An Intuitive Explanation of Collaborative Filtering
The post introduces one of the most popular recommendation algorithms, i.e., collaborative filtering. It focuses on building an intuitive understanding of the algorithm illustrated with the help of an example.
Introduction
AI is ubiquitous and deftly influences our decisions, choices, and preferences across multiple junctures. Many organizations have plenty of data foraged into algorithms to generate insights to improve customer experiences.
E-commerce companies, for example, collect data from the user's clickstream to present the new users with a convenient shopping experience and learn from their changing preferences. If you have purchased products online, then you must have witnessed one or the other recommendations listed below:
1. Recommending products viewed by other users based on the item of interest

Source: Author from Amazon website
2. Recommending additional products that other users often purchase along with the searched product

Source: Author from Amazon website
The above illustrations underpin that the current user gets prompted with several recommendations related to the product of interest, based on what similar users in the past have viewed or bought. These recommendations are derived from the collaborative filtering algorithm - the most popular way to recommend products online.
Notably, the easiest way to recommend a product could also be based on the number of views, ratings, conversions, etc., but that implies that, generally, the users have bought this product. Hence, such a popularity index-based recommendation is ineffective due to non-personalized suggestions.
Collaborative Filtering
The key idea of collaborative filtering is that similar preferences in historical data can give away information about a user’s future preferences.
The word collaborative suggests that users with similar tastes and choices are the most eligible to collaborate and choose whether to recommend this product to the user.
Let’s understand how user-user collaborative filtering works in the coming section.
How does collaborative filtering work?
A product is recommended to the new user depending upon the fondness of similar users for this particular product. In addition to its roots in statistics, it is pretty intuitive to think that our choices are principally coherent with the people we are closer to.
Let’s understand some fundamental concepts from an example shown below:
| Product 1 | Product 2 | Product 3 | Product 4 | Product 5 | Product 6 | Product 7 | Product 8 | |
| User 1 | 5 | 1 | 4 | ? | ? | 4 | 4 | 3 |
| User 2 | 5 | ? | 3 | 2 | ? | ? | 5 | 2 |
| User 3 | 1 | 4 | 2 | 5 | ? | 5 | 2 | 5 |
- Three users have given ratings (consider it as some measure of preference) for eight products
- Not all users give ratings to all the products; hence those cells are marked with a question mark ‘?’
- Either the users have not yet bought those products, or
- They have chosen not to rate certain products leading to sparse matrix
- Note that there could be specific products that have no rating at all, like Product 5 - it could be because these products are new to the market. Similarly, some new users visit the e-commerce website and have no prior record reflecting their preferences to start receiving personalized recommendations.
- Our objective is to find the next set of products for user 2, given the user-product matrix.
Quick and Naive Way to Make Recommendations
User 2 has not rated Product 2 and Product 6 yet, so to choose one among the two - one way would be to take an average of these products across the entire user base and recommend the one with a higher score.
But there is a caveat - what if the two products, on average, have similar scores, then how to break the tie? Another concern is that the average score across all the users does not give more weight to the subset of users similar to the user in question, i.e., User 2.
That brings us to the next topic - how to generate personalized recommendations.
Personalized Recommendations
We need to find out which user (or users in a significant subset) is most similar to User 2.
