 Comparison of the Most Useful Text Processing APIs
Comparison of the Most Useful Text Processing APIs
 Comparison of the Most Useful Text Processing APIs
Comparison of the Most Useful Text Processing APIsThere is a need to compare different APIs to understand key pros and cons they have and when it is better to use one API instead of the other. Let us proceed with the comparison.

Nowadays, text processing is developing rapidly, and several big companies provide their products which help to deal successfully with diverse text processing tasks. In case you need to do some text processing there are 2 options available. The first one is to develop the entire system on your own from scratch. This way proves to be very time and resource consuming. On the other hand, you can use the already accessible solutions developed by well-known companies. This option is usually faster and simpler. No specific knowledge or experience in the natural language processing is required. It would suffice to understand the fundamentals of the text processing. At the same time, if you need something exclusive, it is better to implement own solution rather than to apply one of the above mentioned.
Anyway, APIs for text processing are very popular and useful. So, there is a need to compare different APIs to understand key pros and cons they have and when it is better to use one API instead of the other. Let us proceed with the comparison.
Working with text processing, the data analyst faces the following tasks:
- Keyphrase extraction;
- Sentiment analysis;
- Text analysis;
- Entity recognition;
- Translation;
- Language detection;
- Topic modeling.
There are several high-level APIs which may be used to perform these tasks. Among them:
- Amazon Comprehend;
- IBM Watson Natural Language Understanding;
- Microsoft Azure (Text analytics API);
- Google Cloud Natural Language;
- Microsoft Azure (Linguistic Analysis API) - beta;
- Google Translate API;
- IBM Watson Translator;
- Amazon Translate;
- Microsoft Azure Translator Text API.
We will describe the general aspects of each API and then compare their main features in the table.
Amazon Comprehend
Amazon Comprehend is an element of the Amazon Web Services infrastructure. It provides high-level API for such text-processing tasks as language detection, sentiment analysis, topic modeling, keyphrase extraction, and entity recognition.
In case of the language detection, the Amazon Comprehend is capable of analyzing the input and then returning the dominant language and the confidence score. At the moment the tool supports more than 100 languages for this task.
Keyphrase extraction increases the understanding of the text you analyze. Amazon Comprehend returns the list of all detected key phrases with the confidence scores for each of them.
Entity recognition is the process of splitting the text into entities: people, organizations, locations, dates, etc. Thus, for each entity, the Amazon Comprehend will define a group to which it belongs. Like in the previous tasks, the confidence scores are also returned.
Sentiment analysis in the Amazon Comprehend allows detecting the general mood of the text. It supports 4 different sentiments: positive, negative, neutral, and mixed. The confidence scores are returned for each sentiment separately.
The outcomes of the topic modeling in Amazon Comprehend may be presented in 2 variants. According to the first variant, it will show the topic group for each document, the main keyword for this topic group, and the confidence score. According to the second variant, the topic group for each document and the proportion of the main keyword in the document are shown. A negative feature here is that if you want to perform topic modeling, you should have all your documents stored in Amazon S3.
Free Tier program is available up to 12 months. Here you pay just for those things you are using and only in the amounts required. Thus, Amazon Comprehend provides great flexibility in pricing. One of the downsides of this platform is that it supports only English and Spanish languages.
Nevertheless, you can use Amazon Translate (one more cloud service by the AWS) to translate from the source language into English or Spanish and then analyze the text using Amazon Comprehend.
IBM Watson Natural Language Understanding
IBM Watson is the platform which provides Artificial Intelligence related services for business. Natural Language Understanding is a part of this infrastructure. It allows solving a wide variety of tasks in text processing such as entity recognition, sentiment analysis, keyphrase extraction, topic modeling, and text analysis. Language detection is supported as a side feature (it returns the source language when you perform any task). There are some peculiarities in the solutions provided by Watson Natural Language Understanding. Let’s explore them more carefully.
Entity recognition in Natural Language Understanding allows detecting people, dates, places, organizations, geopolitical entities, etc. It not only returns the confidence score but also returns the subtype of the entity. For example, when it deals with famous people, it does not only say that this is a person, but it also recognizes that this person is an actor, award winner, and so on. Also, it can even return a link to corresponding DBpedia resource.
Sentiment analysis with the help of Natural Language Understanding also provides additional helpful features. It can not only define whether the sentiment is positive or negative but can also return sentiment separately for each detected entity, keyword phrase or even predefined target piece of the sentence. The service is also capable of the emotion recognition (anger, disgust, fear, joy, or sadness) for the whole text as well as for separate detected keywords, entities or user-specified target phrases. Confidence scores are returned as well.
Keywords extraction here is pretty simple and standard. It returns keywords along with the confidence scores for each detected keyword.
Topic modeling is provided by returning up to 5 levels hierarchy of the text categories. Also, the system can detect more than 1 chain of categories. For example, if you feed the text about the Titanic, it can return one chain of categories concerning ships, and another chain concerning shipwrecks.
Text analysis in Watson Natural Language Understanding consists of three major parts: finding relations in the text, analyzing the semantic roles and extracting the text’s metadata. The system can determine the relations between the entities. The analysis of the semantic roles allows detecting subject-action-object chains in the sentences. The platform can derive metadata (author, title, date of creation, etc.) both from the text or HTML.
Today, IBM Watson Natural Language Understanding supports 13 languages. However, some features are not yet available for particular languages. The system’s price depends on the amounts of texts you need to process and on the number of features you use. Therefore, it is rather flexible and affordable for both small businesses and large companies.
Based on our experience, IBM Watson Natural Language Understanding has good performance. Despite there was a need to analyze and filter the outcomes of the service in several tasks, in general, the platform operates very well.
Microsoft Azure (Text Analytics API)
Text Analytics API is an element of the Microsoft Azure infrastructure. It proposes a relatively poor set of solutions. It supports only language detection, keyphrase extraction, and sentiment analysis. There is also a limited number of positive results each feature can return. For instance, there are no confidence scores for keyphrase extraction and sentiment may be either negative or positive. However, it supports a vast number of languages. In addition, the service produces perfect results within a short period of time.
There are a free tier and five options for a chargeable usage. The levels differ from each other by the number of maximum allowed transactions per year. Also, there may be some variations in prices across different regions (see this page for more details).
Microsoft Azure (Linguistic Analysis API Preview)
Linguistic Analytics API is a part of the Microsoft Azure platform too.
This product attempts to extend the NLP functionality of the previous service (Text Analytics API), which has limited functionality. The Linguistic Analysis API proposes such solutions as sentences separation, tokenization, Part-of-Speech tagging, relations in the sentences analysis.
Sentence separation is the first step in the analysis. Linguistic Analysis API splits the text into sentences and then tokenizes the words in them.
POS-tagging allows determining what word to what part of speech belongs. The tool can return input sentences with the POS-tag near each word.
In our opinion, the most interesting thing here is the ability of the Linguistic Analysis API to build the schema of the connections between words in the sentences. Out of this diagram, you can understand how and which words are connected with each other.
As the platform is on the stage of testing, there is no pricing for it yet. We suppose that the prices will also depend on the number of transactions within the system.
Google Cloud Natural Language
Google Cloud Natural Language is a part of the Google Cloud infrastructure. It enables you to perform such tasks as sentiment analysis, entity recognition, topic modeling, and text analysis.
Sentiment analysis in this system allows detecting the sentiment of the sentences, or for the entire document and for each word in the sentences. The API returns the score in the range from -1 to 1, where -1 means very negative sentiment and 1 means very positive. In addition, the system detects the magnitude of the sentiment (the strength) which can vary from 0 to infinity.
Entity recognition detects types of entities in the text and returns the importance of each word to the entire text document (in the range of 0 to 1).
Topic modeling allows building several chains of categories of the text and the confidence score for each chain.
Text analysis seems to be quite effectual in the Google Cloud Natural Language. It can find the relations in the sentences, detect POS-tags, lemmas of the words. It also provides morphological analysis (number, proper tense, gender, person, a case of the word, etc.). The relations between the words may be represented in the form of the dependency trees.
Google Cloud Translation API
This instrument provides both machine translation and language detection. It is simple to integrate Google Cloud Translation API with your service. It uses deep neural networks for translation. These networks improve continuously. There is no need to extract and send a text to the API, you can send the entire HTML document.
The pricing is flexible: you pay on the per character basis. There is separate pricing for translation and for the language detection. If you need to process up to 1 billion characters per month, the price is 20 USD per 1 million characters. If you plan to process more than 1 billion characters per month, you can contact the support to discuss possible discounts.
IBM Watson Translator
IBM Watson infrastructure contains IBM Watson Translator for neural machine translation. The main downside of this tool is the limited number of the supported languages. The main benefit is that it allows customization. For instance, if your texts include specific terminology the IBM Watson Translator can adapt to this terminology to work with it properly. It also includes some pre-trained language models like News, Conversation, etc. However, the models are available for an even smaller number of languages.
The pricing is flexible. You can choose out of 4 available levels (Lite, Standard, Advanced, and Premium). Each new level provides more functionality and allows processing more characters, so correspondingly the price is higher.
Amazon Translate
Amazon Translate is an element of the Amazon Web Services infrastructure. It allows fast translating in the real-time as well as by feeding the entire documents (batch). The tool is not well developed yet, so it supports only 12 languages. It isn’t available for customization and doesn’t use language models. However, developers state, the service will be improved in the near future, for example, 6 more languages will be added.
The Free Tier is available during the first 12 months. Then, you will have to pay 15 USD per 1 million processed characters.
Microsoft Azure Translator Text API
Microsoft Azure Translator Text API uses deep neural networks to improve the quality of the machine translation. This method takes into account not only the neighboring words but also the context of the entire sentence. The documentation is quite simple and clear. The tool also allows users to customize translations.
Microsoft suggests 5 different pricing plans. Processing less than 1 million characters per month is free of charge. If you choose an S1 plan, you will have to pay 10 USD per million characters. S2, S3, and S4 plans have fixed prices and the maximum amount of characters to process.
We have compiled a table comparing the main characteristics of these APIs for each separate task. Hopefully, it will help you to choose the API that is compatible with your needs.
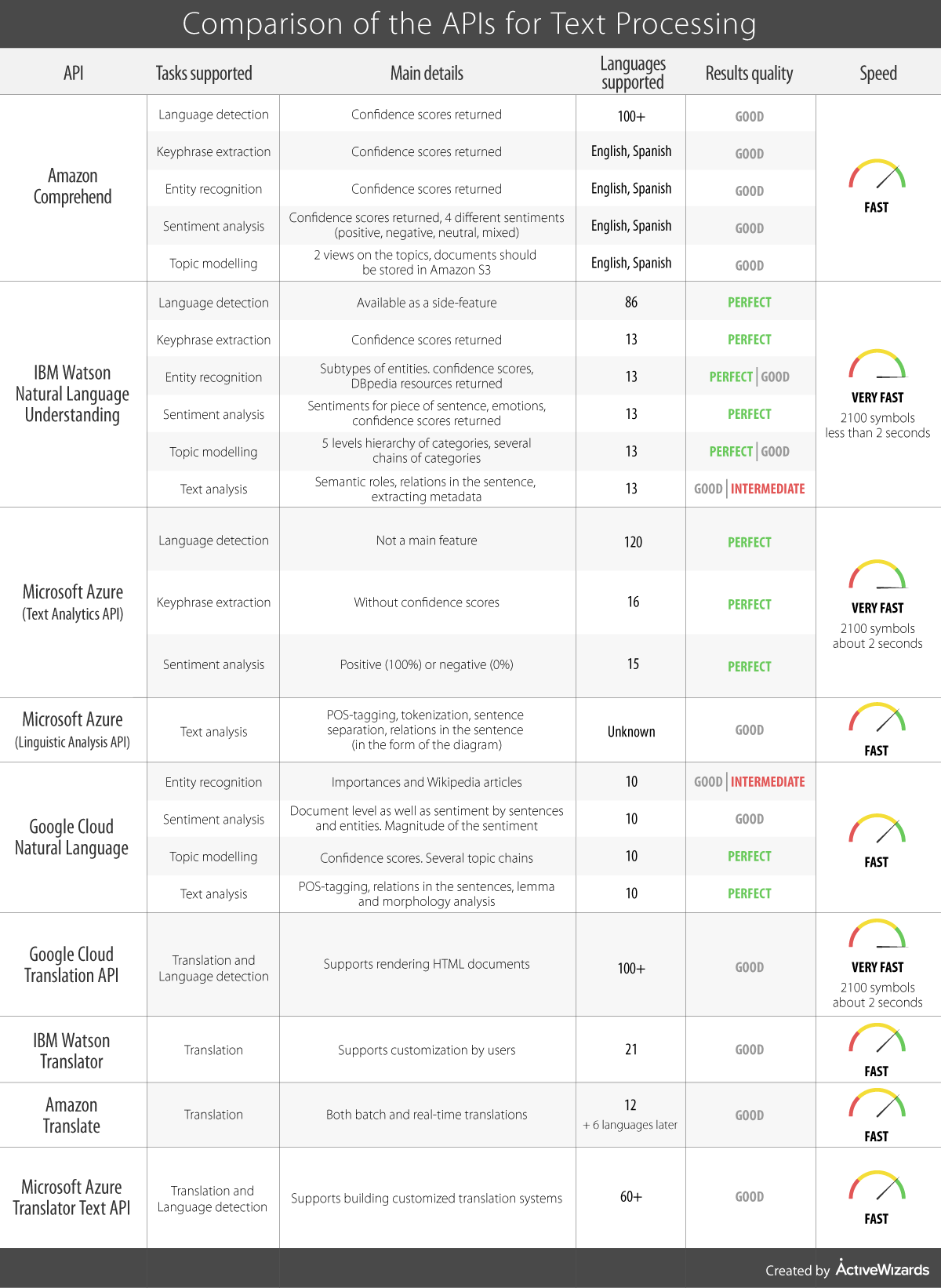
Updated: August 2018
Conclusion
In this article, we highlighted and analyzed key characteristics of different APIs developed for text processing. Although all the APIs we mentioned pursue almost the same goals, they tend to have as many distinctive features as those in common. In order to select the best variant suiting your needs, you have to know for sure about the number of different languages you are going to work with. Another important issue to clarify is whether you are going to process the source text or you are looking for a helpful translation tool.
The majority of these APIs provide fast performance, and all of them are subjects for future improvements by the developers. Therefore, you always have some space for the development of your services. Finally, you should take into consideration the quality of the output along with the period of time within which it may be received.
These APIs have proved to be extremely useful, based on our experience, so we attempted to list all their key features in a comprehensible manner for you. However, there are many other APIs, which deserve to be looked at, so share your favorites in the comment section.
Thank you for your attention!
ActiveWizards is a team of data scientists and engineers, focused exclusively on data projects (big data, data science, machine learning, data visualizations). Areas of core expertise include data science (research, machine learning algorithms, visualizations and engineering), data visualizations ( d3.js, Tableau and other), big data engineering (Hadoop, Spark, Kafka, Cassandra, HBase, MongoDB and other), and data intensive web applications development (RESTful APIs, Flask, Django, Meteor).
Original. Reposted with permission.
Related:
- Top 20 Python Libraries for Data Science in 2018
- Top 20 R Libraries for Data Science in 2018
- Top 15 Scala Libraries for Data Science in 2018