How Activation Functions Work in Deep Learning
Check out a this article for a better understanding of activation functions.
Let's start with a definition of activation function:
“In artificial neural networks, each neuron forms a weighted sum of its inputs and passes the resulting scalar value through a function referred to as an activation function.”
—Definition from Wikipedia
Sounds a little complicated? Don’t worry! After reading this article, you will have a better understanding of activation functions.
In humans, our brain receives input from the outside world, performs processing on the neuron receiving input and activates the neuron tail to generate required decisions. Similarly, in neural networks, we provide input as images, sounds, numbers, etc., and processing is performed on the artificial neuron, with an algorithm activating the correct final neuron layer to generate results.
Why do we need activation functions?
An activation function determines if a neuron should be activated or not activated. This implies that it will use some simple mathematical operations to determine if the neuron’s input to the network is relevant or not relevant in the prediction process.
The ability to introduce non-linearity to an artificial neural network and generate output from a collection of input values fed to a layer is the purpose of the activation function.
Types of Activation functions
Activation functions can be divided into three types:
- Linear Activation Function
- Binary Step Function
- Non-linear Activation Functions
Linear Activation Function
The linear activation function, often called the identity activation function, is proportional to the input. The range of the linear activation function will be (-∞ to ∞). The linear activation function simply adds up the weighted total of the inputs and returns the result.
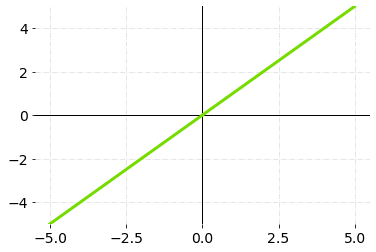
Linear Activation Function — Graph
Mathematically, it can be represented as:
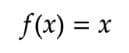
Linear Activation Function — Equation
Pros and Cons
- It is not a binary activation because the linear activation function only delivers a range of activations. We can surely connect a few neurons together, and if there are multiple activations, we can calculate the max (or soft max) based on that.
- The derivative of this activation function is a constant. That is to say, the gradient is unrelated to the x (input).
Binary Step Activation Function
A threshold value determines whether a neuron should be activated or not activated in a binary step activation function.
The activation function compares the input value to a threshold value. If the input value is greater than the threshold value, the neuron is activated. It’s disabled if the input value is less than the threshold value, which means its output isn’t sent on to the next or hidden layer.
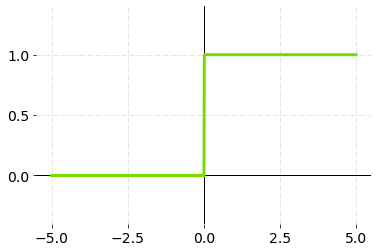
Binary Step Function — Graph
Mathematically, the binary activation function can be represented as:
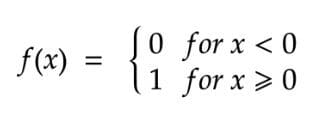
Binary Step Activation Function — Equation
Pros and Cons
- It cannot provide multi-value outputs — for example, it cannot be used for multi-class classification problems.
- The step function’s gradient is zero, which makes the back propagation procedure difficult.
Non-linear Activation Functions
The non-linear activation functions are the most-used activation functions. They make it uncomplicated for an artificial neural network model to adapt to a variety of data and to differentiate between the outputs.
Non-linear activation functions allow the stacking of multiple layers of neurons, as the output would now be a non-linear combination of input passed through multiple layers. Any output can be represented as a functional computation output in a neural network.
These activation functions are mainly divided basis on their range and curves. The remainder of this article will outline the major non-linear activiation functions used in neural networks.
1. Sigmoid
Sigmoid accepts a number as input and returns a number between 0 and 1. It’s simple to use and has all the desirable qualities of activation functions: nonlinearity, continuous differentiation, monotonicity, and a set output range.
This is mainly used in binary classification problems. This sigmoid function gives the probability of an existence of a particular class.
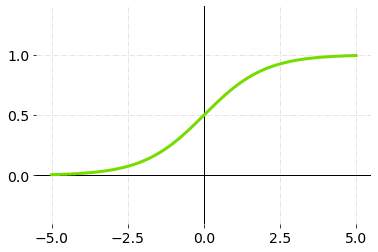
Sigmoid Activation Function — Graph
Mathematically, it can be represented as:
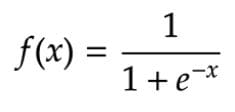
Sigmoid Activation Function — Equation
Pros and Cons
- It is non-linear in nature. Combinations of this function are also non-linear, and it will give an analogue activation, unlike binary step activation function. It has a smooth gradient too, and It’s good for a classifier type problem.
- The output of the activation function is always going to be in the range (0,1) compared to (-∞, ∞) of linear activation function. As a result, we’ve defined a range for our activations.
- Sigmoid function gives rise to a problem of “Vanishing gradients” and Sigmoids saturate and kill gradients.
- Its output isn’t zero centred, and it makes the gradient updates go too far in different directions. The output value is between zero and one, so it makes optimization harder.
- The network either refuses to learn more or is extremely slow.
2.TanH (Hyperbolic Tangent)
TanH compress a real-valued number to the range [-1, 1]. It’s non-linear, But it’s different from Sigmoid,and its output is zero-centered. The main advantage of this is that the negative inputs will be mapped strongly to the negative and zero inputs will be mapped to almost zero in the graph of TanH.
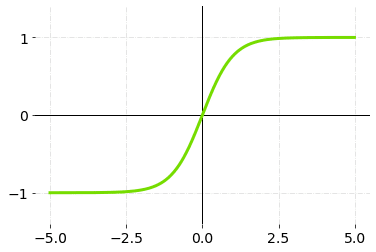
TanH Activation Function — Graph
Mathematically, TanH function can be represented as:
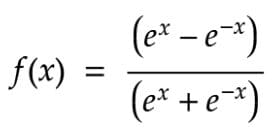
TanH Activation Function — Equation
Pros and Cons
- TanH also has the vanishing gradient problem, but the gradient is stronger for TanH than sigmoid (derivatives are steeper).
- TanH is zero-centered, and gradients do not have to move in a specific direction.
3.ReLU (Rectified Linear Unit)
ReLU stands for Rectified Linear Unit and is one of the most commonly used activation function in the applications. It’s solved the problem of vanishing gradient because the maximum value of the gradient of ReLU function is one. It also solved the problem of saturating neuron, since the slope is never zero for ReLU function. The range of ReLU is between 0 and infinity.
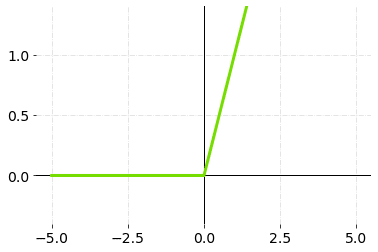
ReLU Activation Function — Graph
Mathematically, it can be represented as:
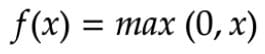
ReLU Activation Function — Equation
Pros and Cons
- Since only a certain number of neurons are activated, the ReLU function is far more computationally efficient when compared to the sigmoid and TanH functions.
- ReLU accelerates the convergence of gradient descent towards the global minimum of the loss function due to its linear, non-saturating property.
- One of its limitations is that it should only be used within hidden layers of an artificial neural network model.
- Some gradients can be fragile during training.
- In other words, For activations in the region (x<0) of ReLu, the gradient will be 0 because of which the weights will not get adjusted during descent. That means, those neurons, which go into that state will stop responding to variations in input (simply because the gradient is 0, nothing changes.) This is called the dying ReLu problem.
4.Leaky ReLU
Leaky ReLU is an upgraded version of the ReLU activation function to solve the dying ReLU problem, as it has a small positive slope in the negative area. But, the consistency of the benefit across tasks is presently ambiguous.
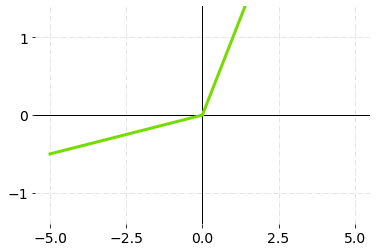
Leaky ReLU Activation Function — Graph
Mathematically, it can be represented as,
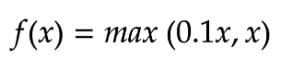
Leaky ReLU Activation Function — Equation
Pros and Cons
- The advantages of Leaky ReLU are the same as that of ReLU, in addition to the fact that it does enable back propagation, even for negative input values.
- Making minor modification of negative input values, the gradient of the left side of the graph comes out to be a real (non-zero) value. As a result, there would be no more dead neurons in that area.
- The predictions may not be steady for negative input values.
5.ELU (Exponential Linear Units)
ELU is also one of the variations of ReLU which also solves the dead ReLU problem. ELU, just like leaky ReLU also considers negative values by introducing a new alpha parameter and multiplying it will another equation.
ELU is slightly more computationally expensive than leaky ReLU, and it’s very similar to ReLU except negative inputs. They are both in identity function shape for positive inputs.
