email or having to download them to your device.
2. SQL data can stay on the database server. Widgets, the computational units of Orange, no longer (necessarily) pass the data to each other: now they can also work on queries. The first widget establishes the connection with the database and sets up an initial query: a table, view or any manually constructed query. Instead of getting the data from the database, downstream widgets modify this query and retrieve the data only when and if necessary. Plotting a boxplot or constructing a naive Bayesian classifier at the end of a workflow would thus only retrieve the distributions. Similarly, discretization will use only a small subset of the data to find the appropriate thresholds and then add the binning operators to the query, never retrieving actual data rows from the server. Displaying the data in a table only retrieves the rows that are actually shown… Most of these operations work smoothly even on data tables of terabyte size.
from the database, downstream widgets modify this query and retrieve the data only when and if necessary. Plotting a boxplot or constructing a naive Bayesian classifier at the end of a workflow would thus only retrieve the distributions. Similarly, discretization will use only a small subset of the data to find the appropriate thresholds and then add the binning operators to the query, never retrieving actual data rows from the server. Displaying the data in a table only retrieves the rows that are actually shown… Most of these operations work smoothly even on data tables of terabyte size.
 3. Color Your Data. We have considered small changes that would simplify the use of Orange and we have tried to remove small annoyances. One was setting the color palettes: if one decides to color the men blue and the women pink in one widget, why does she have to do the same in all widgets? Orange now has a widget for assigning colors to values for the entire schema. It’s just a small thing, nothing to brag about - but there are many such small details we are taking care of lately.
3. Color Your Data. We have considered small changes that would simplify the use of Orange and we have tried to remove small annoyances. One was setting the color palettes: if one decides to color the men blue and the women pink in one widget, why does she have to do the same in all widgets? Orange now has a widget for assigning colors to values for the entire schema. It’s just a small thing, nothing to brag about - but there are many such small details we are taking care of lately.
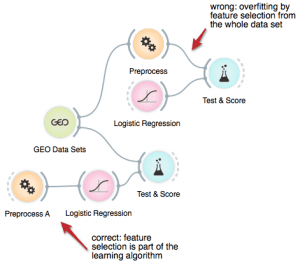
4. Improved data pre-processing. Say you have a classification data set with huge number of features. We can use feature subset selection and then test SVM or logistic regression through cross-validation. Right? Wrong (of course)! Pre-processing should be a part of the learner. Learners in Orange now accept pre-processors, including feature subset selectors on the input, but it’s still educational to observe how easy it is to overfit through the wrong use of pre-processing.

With 18 years of age,
 1. Orange reads Google Sheets. A great new feature in Orange is a chance to work with online data through URLs. With the increasing use of cloud services such as Google Drive, Orange can now work with Google Sheets. This is super efficient for sharing data sets and comparing results without having to send files through email or having to download them to your device.
1. Orange reads Google Sheets. A great new feature in Orange is a chance to work with online data through URLs. With the increasing use of cloud services such as Google Drive, Orange can now work with Google Sheets. This is super efficient for sharing data sets and comparing results without having to send files through email or having to download them to your device.
2. SQL data can stay on the database server. Widgets, the computational units of Orange, no longer (necessarily) pass the data to each other: now they can also work on queries. The first widget establishes the connection with the database and sets up an initial query: a table, view or any manually constructed query. Instead of getting the data
 from the database, downstream widgets modify this query and retrieve the data only when and if necessary. Plotting a boxplot or constructing a naive Bayesian classifier at the end of a workflow would thus only retrieve the distributions. Similarly, discretization will use only a small subset of the data to find the appropriate thresholds and then add the binning operators to the query, never retrieving actual data rows from the server. Displaying the data in a table only retrieves the rows that are actually shown… Most of these operations work smoothly even on data tables of terabyte size.
from the database, downstream widgets modify this query and retrieve the data only when and if necessary. Plotting a boxplot or constructing a naive Bayesian classifier at the end of a workflow would thus only retrieve the distributions. Similarly, discretization will use only a small subset of the data to find the appropriate thresholds and then add the binning operators to the query, never retrieving actual data rows from the server. Displaying the data in a table only retrieves the rows that are actually shown… Most of these operations work smoothly even on data tables of terabyte size.
 3. Color Your Data. We have considered small changes that would simplify the use of Orange and we have tried to remove small annoyances. One was setting the color palettes: if one decides to color the men blue and the women pink in one widget, why does she have to do the same in all widgets? Orange now has a widget for assigning colors to values for the entire schema. It’s just a small thing, nothing to brag about - but there are many such small details we are taking care of lately.
3. Color Your Data. We have considered small changes that would simplify the use of Orange and we have tried to remove small annoyances. One was setting the color palettes: if one decides to color the men blue and the women pink in one widget, why does she have to do the same in all widgets? Orange now has a widget for assigning colors to values for the entire schema. It’s just a small thing, nothing to brag about - but there are many such small details we are taking care of lately.
4. Improved data pre-processing. Say you have a classification data set with huge number of features. We can use feature subset selection and then test SVM or logistic regression through cross-validation. Right? Wrong (of course)! Pre-processing should be a part of the learner. Learners in Orange now accept pre-processors, including feature subset selectors on the input, but it’s still educational to observe how easy it is to overfit through the wrong use of pre-processing.