Synthetic Data Generation: A must-have skill for new data scientists
A brief rundown of methods/packages/ideas to generate synthetic data for self-driven data science projects and deep diving into machine learning methods.

Introduction
Data is the new oil and truth be told only a few big players have the strongest hold on that currency. Googles and Facebooks of this world are so generous with their latest machine learning algorithms and packages (they give those away freely) because the entry barrier to the world of algorithms is pretty low right now. Open source has come a long way from being christened evil by the likes of Steve Ballmer to being an integral part of Microsoft. And plenty of open source initiatives are propelling the vehicles of data science, digital analytics, and machine learning.
Standing in 2018 we can safely say that, algorithm, programming frameworks, and machine learning packages (or even tutorials and courses how to learn these techniques) are not the scarce resource but high-quality data is.
This often creates a complicated issue for the beginners in data science and machine learning. I faced it myself years back when I started my journey in this path.
Let me also be very clear that in this article, I am only talking about the scarcity of data for learning the purpose and not for running any commercial operation. It is not a discussion about how to get quality data for the cool travel or fashion app you are working on. That kind of consumer, social, or behavioral data collection presents its own issue. However, even something as simple as having access to quality datasets for starting one’s journey into data science/machine learning turns out, not so simple, after all.
Critical for self-driven data science
Data science is hot and selling. And, people are moving into data science. They are changing careers, paying for boot-camps and online MOOCs, building network on LinkedIn. But many such new entrants face difficulty maintaining the momentum of learning the new trade-craft once they are past the regularized curricula of their course and into uncertain zone.
What problem to solve? Which MOOC to focus on? What Kaggle competition to take part in? What new ML package to learn? What kind of projects to showcase on the Github? How much mathematics skill to acquire?
Basically, how to build a great data science portfolio? — As per a highly popular article, the answer is by doing public work e.g. contributing to open source and showcasing innovative thinking and original contribution with data modeling, wrangling, visualization, or machine learning algorithms.
But sadly, often there is no benevolent guide or mentor and often, one has to self-propel.
The person who can successfully navigate this grey zone, is said to have found his/her mojo in the realm of self-driven data science. That person is going to go far. But to make that journey fruitful, (s)he has to have access to high-quality dataset for practice and learning.
What kind of data may be needed for a rich learning experience?
Imagine you are tinkering with a cool machine learning algorithm like SVM or a deep neural net. What kind of dataset you should practice them on? If you are learning from scratch, the advice is to start with simple, small-scale datasets which you can plot in two dimensions to understand the patterns visually and see for yourself the working of the ML algorithm in an intuitive fashion. For example, here is an excellent article on various datasets you can try at various level of learning.
This is a great start. But it is not all.
Sure, you can go up a level and find yourself a real-life large dataset to practice the algorithm on.
But that is still a fixed dataset, with a fixed number of samples, a fixed pattern, and a fixed degree of class separation between positive and negative samples (if we assume it to be a classification problem).
Are you learning all the intricacies of the algorithm in terms of
- sample complexity,
- computational efficiency,
- ability to handle class imbalance,
- robustness of the metrics in the face of varying degree of class separation
- bias-variance trade-off as a function of data complexity
Probably not. No single dataset can lend all these deep insights for a given ML algorithm. But, these are extremely important insights to master for you to become a true expert practitioner of machine learning.
So, you will need an extremely rich and sufficiently large dataset, which is amenable enough for all these experimentation.
What can you do?
So, what can you do in this situation? Scour the internet for more datasets and just hope that some of them will bring out the limitations and challenges, associated with a particular algorithm, and help you learn?
Yes, it is a possible approach but may not be the most viable or optimal one in terms of time and effort. Good datasets may not be clean or easily obtainable. You may spend much more time looking for, extracting, and wrangling with a suitable dataset than putting that effort to understand the ML algorithm.
The experience of searching for a real life dataset, extracting it, running exploratory data analysis, and wrangling with it to make it suitably prepared for a machine learning based modeling is invaluable. I am currently working on a course/book just on that topic.
But that can be taught and practiced separately. In many situations, however, you may just want to have access to a flexible dataset (or several of them) to ‘teach’ you the ML algorithm in all its gory details.
Surprisingly enough, in many cases, such teaching can be done with synthetic datasets.
What is a synthetic dataset?
As the name suggests, quite obviously, a synthetic dataset is a repository of data that is generated programmatically. So, it is not collected by any real-life survey or experiment. Its main purpose, therefore, is to be flexible and rich enough to help an ML practitioner conduct fascinating experiments with various classification, regression, and clustering algorithms. Desired properties are,
- It can be numerical, binary, or categorical (ordinal or non-ordinal),
- The number of features and length of the dataset should be arbitrary
- It should preferably be random and the user should be able to choose a wide variety of statistical distribution to base this data upon i.e. the underlying random process can be precisely controlled and tuned,
- If it is used for classification algorithms, then the degree of class separation should be controllable to make the learning problem easy or hard,
- Random noise can be interjected in a controllable manner
- For a regression problem, a complex, non-linear generative process can be used for sourcing the data
Although in this article, we keep our discussions limited to synthetic data for better ML algorithms, its purpose can be far reaching in cases where it helps get around security and privacy concerns with real datasets, that cannot be used or acquired for learning purpose. For example, think about medical or military data. Here is an excellent summary article about such methods.
In the next few sections, we show some quick methods to generate synthetic dataset for practicing statistical modeling and machine learning.
The demo notebook can be found here in my Github repository.
Data generation with scikit-learn methods
Scikit-learn is an amazing Python library for classical machine learning tasks (i.e. if you don’t care about deep learning in particular). However, although its ML algorithms are widely used, what is less appreciated is its offering of cool synthetic data generation functions.
scikit-learn: machine learning in Pythonscikit-learn.org
Here is a quick rundown,
Regression problem generation: Scikit-learn’s dataset.make_regressionfunction can create random regression problem with arbitrary number of input features, output targets, and controllable degree of informative coupling between them. It can also mix Gaussian noise.

Fig: Random regression problem generation using scikit-learn with varying degree of noise.
Classification problem generation: Similar to the regression function above, dataset.make_classification generates a random multi-class classification problem (dataset) with controllable class separation and added noise. You can also randomly flip any percentage of output signs to create a harder classification dataset if you want.
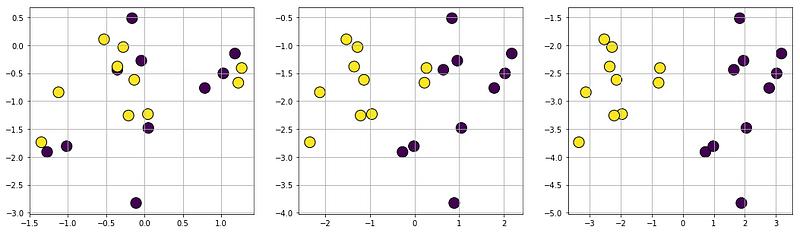
Fig: Random classification problem generation using scikit-learn with varying class separation.
Clustering problem generation: There are quite a few functions for generating interesting clusters. The most straightforward one is datasets.make_blobs, which generates arbitrary number of clusters with controllable distance parameters.
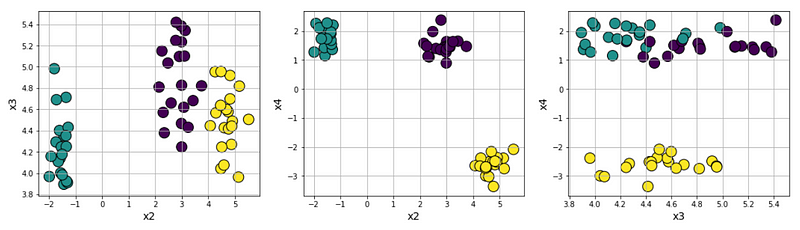
Fig: Simple cluster data generation using scikit-learn.
Anisotropic cluster generation: With a simple transformation using matrix multiplication, you can generate clusters which is aligned along certain axis or anisotropically distributed.
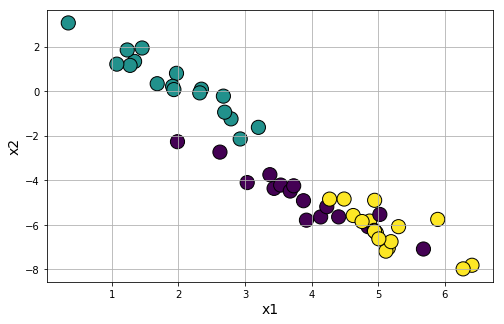
Fig: Anisoproically aligned cluster data generation using scikit-learn.
Concentric ring cluster data generation: For testing affinity based clustering algorithm or Gaussian mixture models, it is useful to have clusters generated in a special shape. We can use datasets.make_circles function to accomplish that.
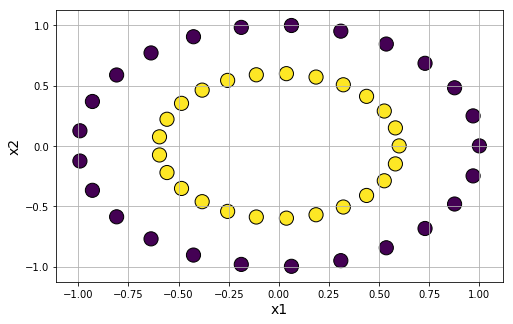
And, of course we can mix a little noise to the data to test the robustness of the clustering algorithm,
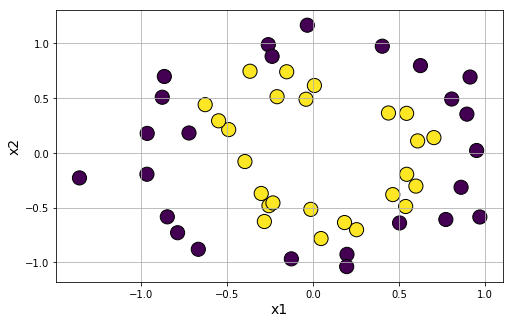
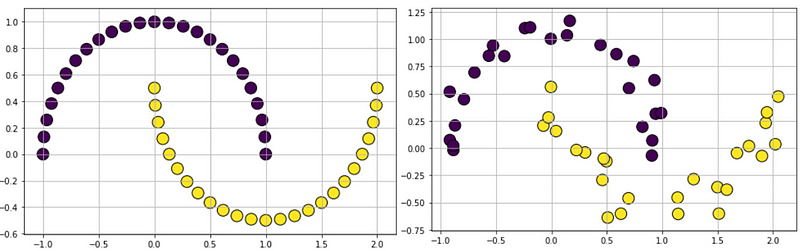
Moon-shaped cluster data generation: We can also generate moon-shaped cluster data for testing algorithms, with controllable noise using datasets.make_moons function.