Data Science at the Command Line: The Free eBook
If you are familiar with Python & R, then improve your current data science workflow by integrating Unix power tools.
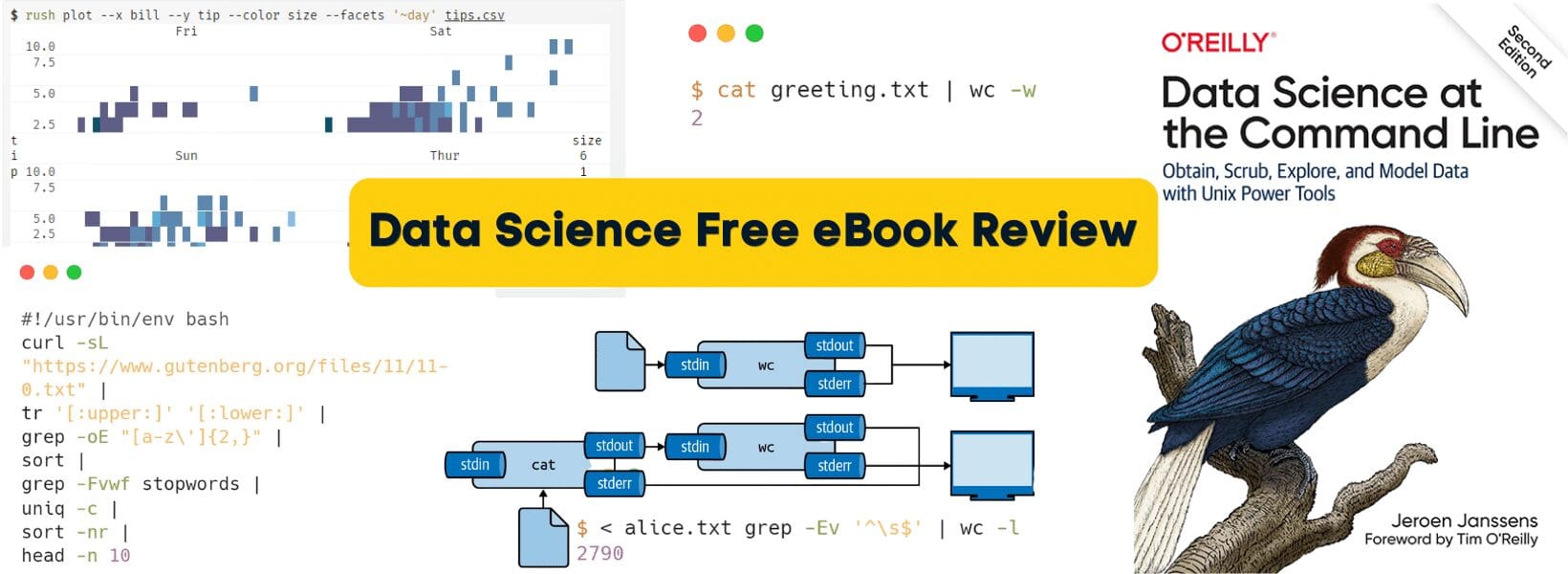
Image by author
At the end of last year, I was quite motivated to learn everything about MLOps, and my end goal was to build an end-to-end machine learning system. Just like other curious heads, I signed up for the MLOps event by Noah Gift. He was promoting his book and tutorial on Coursera. I was just surprised by how I never learned command-line tools and how they are essential for automation. During the Q&A session, I told him about my obsession, and he guided me to take his mini-course on DataCamp: Command Line Automation in Python. This course gave me a new perspective about data pipelines, editing data, creating scripts, and how a single line of code on a terminal can produce the same results as 15 lines of code on Python. So, I kept looking for the best material on the command line, and then I found Data Science at the Command Line by Jeroen Janssens.
About The Book

Get Free eBook | Star a GitHub Repo | Book on Amazon
The book explains with coding examples on how we can use Unix power tools to perform all of the tasks related to data science. This book is for all data professionals, engineers, system administrators, and researchers. The free eBook is interactive, and It took me no time to go through all of the core topics. I have read epubs, pdfs, and hard copy, but this style of reading books is next level. It’s like reading the documentation of your favorite library but better.
The book covers:
- Obtaining Data
- Creating Command-line Tools
- Scrubbing Data
- Project Management with Make
- Exploring Data
- Parallel Pipelines
- Modeling Data
- Polyglot Data Science
In this book, you will learn how to use APIs, datasets, and spreadsheets to extract the data. Then perform data clearing and manipulation operations. After that, you will learn data analysis and visualization using rush. You will also learn to manage data science workflow, create parallel pipelines, and build machine learning models (regression, classification). Apart from core topics, you will also learn on how Unix power tools will make you more productive in running quick data analysis.
I love how we can use csvsql to run SQL queries on a CSV file and how we can use the rush to plot all kinds of graphs. I have never seen any machine learning engineer preprocessing the data, creating models, and evaluating the results using command-line tools. When I first read about the modeling section, I was skeptical, I knew they must be running Python or R scripts to train, but to my surprise, the author used vw to train and run evaluation.
Special Features
There are many features in this book that stand out, but some of them were so mind-blowing, and I will be mentioning them in this review.
Data Analysis
One-liner data analysis with a combination of power tools and SQL queries is something I never imagined. This book explains various ways of extracting and analyzing data, such as using grep, header, trim, and csvsql.
$ seq 5 | header -a val | csvsql --query "SELECT SUM(val) AS sum FROM stdin" sum 15.0
Data Visualization
The book shows how you can use the rush to perform any R-based data analysis. Run complex statistics function, explore data, and then visualize it in any form using ggplot. The book also teaches you to create your tool to streamline your current workflow.
$ rush plot --x tip --fill time --geom density tips.csv > plot-density.png $ display plot-density.png
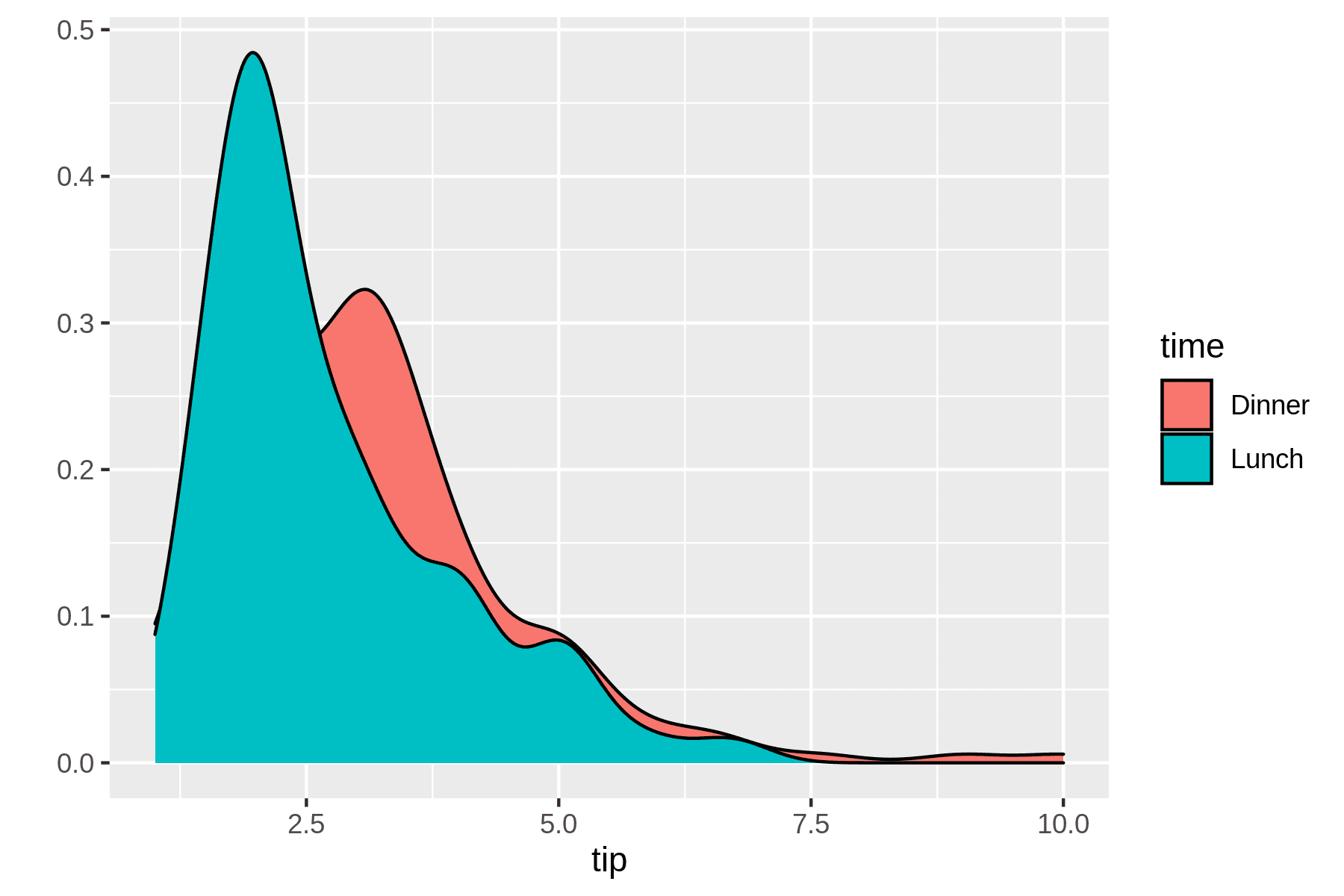
Model Training
I am still surprised at how we can use vw to run regression and skll to train classification models. I don’t want to spoil more, because you need to experience it on your own to understand it.
$ skll -l classify.cfg 2>/dev/null
These tools take multiple arguments and train models using the same algorithms. Nothing is different about it. It’s just we are doing all of this with a single line of the script. In Python, we have to write at least 20-30 lines to get similar results.
$ < output/wine_summary.tsv csvsql --query "SELECT learner_name, accuracy FROM s tdin ORDER BY accuracy DESC" | csvlook -I │ learner_name │ accuracy │ ├────────────────────────┼───────────┤ │ LogisticRegression │ 0.9953125 │ │ RandomForestClassifier │ 0.9953125 │ │ KNeighborsClassifier │ 0.99375 │ │ DecisionTreeClassifier │ 0.984375 │
GNU Parallel Pipelines
If you are working with a large file or downloading large datasets, parallel will reduce the time to run any computational process. It will allow you to parallelize and distribute commands and pipelines. Best thing about parallel is that you don’t have to modify the current tools in order to run a parallel task.
$ seq 0 2 100 | parallel "echo {}^2 | bc" | trim
0
4
16
36
64
100
144
196
256
324
... with 41 more lines
Conclusion
Data science is an exciting field, and command-line tools make it more interesting as it takes away complexity and provides you with new and easy ways to perform the task with a single line of code. The book perfectly explains the need for these power tools and how we can leverage them to improve the current data science workflow. If you have made up your mind on reading this book, then I will suggest that you learn by writing the scripts and testing them on your own. The book also guides you to pull and run a docker image so that you don’t have to install the Unix power tools manually.
The free eBook is under the CC BY-NC-ND 4.0 License. You can also buy a physical copy at Amazon.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master's degree in Technology Management and a bachelor's degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.