Going deeper with recurrent networks: Sequence to Bag of Words Model
Deep learning makes it possible to convert unstructured text to computable formats, incorporating semantic knowledge to train machine learning models. These digital data troves help us understand people on a new level.
By Solomon Fung, MarianaIQ.
Until the last 5 years or so, it was infeasible to uncover topics and emotions across the web without powerful computing resources. Engineers didn’t have efficient methods to make sense of words and documents at a large scale. Now, with deep learning, we can convert unstructured text to computable formats, effectively incorporating semantic knowledge for training machine learning models. Harnessing the vast data troves of the digital world can help us understand people more directly, going beyond the limitations of collecting data points through measurements and survey results. Here’s a glimpse into how we achieve this at MarianaIQ.
Going deeper with recurrent networks
Recurrent neural network (RNN) is a network containing neural layers that have a temporal feedback loop. A neuron in this layer receives the current inputs as well as its own outputs from the previous time-step. An RNN can operate across a sequence of inputs since the recurrent layer “remembers” previous inputs while processing the current input. When an RNN network is computed, the software will “unroll” the network (as shown below) by rapidly cloning the RNN across all the time-steps and computing the signals for the forward pass. During the backwards pass, the loss is back-propagated through time (BPTT) like a feed-forward network, except the parameters’ adjustments across the clones are shared.
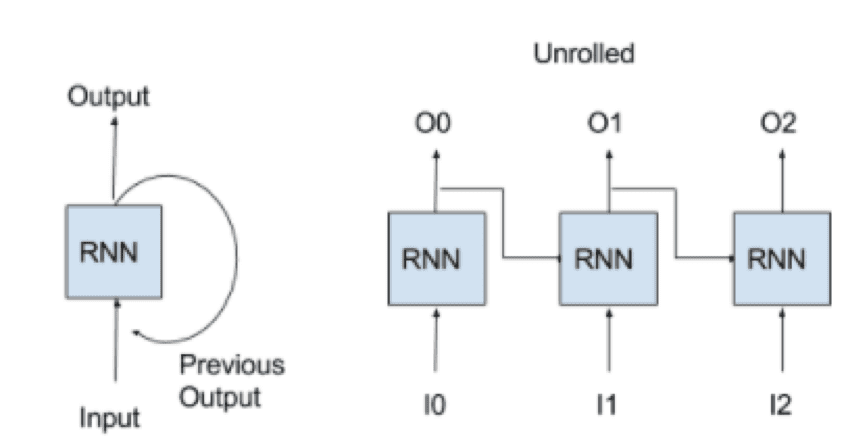
Fig 1. Recurrent Network Architecture
We use a sophisticated RNN called Long Short-Term Memory (LSTM)7, whose neurons include gated activations that act like inner switches for advanced memory capabilities. Another distinction for LSTMs is passing along a “hidden state” of activations to the next time-step, separate from its outputs.
With a dataset of product reviews, we could feed an RNN word-by-word and predict the rating with a softmax layer after receiving the final word. Another RNN application is a language model, where each input predicts the next input. Well-trained RNNs have generated text to mimic the style of Shakespeare’s plays, Obama’s speeches, lines of computer code or even composing music.

Fig 2.Training an RNN to generate Shakespeare with word-by-word prediction
Using dual RNNs to encode one language and decode to another language, we can train powerful and elegant sequence-to-sequence translation models (“seq2seq” learning)8. Much of Google Translate intelligence now relies on this technology. These RNNs work with one-hot input vectors or untrained/pre-trained embeddings, representing text either at a character level or word level.
Solving titles: Our Seq2BoW model
We can combine RNNs with Word2vec to map job titles to interests using a model we’ll call “Seq2BoW” (sequence to bag of words). The RNN learns to compose the embedding for any title from its word sequence, giving us two advantages:
- First, we no longer require a vocabulary list to exhaustively capture so many combinations of similar titles.
- Second, the titles and interests exist in the same embedding space so we can query across the two vocabularies to see how they relate in meaning. Not only can we assess how similar titles are, we can find out why by contrasting their inferred interests.
The training set consists of job descriptions containing titles and extracted keywords. We use a new embedding layer for the title words (tokens) and feed these through an LSTM to compute a fixed title embedding. This new title embedding is trained to predict the interests occurring in the same description.
To do this, we use a linear layer to project the new title embedding onto the vector space for interests (pre-trained on our own corpus using Word2vec). A linear layer is a neural layer without a nonlinear activation, so it is merely a linear transformation from the LSTM output to the existing interest vector space. We train the word predictions like Word2vec with positive and negative embeddings according to the keywords that appear in the job description for the associated title.
For speedup, we combined the dot products between the RNN projection and positive word and negative words together into the same training sample using a softmax layer for predicting only the positive word instead of training separate embedding pairs like in Word2vec.
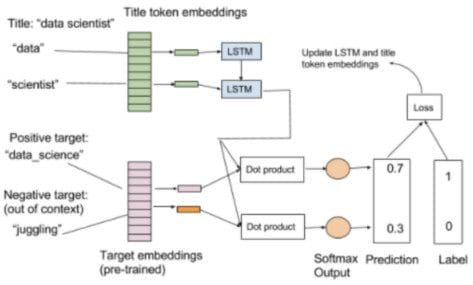
Fig 3. Training a title RNN (one positive and one negative sample)
We use Keras on the Tensorflow backend. Running on an NVIDIA GPU gave us the computation power to blaze through 10 million job descriptions in 15 minutes (32 wide RNN and 24 wide pre-trained interest word vectors). We can demonstrate the representational abilities of these vectors with a few examples below (all lists are computer “generated”).
Using our interest vocabulary trained with Word2vec, we can enter any interest keyword, look up its vector and find all the words belonging to the closest vectors:
Marketing Content: Content generation, Corporate blogging, Content syndication, Bylined articles, Social media strategy, Online content creation, Content curation, Content production
Juggling: Roller skating, Ventriloquism, Circus arts, Unicycle, Street dance, Swing dance, Comedic timing, Acrobatics
Brain Surgery: Medical research, Neurocritical care, Skull base surgery, Endocrine surgery, Brain tumors, Medical education, Pediatric cardiology, Hepatobiliary surgery
With the Seq2BoW title model, we can find related interests, given any title:
Marketing Analytics: Marketing mix modeling, Adobe insight, Lifetime value, Attribution modeling, Customer analysis, Spss clementine, Data segmentation, Spss modeler
Data Engineer: Spark, Apache Pig, Hive, Pandas, Map Reduce, Apache Spark, Octave, Vertica
Winemaker: Viticulture, Winemaking, Wineries, Red wine, Wine tasting, Food pairing, Champagne, Beer
We can create a separate title vocabulary by computing and storing the vectors for the most frequent titles. Then, we can query among these vectors to find related titles:
CEO: Chairman, General Partner, Chief Executive, Coo, President, Founder/Ceo, President/Ceo, Board Member
Dishwasher: Crew Member, Crew, Kitchen Staff, Busser, Barback, Shift Leader, Carhop, Sandwich Artist
Code Monkey: Senior Software Development Engineer, Lead Software Developer, Senior Software Engineer II, Software Designer, Software Engineer III, Lead Software Engineer, Technical Principal, Lead Software Development Engineer
We can also find titles near any interest:
Cold Calling: Account management, Sales presentations, Direct sales, Sales process, Sales operations, Outside sales, Sales, Sales management
Baking: Chef Instructor, Culinary Arts Instructor, Culinary Instructor, Baker, Head Baker, Pastry Chef, Pastry, Assistant Pastry Chef
Neural Networks: Senior Data Scientist, Principal Data Scientist, Machine Learning, Data Scientist, Algorithm Engineer, Quantitative Researcher, Research Programmer, Lead Scientist
We can extend beyond relating interests and titles and add various inputs or outputs to the Seq2BoW model. For example, we could consider company information, educational background, geographic location or other individual social and consumer insights and harness the flexibility of deep learning to understand how these relate.
Understanding text powers ABM at scale
The ABM intelligence used by MarianaIQ relies on powerful and concise representations of identity. We use Deep Learning to compute semantic embeddings for keywords and titles. To train useful machine learning models, we feed in unique labeled vectors of individuals and accounts, each containing attributes concatenated with our embeddings – a heterogeneous but harmonious combination of structured and unstructured data.
By learning from data collected across the web, we avoid the narrower and biased perspective of traditional consultants. We can quickly and accurately provide quantitative assessments such as deciding who will be more responsive to particular topics or identifying who looks more like a potential buyer. These analyses are only feasible through today’s machine learning, but they’re the secret sauce that allows ABM to function at scale for our customers.
Bio: Solomon Fung has a variety of degrees to his name, a reflection of his diverse interests. A California resident since his master’s degree at Stanford, he originally hails from Canada. His current focus at MarianaIQ is big data – his algorithms are designed to help companies better understand and predict the behavior of individual consumers.
Related: