MLOps – “Why is it required?” and “What it is”?
Creating an model that works well is only a small aspect of delivering real machine learning solutions. Learn about the motivation behind MLOps, the framework and its components that will help you get your ML model into production, and its relation to DevOps from the world of traditional software development.
By Arnab Bose, Chief Scientific Officer, and Aditya Aggarwal, Advanced Analytics Practice Lead, Abzooba
MLOps Motivation
Machine Learning (ML) models built by data scientists represent a small fraction of the components that comprise an enterprise production deployment workflow, as illustrated in Fig 1 [1] below. To operationalize ML models, data scientists are required to work closely with multiple other teams such as business, engineering, and operations. This represents organizational challenges in terms of communication, collaboration, and coordination. The goal of MLOps is to streamline such challenges with well-established practices. Additionally, MLOps brings about agility and speed that is a cornerstone in today's digital world.
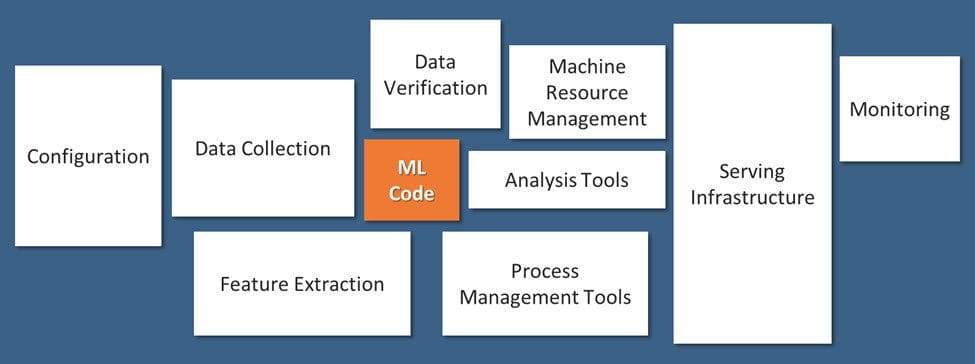
Fig 1: Only a small fraction of real-world ML systems are composed of the ML code, as shown by the small box in the middle. The required surrounding infrastructure is vast and complex.
MLOps challenges similar to DevOps
The challenges of ML model operationalization have a lot in common with software productionisation where DevOps has proven itself.
Therefore, adopting the best practices from DevOps is a prudent approach to help data scientists overcome challenges common to software productionisation. For example, the use of agile methodology promoted by DevOps in contrast to waterfall methodology is an efficiency boost. Additional DevOps practices used in MLOps are listed in Table 1.
Table 1: MLOps leveraging DevOps.
| ML model operationalization Challenges | Solution from DevOps |
| 1) Continuous integration and continuous delivery (CI/CD): To set up a pipeline such that the updates are continuously built and ready for production accurately, securely, and seamlessly. | Use a CI/CD framework to build, test, and deploy software. It offers the benefits of reproducibility, security, and code version control. |
| 2) Longer development to deployment lifecycle: Data Scientists develop models/algorithms and hand them over to operations to deploy into production. Lack of coordination and improper handoff between the two parties lead to delays and errors.
3) Ineffective communication between teams leads to delays in the final solution: The evaluation of an ML solution usually comes towards the end of the project lifecycle. With the development teams usually working in silos, the solution becomes a black-box to other stakeholders. This is worsened by the lack of intermediate feedback. These pose significant challenges in terms of time, effort, and resources. |
Agile methodology solves this coordination problem by enforcing an end-to-end pipeline set up at the initial stage itself. Agile methodology divides the project into a sprint. In each sprint, developers deliver incremental features that are ready for deployment. The output from each sprint (made using pipelines) is visible to each and every member from a very early stage of the project. Therefore, the risk of last-minute surprises reduces, and early feedback becomes a common practice. In industry parlance, this does a "shift left" to coordination issues. |
MLOps challenges different from DevOps
According to industry parlance, MLOps is DevOps for ML. While it is true to some extent, there are challenges typical to ML that need to be addressed by MLOps platforms.
An example of such a challenge is the role of data. In traditional software engineering (i.e., software 1.0), developers write logic and rules (as code) that are well defined in the program space, as demonstrated in Fig 2 [2]. However, in machine learning (i.e., software 2.0), data scientists write code that defines how to use parameters to solve a business problem. The parameter values are found using data (with techniques such as gradient descent). These values may change with different versions of the data, thereby changing the code behavior. In other words, data plays an equally important role as the written code in defining the output. And both can change independently of each other. This adds a layer of data complexity in addition to the model code as an intrinsic part of the software that needs to be defined and tracked.
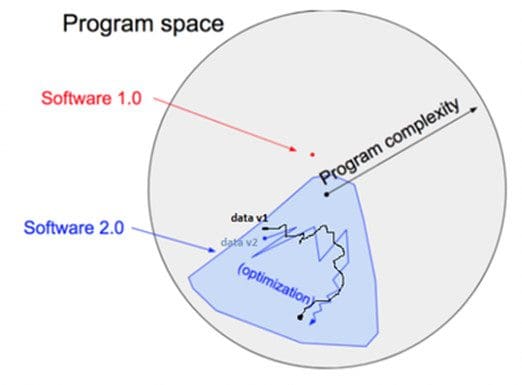
Fig 2: Software 1.0 vs. Software 2.0.