Let's divide the matrix into two halves - one each for User 2, as shown below:
1. User 2 and User 1
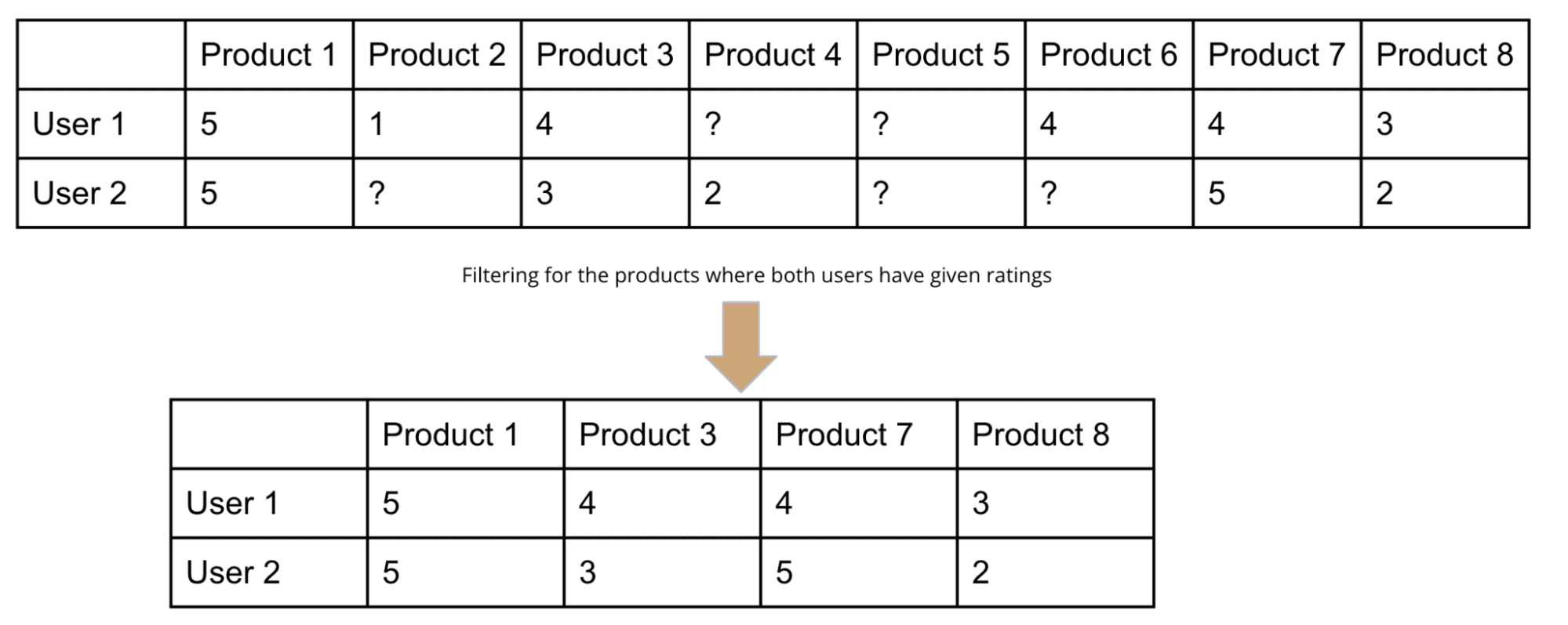
Source: Author
2. User 2 and User 3
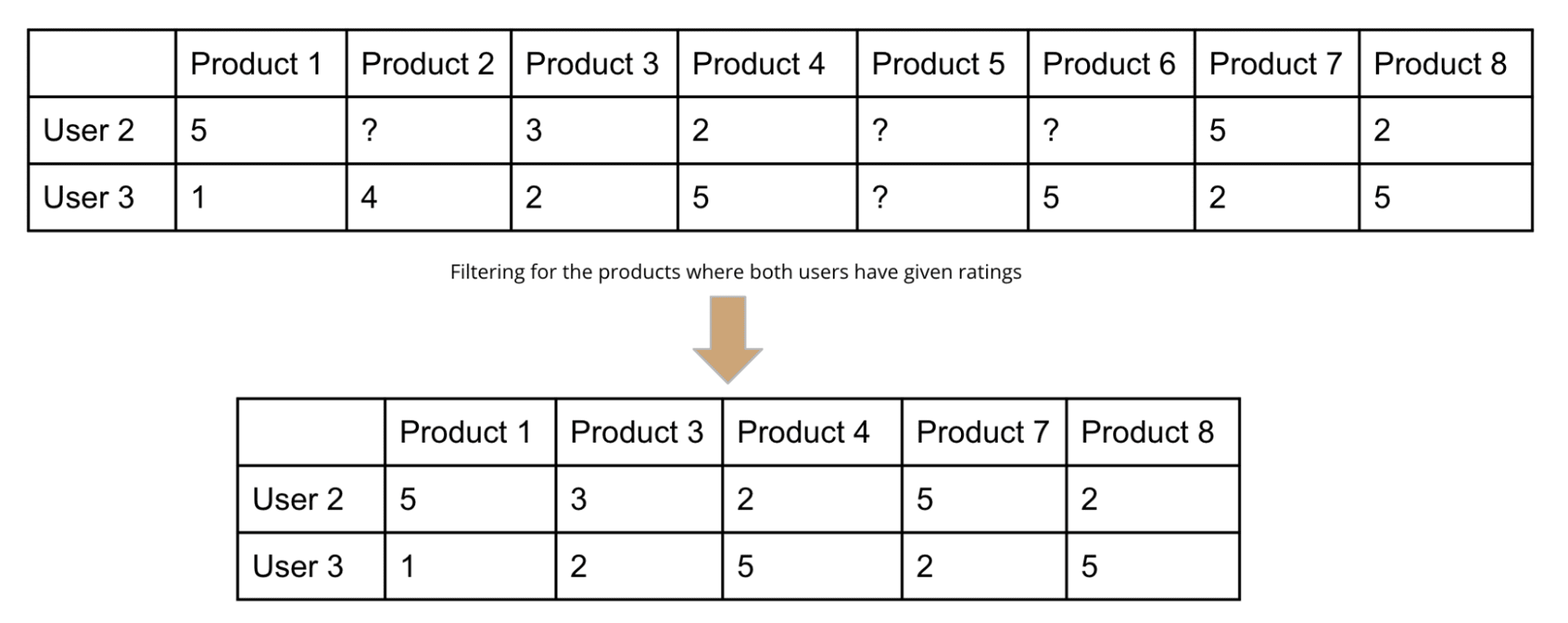
Source: Author
Similarity Score
Based on the two subsets, you can observe that User 1 and User 2 have similar preferences, while User 2 and User 3 do not agree.
Let’s derive a mathematical metric to arrive at a single measure that can define the degree of similarity - one such metric is cosine similarity.
Cosine similarity is define as the:
“similarity between two vectors of an inner product space. It is measured by the cosine of the angle between two vectors and determines whether two vectors are pointing in roughly the same direction. It is often used to measure document similarity in text analysis”
It is represented using a dot product for two vectors A and B
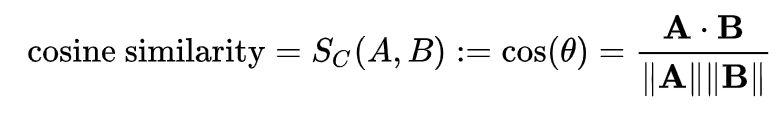
Using the above formula to find similarity of “User 1 with User 2”, and “User 2 with User 3”, we calculate the similarity score, S₁₂, and S₂₃ as 0.97 and 0.65, which resonates with our intuitive understanding.
The last step is to take a weighted average of user ratings with similarity scores S?? and S?? for product 2.
(0.97 * 1 + 0.65 * 4) / (0.97 + 0.65) = 2.35
Similarly, we calculate the weight score for product 6, and the higher score of the two products, i.e., product 6 gets recommended to the user 2.
(0.97 * 4 + 0.65 * 5) / (0.97 + 0.65) = 4.4
Summary
The post explains the intuitive understanding of one of the most popular ways to make product recommendations through collaborative filtering. It elaborates on how users who have searched for similar products in the past influence the recommendations suited for the new user.
The post also illustrates how to calculate the user-user similarity score using cosine similarity and eventually calculates the final score by taking the weighted sum of each product score. Now that you have learned the basics of collaborative filtering, I would suggest reading a six-part series on recommender systems excellently explained by Andrew Ng.
References
Vidhi Chugh is an award-winning AI/ML innovation leader and an AI Ethicist. She works at the intersection of data science, product, and research to deliver business value and insights. She is an advocate for data-centric science and a leading expert in data governance with a vision to build trustworthy AI solutions.