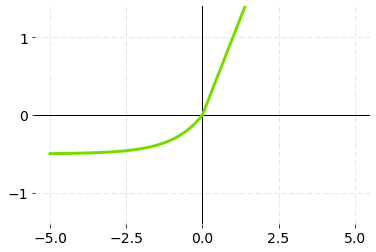
ELU Activation Function-Graph
Mathematically, it can be represented as:
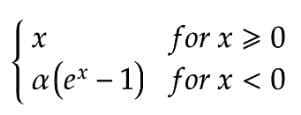
ELU Activation Function — Equation
Pros and Cons
- ELU is a strong alternative to ReLU. Different from the ReLU, ELU can produce negative outputs.
- Exponential operations are there in ELU, So it increases the computational time.
- No learning about the ‘a’ value takes place, and exploding gradient problem.
6. Softmax
A combination of many sigmoids is referred to as the Softmax function. It determines relative probability. Similar to the sigmoid activation function, the Softmax function returns the probability of each class/labels. In multi-class classification, softmax activation function is most commonly used for the last layer of the neural network.
The softmax function gives the probability of the current class with respect to others. This means that it also considers the possibility of other classes too.
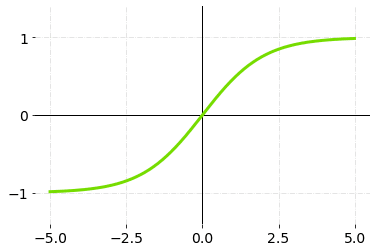
Softmax Activation Function — Graph
Mathematically, it can be represented as:
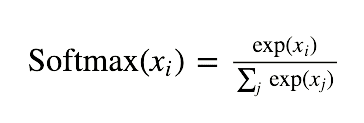
Softmax Activation Function — Equation
Pros and Cons
- It mimics the one encoded label better than the absolute values.
- We would lose information if we used absolute (modulus) values, but the exponential takes care of this on its own.
- The softmax function should be used for multi-label classification and regression task as well.
7. Swish
Swish allows for the propagation of a few numbers of negative weights, whereas ReLU sets all non-positive weights to zero. This is a crucial property that determines the success of non-monotonic smooth activation functions, such as Swish’s, in progressively deep neural networks.
It’s a self-gated activation function created by Google researchers.
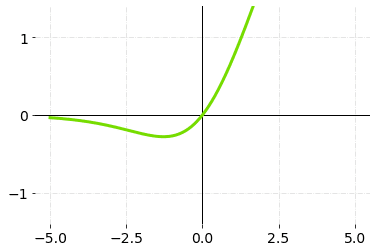
Swish Activation Function — Graph
Mathematically, it can be represented as:
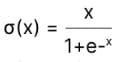
Swish Activation Function — Equation
Pros and Cons
- Swish is a smooth activation function that means that it does not suddenly change direction like ReLU does near x equal to zero. Rather, it smoothly bends from 0 towards values < 0 and then upwards again.
- Non-positive values were zeroed out in ReLU activation function. Negative numbers, on the other hand, may be valuable for detecting patterns in the data. Because of the sparsity, large negative numbers are wiped out, resulting in a win-win situation.
- The swish activation function being non-monotonous enhances the term of input data and weight to be learnt.
- Slightly more computationally expensive and More problems with the algorithm will probably arise given time.
Important Considerations
While choosing the proper activation function, the following problems and issues must be considered:
Vanishing gradient is a common problem encountered during neural network training. Like a sigmoid activation function, some activation functions have a small output range (0 to 1). So a huge change in the input of the sigmoid activation function will create a small modification in the output. Therefore, the derivative also becomes small. These activation functions are only used for shallow networks with only a few layers. When these activation functions are applied to a multi-layer network, the gradient may become too small for expected training.
Exploding gradients are situations in which massive incorrect gradients build during training, resulting in huge updates to neural network model weights. When there are exploding gradients, an unstable network might form, and training cannot be completed. Due to exploding gradients, the weights’ values can potentially grow to the point where they overflow, resulting in loss in NaN values.
Final Takeaways
- All hidden layers generally use the same activation functions. ReLU activation function should only be used in the hidden layer for better results.
- Sigmoid and TanH activation functions should not be utilized in hidden layers due to the vanishing gradient, since they make the model more susceptible to problems during training.
- Swish function is used in artificial neural networks having a depth more than 40 layers.
- Regression problems should use linear activation functions
- Binary classification problems should use the sigmoid activation function
- Multiclass classification problems shold use the softmax activation function
Neural network architecture and their usable activation functions,
- Convolutional Neural Network (CNN): ReLU activation function
- Recurrent Neural Network (RNN): TanH or sigmoid activation functions
You can find countless additional articles evaluating activation function comparisons. I suggest you get your hands dirty and practise well.
If you have any questions, feel free to ask me on LinkedIn or Twitter.
Parthiban Marimuthu (@parthibharathiv) lives in Chennai, India, and works at Spritle Software. Parthiban studies and transforms data science prototypes, designs machine learning systems, and researches and implements appropriate ML algorithms and tools.