The various challenges that need to be taken care of by an MLOps platform are listed in Table 2.
Table 2: ML specific challenges.
| ML Specific challenges | Description |
| 1) Data and hyper-parameters versioning | In traditional software application, code versioning tools are used to track changes. Version control is a prerequisite for any continuous integration (CI) solution as it enables reproducibility in a fully automated fashion. Any change in source code triggers the CI/CD pipeline to build, test and deliver production-ready code.
In Machine Learning, output model can change if algorithm code or hyper-parameters or data change. While code and hyper-parameters are controlled by developers, change in data may not be. This warrants the concept of data and hyper-parameters versioning in addition to algorithm code. Note that data versioning is a challenge for unstructured data such as images and audio and that MLOps platforms adopt unique approaches to this challenge. |
| 2) Iterative development and experimentations | ML algorithm and model development is iterative and experimental. It requires a lot of parameter tuning and feature engineering. ML pipelines work with data versions, algorithm code versions and/or hyper-parameters. Any change in these artifacts (independently) trigger new deployable model versions that warrant experimentation and metrics calculations. MLOps platforms tracks the complete lineage for these artifacts. |
| 3) Testing | Machine Learning requires data and model testing to detect problems as early in the ML pipeline as possible.
a) Data validation - check that the data is clean with no anomalies and new data is conformant to prior distribution. b) Data preprocessing - check that data is preprocessed efficiently and in a scalable manner and avoid any training-serving skew [3]. c) Algorithm validation - track classification / regression metrics based on business problem as well as ensure algorithm fairness. |
| 4) Security | ML models in production are often part of a larger system where its output is consumed by applications that may or may not be known. This exposes multiple security risks. MLOps needs to provide security and access control to make sure outputs of ML models is used by known users only. |
| 5) Production Monitoring | Models in production requires continuous monitoring to make sure models are performing per expectation as they process new data. There are multiple dimensions of monitoring such as covariate shift, prior shift, among others |
| 6) Infrastructure requirement | ML applications need scale and compute power that translates into complex infrastructure. For example, GPU may be necessary during experimentations and production scaling may be necessary dynamically. |
MLOps Components
With the background in MLOps and its similarity to as well difference from DevOps, the following describes the different components that comprise an MLOps framework, as shown in Fig 3. The workflow underlying them is through the agile methodology, as indicated in Section 2.

Fig 3: MLOps Framework.
- Use case discovery: This stage involves collaboration between business and data scientists to define a business problem and translate that into a problem statement and objectives solvable by ML with associated relevant KPIs (Key Performance Indicator).
- Data Engineering: This stage involves collaboration between a data engineer and a data scientist to acquire data from various sources and prepare the data (processing/validation) for modeling.
- Machine Learning pipeline: This stage is designing and deploying a pipeline integrated with CI/CD. Data scientists use pipelines for multiple experimentation and testing. The platform keeps track of data and model lineage and associated KPIs across the experiments.
- Production deployment: This stage accounts for secure and seamless deployment into the production server of choice, be it public cloud, on-premise, or hybrid.
- Production monitoring: This stage includes both model and infrastructure monitoring. Models are continuously monitored using configured KPIs like changes in input data distribution or changes in model performance. Triggers are set for more experimentations with new algorithms, data, and hyper-parameters that generate a new version of the ML pipeline. Infrastructure is monitored per memory and compute requirements and to scale as needed.
References
- Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison, “Hidden technical debt in machine learning systems”, in Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, 2015, pp. 2503–2511. [Online]. Available: http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems
- Karpathy, "Software 2.0", November 12, 2017 [Online]. Available: https://medium.com/@karpathy/software-2-0-a64152b37c35
- Breck, M. Zinkevich, N. Polyzotis, S. Whang and S. Roy, "Data validation for machine learning", in Proceedings of the 2nd SysML Conference, Palo Alto, CA, USA, 2019. Available: https://mlsys.org/Conferences/2019/doc/2019/167.pdf
Bios: Dr. Arnab Bose is Chief Scientific Officer at Abzooba, a data analytics company and an adjunct faculty at the University of Chicago where he teaches Machine Learning and Predictive Analytics, Machine Learning Operations, Time Series Analysis and Forecasting, and Health Analytics in the Master of Science in Analytics program. He is a 20-year predictive analytics industry veteran who enjoys using unstructured and structured data to forecast and influence behavioral outcomes in healthcare, retail, finance, and transportation. His current focus areas include health risk stratification and chronic disease management using machine learning, and production deployment and monitoring of machine learning models.
Aditya Aggarwal serves as Data Science – Practice Lead at Abzooba Inc. With more than 12+ years of experience in driving business goals through data-driven solutions, Aditya specializes in predictive analytics, machine learning, business intelligence & business strategy across a range of industries.
Related: